In-Depth
High Availability: Past, Present and Future
To understand what HA solutions best fit your environment, you need to understand their history and how they've evolved.
- By Dan Kusnetzky
- 06/25/2015
High Availability (HA) is a topic with a great deal of history. Different approaches have been used over time to make sure applications, services, databases, networks, and storage remain available and reliable to support enterprises. As enterprises have grown increasingly reliant on information technology-based solutions, the need for these solutions to always be available has increased as well.
Most HA solutions rely on redundant hardware and special-purpose software designed to make the best use of that hardware. Virtualization and cloud computing are upending earlier approaches to HA. Organizations have learned that the use of virtualized access, applications, processing, network and storage makes the creation of HA solutions easier. They've also learned that virtualization makes it easier to use off-site cloud hosting as part of an HA solution.
HA solutions can be expensive, though, and an enterprise's portfolio of IT solutions might not need the same level of availability. Business-critical functions are likely to need the highest levels of availability, while the requirements for business support functions are not likely to be as high.
Enterprises would be wise to understand all of the following approaches to HA, and make the proper choice for each of their workloads.
A Brief History of HA
When applications were more monolithic back in the 1960s through the 1990s, the UI, application logic, storage management, data management and networking functions were all hosted together on a single system. Back then, the industry focus was on making the systems themselves "fault tolerant."
This was accomplished by designing mainframe systems that used multiple processors, stacks of memory, storage adapters and network adapters; they included system firmware that monitored the health of individual components and moved workloads to surviving components in case a component failed or became unresponsive. IBM Corp. used "Parallel Sysplex," a special marketing catchphrase to describe these systems.
Parallel Sysplex failover took only a few microseconds or milliseconds. People using these workloads were usually unaware that a failure took place at all. These systems were extremely expensive when compared to standard off-the-shelf configurations, and were only used to host the most critical workloads.
IBM continues to make continuous processing mainframe configurations available today.
Suppliers such as DEC (now part of Hewlett-Packard Co.), Stratus Technologies (now owned by Siris Capital Group) and Tandem Computers developed similar technology in a smaller form factor -- the minicomputer. IBM resold Stratus computers using the System/88 name.
As with the mainframe continuous processing systems, these systems were composed of redundant components and special-purpose firmware that detected failures and rapidly moved workloads so they could continue processing.
Failovers typically would only require milliseconds, and the users of these workloads were left unaware that a failure happened.
Because these systems were also quite expensive when compared to the off-the-shelf minicomputer competitors, they were only adopted to support the most critical workloads.
HP Integrity and Stratus ftServer systems are available today to address these business requirements.
Clustering
Suppliers hoping to address requirements for performance, reliability and availability worked to create more software-oriented solutions.
Rather than focusing on special-purpose hardware and firmware, these companies focused on special clustering and workload management software. The software orchestrated the use of either off-the-shelf networking solutions or special-purpose clustering networks.
Although clustered systems are likely to have been created by researchers as early as the 1960s, the first commercial offerings were the Datapoint ARCnet in 1977, which wasn't a commercial success, and the DEC VAXcluster in 1984, which was an overwhelming success and is still in use in many enterprises today.
These hardware configurations were used in a number of different ways. Each had a different goal and could be considered the earliest use of access, application, processing, networking and storage virtualization.
Customers deploy clusters, like those in Figure 1, to address the requirements for raw processing power, access availability, application availability, database availability, processing availability and even storage availability.
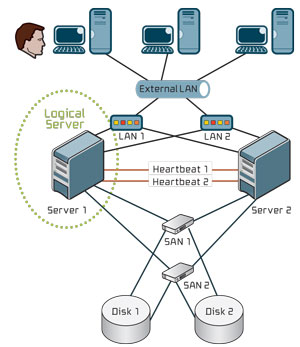 [Click on image for larger view.]
Figure 1. A typical two-node High-Availability cluster.
[Click on image for larger view.]
Figure 1. A typical two-node High-Availability cluster.
Different layers of virtualization technology are deployed, depending on the goals of the enterprise. Kusnetzky Group LLC has divided this virtual cake into seven layers, which you can read about at VirtualizationReview.com/7LayerModel.
Access Clusters
In access clusters, the basic cluster hardware configuration is used to make entire application systems available by using what is now thought of as "access virtualization" technology. Applications are installed on several cluster nodes, and if the node supporting the work of one group of users begins to fail, workload access is shifted from the failing system to one of the surviving cluster nodes.
While this appears similar to an application cluster, the failover and workload management is being done at the access level rather than the application level. Applications aren't aware of this technology and don't need special APIs or to be specially architected for this failover to occur.
This type of cluster relies upon data being housed on a separate part of the cluster devoted to storage access, on the storage services of another cluster, or on a storage-area network (SAN) so that data remains available even if the systems hosting the applications themselves failed.
Because access virtualization is the main virtualization technology in this type of cluster, application and storage hosts might be housed in the same or different datacenters.
Suppliers such as Citrix Systems Inc., Microsoft and VMware Inc. supply this type of technology.
Application Clusters
In application clusters, the basic cluster hardware configuration is used to make applications or application components available by using what is now thought of as "application virtualization" technology.
Application virtualization technology is used to encapsulate applications or their underlying components. The application virtualization technology controls access to these virtualized components. As users request the use of these applications, the workload management portion of this technology reviews the available processing capacity of the systems it's monitoring, selects a system to execute the application based on policies and the availability of processing capacity, and then starts up the application or sends the user's requests to an already-running application instance.
If an underlying system is failing, the user's workloads are automatically moved to another system in the cluster, or connected to workloads already running on another system.
While this appears similar to an access cluster, the failover and workload management is done at the application-component level. Applications must be architected to work with the application virtualization's workload management tool to enable workload monitoring, management and migration. So, unlike access clusters, the applications are extremely aware of this technology and must use special APIs or be specially architected for failover to occur.
This type of cluster relies on data being housed on a separate part of the cluster devoted to storage access, or on a SAN so that it remains available even if the systems hosting the applications themselves fail. Access virtualization technology is often utilized, as well, so user access can be easily and automatically migrated from the failing systems to the new systems.
Application virtualization is the main virtualization technology in this type of cluster; storage hosts could be housed in the same or different datacenters.
Suppliers such as AppZero, Citrix, Microsoft, Novell Inc. and VMware offer application virtualization products today.
Processing Clusters
In processing clusters, the basic cluster hardware configuration is used to make entire system images available by using clustering managers, a form of "processing virtualization" technology.
Applications or their components are architected to access a cluster manager, and the cluster manager monitors the application and either restarts the application on another system or moves the working application to another system, depending on the type of failure. Workload management and migration are managed at a low level inside the OS.
As with the other types of clusters, this approach relies on data being housed on a separate part of the cluster devoted to storage access or on a SAN, so that it remains available even if the systems hosting the applications themselves fail. Also, access virtualization technology is utilized so user access can be easily migrated from the failing systems to the new systems automatically.
In this case, a form of processing virtualization -- cluster and workload management -- is the main virtualization technology in this type of cluster. Storage hosts can be housed in the same or different datacenters.
Suppliers such as Citrix, Microsoft and VMware offer this type of processing virtualization today.
Database and Storage Clusters
Another use of the traditional cluster configuration is to support parallel- or grid-oriented databases or storage. The cluster manager's ability to support specially architected database technology, such as Oracle RAC or IBM PureScale DB/2, are typically database offerings designed for this type of configuration. While it does enhance database availability, the primary goals are database performance or scalability. New NoSQL databases, such as those offered by Couchbase, FoundationDB and MongoDB, are also designed to support large-scale clusters.
Special-purpose SANs are also built using this type of technology. Often, general-purpose systems access data stored in this system over a special-purpose, high-speed SAN.
Virtual Machine Software Emerges
A couple of processing virtualization technologies, virtual machine (VM) software and OS virtualization and partitioning, have emerged as the focus of today's HA strategies. Entire systems are encapsulated and workload monitoring and management combined with system image migration technology are replacing previous forms of clusters.
Applications running in these system images don't need to be written to use cluster APIs. If a virtual system appears to be in trouble due to a hardware failure, the entire virtual system can be moved to another host. This is a significantly simpler approach to HA. Failover can be managed in seconds or minutes.
Continuous processing systems, however, are better hosts for critical functions. Failover in that type of environment can take place in milliseconds or microseconds.
The Design Center Has Changed
The industry is in the final stages of a significant design center migration. In the past, the design center was keeping systems available and reliable through the use of special-purpose hardware and firmware. Now, the design center is using virtualization technology to assure that applications and their underlying components are available.
The new assumption is that hardware, regardless of whether the hardware is a system, network component or storage component, is going to fail; and properly designed software can provide a low-cost, simple-to-use strategy to address that failure.
Once a system image is encapsulated, it can be hosted on a local system, a system in another datacenter or on a system in a cloud services provider's datacenter.
How Much Availability Do You Really Need?
We're now in a world in which enterprises increasingly need their systems to be constantly available, and in a world in which these same enterprises need to do the most with a reduced IT budget and staff.
Enterprises would be well advised to review their portfolio of applications to determine how much availability is necessary for each application, rather than how much is available. Some applications cannot be seen to fail, while it may be OK for other applications to become unavailable from time to time.
Business-critical applications are be best hosted on continuous processing systems. Less-critical applications might be happy executing on a cluster or even out in the cloud somewhere.
My advice is select the HA strategy right for each application, rather than using a "one-size-fits-all" approach.
(Note that this article has been updated to correct an error. Stratus Technologies is not, nor has it ever been, part of HP.)
(Editor's Note: This article is part of a special edition of Virtualization Review Magazine devoted to the changing datacenter. Get the entire issue here.)