In-Depth
VM Component Protection in vSphere 6
This new feature makes outages and data loss much less likely.
Shared storage is the backbone of highly available server virtualization. With it, workloads can be moved freely between hosts, and maintenance is a snap. Without it, an environment is substantially less flexible. In a vSphere environment, there can sometimes be an unfortunate situation where a shared storage target suddenly and unintentionally becomes unavailable.
In previous versions of vSphere (5.0 and earlier), this situation wasn't handled as gracefully as on would hope. vSphere 5.1 made improvements in how the loss was handled to make it less catastrophic, and 5.5 improved some more. But in vSphere 6, VMware introduced a great and long-anticipated feature that protects from the extended outages that plagued previous versions. This feature is called VM Component Protection, or VMCP.
What is it that VMCP is protecting against, and what was so bad before the feature was introduced? There are actually two potential failures: a PDL condition and an ADP condition. These affect ESXi and the virtual machines (VMs) in different ways.
Permanent Device Loss
The lesser of two evils, a Permanent Device Loss (PDL) condition occurs when a storage target is unexpectedly removed from a host, but the host is told about it. The storage array sends what's called a SCSI sense code (
here's a list of the codes) to the host telling it that the LUN has failed, and that it can assume that it's no longer accessible.
This condition is problematic, to be sure, but it's less of a problem than APD because it's more definite. Knowing the determinate status of the situation allows a host to act accordingly. In the case of a PDL condition, the host stops issuing I/O to the target because it knows it's inaccessible.
All-Paths-Down
All-Paths-Down (APD), on the other hand, is a very undesirable condition. This occurs when a storage target becomes inaccessible to a host, with no notification and no ability to contact the storage array. The precarious situation this leaves the host in is that it doesn't know whether the device loss is permanent (due to the LUN being failed/destroyed, zoning changes and so on) or whether it's temporary (due to a momentary network outage, a configuration error that will take 10 seconds to revert and so on). Improperly removing storage that's being decommissioned can inadvertently cause an APD, so be sure to reference
the VMware Knowledge Base article on how to properly remove storage.
Because there's potential for the device to become accessible again, ESXi continues retrying I/O operations. This is in contrast to PDL, where it gives up right away. Due to the continued unsuccessful I/O, especially from userworld processes like hostd, the ESXi host can eventually become unresponsive and unmanageable.
There's generally no resolution but to reboot the host. Because of this high potential for outages, properly handling APD conditions so this doesn't happen has been on VMware's to-do list, and with vSphere 6 they finally did it.
VM Component Protection
VM Component Protection (VMCP) is a marketing-friendly way of saying that you can now configure the response to PDL and APD conditions as it relates to VMs directly from the High Availability (HA) configuration screen.
When configuring the HA settings on a cluster object, there's a new section called "Host Hardware Monitoring – VM Component Protection" (Figure 1). Under this heading, the user has the option to configure unique responses to both PDL and APD conditions, as well as configure the timer for ADP, which ensures that a temporary network blip doesn't initiate a massive HA failover. Do note that as with all new features, you can only configure this from the Web client.
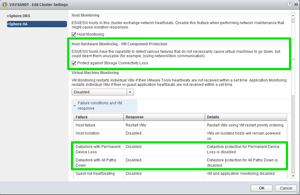 [Click on image for larger view.]
Figure 1. The VM Component Protection screen.
[Click on image for larger view.]
Figure 1. The VM Component Protection screen.
For PDL responses, the following actions can be taken:
- Disabled. No action is taken.
- Issue events. No action is taken, but an alert is shown.
- Power off and restart VMs. Affected VMs will be failed over by HA to a host that has connectivity to the respective datastore.
For APD events, the following actions can be taken:
- Disabled. No action is taken.
- Issue events. No action is taken, but an alert is shown.
- Power off and restart VMs (conservative). HA slave nodes will communicate with the master in an attempt to find a host where machine could be powered on and run successfully. Only when a healthy host is identified will an HA failover take place.
- Power off and restart VMs (aggressive). HA slave nodes will attempt to communicate with the HA master to find a suitable location to fail over VMs to. If communication with the master node isn't possible, HA will attempt the failover anyway. This carries the risk of not being able to power VMs back on, but is desirable in a network partition condition where a suitable host does exist but the HA slave can't communicate with the master.
The timer for action after an APD status is detected can be configured, along with the action taken when the timer expires. The action can be set to either Disabled or Reset VMs, which would cause HA to hard reset all VMs, but on the same host they were already running on.
By leveraging VMCP, which is not turned on by default and must be configured, a vSphere cluster can provide higher levels of availability to applications than ever before.
About the Author
vExpert James Green has roughly a decade of experience as an IT administrator, architect and consultant in a variety of organizations. He's highly certified, and continues to purse professional certifications to increase his breadth and depth of knowledge. He has always been passionate about writing and speaking, and discussing the marriage of cutting-edge technology and business is one of his favorite activities. He works for ActualTech Media, www.actualtech.io.