Q&A
How to Use OpenAI in Azure Cloud to Unlock Organizational Data Insights
OpenAI's ChatGPT might have captivated the public's attention by writing clever poems, but the big promise of AI on the corporate side is increasing the bottom line.
To do that, advanced AI systems need to safely access and process organizational data, which opens up all kinds of concerns. Luckily for those AI adventurers in the Microsoft-centric cloudspace, the company has a set of tools, systems and practices to make it all work on its Azure platform
"What if I told you that we could take data from your database, feed it to an OpenAI model and have it give us insights about that data?" asks Microsft's Bradley Ball." He is a Sr. Azure Engineer for the Azure FastTrack CXP PG at Microsoft and uses his knowledge of data platforms to help onboard customers to Azure while working with Product Groups to refine Azure's Data Services.
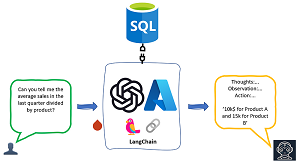 [Click on image for larger view.] AI Insights in the Cloud (source: Microsoft).
[Click on image for larger view.] AI Insights in the Cloud (source: Microsoft).
He also shares his advanced AI knowledge at developer/IT conferences, and he'll be doing just that at next month's big Live! 360 event in Orlando in a session titled, "Use OpenAI, Azure SQL, Python, LangChain, & VS Code to UNLOCK INSIGHTS About YOUR Data!"
"We will start with demo movie data, but then we will move to other data sources," he said about the 75-minute introductory/intermediate-level session at Live! 360, a big umbrella event including Artificial Intelligence Live!. "What if we load a DMV, a useful Community script, or a custom-built table to log useful information? Let's find out together."
Ball promises attendees will learn:
- How to consume data from a SQL Source using Python and Pandas
- How to provision an Azure OpenAI model and interact with it via LangChain
- How to gather insights from data sources
We recently caught up with Ball to learn more about his presentation in a short Q&A.
VirtualizationCloudReview: What inspired you to present a session on using advanced AI to unlock insights from organizational data?
Ball: At Microsoft we are curious. Curiosity pushes to never be content with the status quo. To keep moving forward, learning, engaging, looking for new and better ways to do things.
Drawing from your experience as a DBA and consultant, what are some of the unique challenges or patterns you've noticed that could benefit from this AI-driven analysis approach?
AI is a tool. We are all familiar with the concept of a toolbox. In your toolbox you have a lot of different tools. This tool is new. You will often hear people describe this as "we are building the plane as we are flying it." This is true for many different ways of life, not just the technology field. The Writers & Actors strike in Hollywood was related to how AI will shape the entertainment industry. Netflix just created a position for a Prompt Engineer that had a salary north of $900K per year. Everyone is using OpenAI to craft emails, recommendation letters, and answer questions.
But all of this comes back to one key item: data. AI is trained on data, it provides data, and in the case of Internet Aware models consumes new data. As a long time DBA what do we do? Manage, optimize, build HA/BC/DR architectures for data. We can use this to help us extract insights, enrich existing, or summarize data. But it is a tool. And sometimes that tool is the wrong tool for the job. I can't hammer with a screw driver, I can't use a crowbar when I need a wrench. We must recognize the limitations of our tools, and understand how to use them.
 "Everyone in the world is trying to figure out how to use this. Understanding what we can and cannot do with these services is the difference between wasting a customer's time, money, and future work or accurately representing, delivering value, and getting additional work."
"Everyone in the world is trying to figure out how to use this. Understanding what we can and cannot do with these services is the difference between wasting a customer's time, money, and future work or accurately representing, delivering value, and getting additional work."
Bradley Ball, Sr. Azure Engineer for the Azure FastTrack CXP PG at Microsoft
From a consultant point of view, everyone in the world is trying to figure out how to use this. Understanding what we can and cannot do with these services is the difference between wasting a customer's time, money, and future work or accurately representing, delivering value, and getting additional work.
Your session mentions starting with demo movie data and then moving to other data sources. Can you give us a sneak peek into the variety of data sources you'll be using and the kinds of insights you aim to extract?
We start with movie data, because it's fun but, it is not formatted correctly. We need to understand the importance of core concepts we recognize in the data world that a data scientist or layman working with an AI large language model (LLM) may not understand. We move to using the Semantic Kernel where we can use OpenAI to summarize documents, but structure the Prompt Engineering portion of the code takes center stage (I may also sneak in a peak to Microsoft Fabric at this point). Finally we will look at the data that DMV's return and Community scripts and how we can use AI LLMs to evaluate their findings.
As developers or DBAs, what skills or tools should one be familiar with to get the most out of this session, and how can they prepare to make their own data AI-ready?
In this session I'm going to go into my Azure OpenAI and provision a model. We must have the model in order to have it interpret our data. My goal is to show a few different ways we can interact with this technology. Visual Studio Code and Python or Microsoft Fabric. Microsoft Fabric's Notebooks do not require a Lakehouse or Data Warehouse to run. You can use pip to install packages, and it is an incredibly stable environment for data scientist to use. You can use Beautiful Soup to scrape data, pyodbc to create database connections, or interact with an Azure OpenAI model using LLMs.
All of this will also work in VS Code. Fabric is the first online platform from Microsoft that is just as good as VS Code for executing Python. I'm not sure if the audience is aware of this and I'm looking forward to polling them to see if they like it!
For those unfamiliar, can you briefly explain what LangChain is and how it fits into your presentation?
LangChain is a package that has been around longer than the Semantic Kernel. It allows you to chain together questions to a LangChain Agent that can build off one another. It can be called by Python or JavaScript, and is a good interactive way to engage with users and LLMs. We will talk a little about the differences between LangChain and the Sematic Kernel; they have different use cases and different ways of interacting with the same Azure OpenAI model.
Many DBAs might be wary of introducing AI to their database due to potential complexities or security concerns. How does your methodology ensure the safety and integrity of the data being analyzed?
GREAT QUESTION! The great thing about this is the security context between the processing model and the output is very secure. To access the data we do not do this directly on the SQL Server. We read out a table or query as a data frame. We pass that data frame to the LLM. The data is not stored in the LLM; we receive the output as a data frame and we can use the output as we see fit.
Note: Those wishing to attend the conference can save hundreds of dollars by registering early, according to the event's pricing page. "Save up to $300 if you register by Oct. 20," said the organizer of the event, which is presented by the parent company of Virtualization & Cloud Review.
About the Author
David Ramel is an editor and writer at Converge 360.