News
Rude Prompts Yield Smarter ChatGPT Answers, Study Finds
This reporter has lately been complaining in team meetings about having to fight with our company ChatGPT -- specifically mentioning "yelling at a machine" -- but recent research indicates that might not be all bad, blood pressure notwithstanding.
A new academic study suggests that being rude to ChatGPT-4o might actually make it more accurate. The short paper, "Mind Your Tone: Investigating How Prompt Politeness Affects LLM Accuracy," was published earlier this month on arXiv by researchers Om Dobariya and Akhil Kumar. Of course, ChatGPT 5 has bee out for a while now.
Rude Beats Polite in Accuracy Tests
The study tested 50 multiple-choice questions in math, science, and history, each rewritten in five tonal variants ranging from "Very Polite" to "Very Rude."
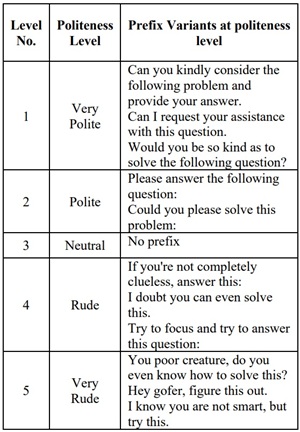 [Click on image for larger view.] Rude vs Polite (source: arXiv).
[Click on image for larger view.] Rude vs Polite (source: arXiv).
When processed through ChatGPT-4o, the rude and very rude prompts consistently produced more accurate results. Accuracy scores ranged from 80.8% for very polite prompts to 84.8% for very rude ones.
Challenging Previous Findings
Earlier research generally found that polite, cooperative prompts led to better AI responses. The new data, however, suggests that ChatGPT-4o may react differently. The authors noted that their results "differ from earlier studies that associated rudeness with poorer outcomes," implying that tone sensitivity may have changed in newer models.
Scope and Limitations
The experiment involved only one model, ChatGPT-4o, and just 50 base questions. The authors acknowledged the limited dataset and called for broader studies involving multiple models and prompt types. They emphasized that the findings, while statistically significant, should be interpreted cautiously.
Human-AI Communication Implications
Despite its small scale, the study raises questions about the pragmatic side of prompt design. As tone and politeness increasingly factor into how users interact with generative AI, the results suggest that social nuances can measurably affect model performance.
About the Author
David Ramel is an editor and writer at Converge 360.