News
Google Is Extending Analytics Reach of BigQuery to AWS, Azure
Users of Google's BigQuery data warehouse will soon be able to conduct Big Data analytics on data stores housed in multiple public clouds.
The Google Cloud Platform (GCP) this week announced BigQuery Omni, a multi-cloud analytics solution that will work with data stored in the GCP, Amazon Web Services (AWS) and Microsoft Azure.
Currently, users of the BigQuery data warehouse can only work on data stored in the GCP.
Google said the new functionality is enabled by BigQuery's separation of compute and storage.
"By decoupling these two, BigQuery provides scalable storage that can reside in Google Cloud or other public clouds, and stateless resilient compute that executes standard SQL queries," Google said in a July 14 blog post.
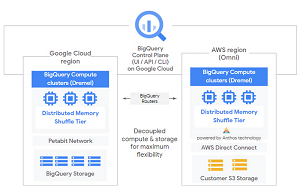 [Click on image for larger view.] BigQuery Omni (source: Google).
[Click on image for larger view.] BigQuery Omni (source: Google).
"Data is one of the most important assets for driving digital transformation, but is often siloed across on-premises machines, proprietary systems, or multiple clouds," Google said in a news release. "Powered by Google Cloud's Anthos, BigQuery Omni will allow customers to seamlessly connect directly to their data across Google Cloud, AWS and Azure for analysis without having to move or copy datasets. Through a single user interface, customers will be able to analyze data in the region where it is stored, providing a unified analytics experience."
Anthos is a hybrid and multi-cloud application platform that helps users build, deploy and manage applications and, in this new solution, connects the GCP and other public clouds. Google also says Anthos can "modernize existing applications running on virtual machines while deploying cloud-native apps on containers in an increasingly hybrid and multi-cloud world."
It's that increasingly multi-cloud world that prompted the creation of BigQuery Omni, with the company citing survey research from Gartner indicating 80 percent of public cloud users were using more than one provider.
BigQuery Omni works with:
- Avro: a row-oriented remote procedure call and data serialization framework developed within the Apache Hadoop project
- CSV: comma-separated values files
- JSON: JavaScript Object Notation, an open standard file format and data interchange format
- ORC: high-performance columnar storage for Hadoop
- Parquet: a column-oriented data storage format that's part of the Hadoop ecosystem
The new solution is in the private alpha stage, working now only with AWS, while Microsoft Azure support is on tap. Organizations wishing to try it out can apply here.
About the Author
David Ramel is an editor and writer at Converge 360.