News
Cloud Giants Race to Provide Same-Day Llama 4 AI Model Support
The cloud giants have been outdoing one another in the race to offer the latest/greatest AI tech, marked by foundation models of ever-increasing capabilities. For the new Llama 4 "herd" of models from Meta, the Amazon Web Services (AWS), Microsoft Azure and Google Cloud hyperscalers all announced same-day support.
Meta just last week announced the natively multimodal AI family. Key characteristics include integrated text and image processing and a design focused on enhanced real-world understanding across diverse data, in line with the shift toward AI with inherent cross-modal reasoning capabilities.
AWS, Microsoft and Google were quick to publish same-day -- a Saturday, no less -- announcements of support for Llama 4 on their clouds, specifically the Scout and Maverick models in the herd, which also includes a Behemoth model that boasts more impressive stats but which is in preview.
 [Click on image for larger view.] The Herd (source: Meta).
[Click on image for larger view.] The Herd (source: Meta).
Llama 4 Scout models are optimized for tasks requiring extremely long context windows (up to 10 million tokens), making them ideal for in-depth document analysis, retrieval-augmented generation (RAG), and complex reasoning. Llama 4 Maverick models, by contrast, are general-purpose, vision-capable multilingual models designed for chatbots, assistants, and image-text understanding, using a Mixture of Experts (MoE) architecture for efficient inference. The key distinction lies in Scout's focus on long-form understanding versus Maverick's multimodal, real-time assistant capabilities.
"We are excited to share the first models in the Llama 4 herd are available today in Azure AI Foundry and Azure Databricks, which enables people to build more personalized multimodal experiences," said Asha Sharma, AI exec at Microsoft. "These models from Meta are designed to seamlessly integrate text and vision tokens into a unified model backbone. This innovative approach allows developers to leverage Llama 4 models in applications that demand vast amounts of unlabeled text, image, and video data, setting a new precedent in AI development."
"Amazon Web Services (AWS) has announced the availability of Meta's new Llama 4 models via Amazon SageMaker JumpStart, with availability as fully managed, serverless models in Amazon Bedrock coming soon," said a staff post. "The first two models in the Llama 4 herd -- Llama 4 Scout 17B and Llama 4 Maverick 17B -- both feature advanced multimodal capabilities (the ability to understand both image and text prompts) and industry-leading context windows (how much information they can process at once) for improved performance and efficiency over previous model versions."
AWS said that instead of using all of its computing power for every question, a Llama 4 model can intelligently choose which "expert" parts of its brain to activate based on the specific task. What's more, the company said, Llama 4 models can deliver more powerful results while using fewer computing resources, making advanced AI more accessible and cost-effective.
Here's how AWS described the differences between the two models it's hosting:
If Llama 4 models were people, Scout would be that detail-oriented research assistant with a photographic memory who can instantly recall information from thousands of documents while working from a tiny desk in a vast library. Scout anticipates informational needs before they're even articulated, providing not just answers, but the context that makes those answers meaningful. Maverick would be the multilingual creative director with an eye for visual storytelling -- equally comfortable drafting compelling narratives, analyzing complex images with precision, or maintaining a consistent brand voice across a wide array of languages in client meetings.
Here's how the company crunched the respective model numbers:
- Llama 4 Scout 17B packs 17 billion active parameters and 109 billion total parameters into a model that delivers state-of-the-art performance for its class, according to Meta.
- Llama 4 Scout 17B also features an industry-leading context window of up to 10 million tokens -- nearly 80 times larger than Llama 3's 128K tokens. Consider this equivalent to the difference between a person being able to absorb information from several pages of a book at once, to an entire encyclopedia.
- Llama 4 Maverick 17B contains 17 billion active parameters and 400 billion total parameters across 128 experts. Think of this as having 128 specialized machines that work together, but only activating the most relevant ones for each task -- making it both powerful and efficient.
Microsoft, meanwhile, characterized Scout models in terms of power and precision, noting Maverick provided innovation at scale. The general-purpose nature of the latter, Microsoft said, made it particularly well-suited for interactive applications, such as:
- Customer support bots that need to understand images users upload.
- AI creative partners that can discuss and generate content in various languages.
- Internal enterprise assistants that can help employees by answering questions and handling rich media input.
Here's how the company depicted those "expert" brain parts mentioned earlier, characterizing the sparse MoE design as an architectural innovation providing efficiency and scale:
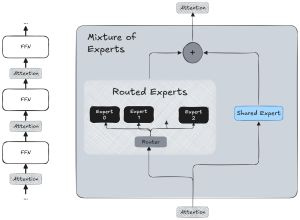 [Click on image for larger view.] Mixture of Experts (source: Microsoft).
[Click on image for larger view.] Mixture of Experts (source: Microsoft).
"To achieve good performance without incurring prohibitive computing expenses, Llama 4 utilizes a sparse Mixture of Experts (MoE) architecture," Sharma said. "Essentially, this means that the model comprises numerous expert sub-models, referred to as 'experts,' with only a small subset active for any given input token. This design not only enhances training efficiency but also improves inference scalability. Consequently, the model can handle more queries simultaneously by distributing the computational load across various experts, enabling deployment in production environments without necessitating large single-instance GPUs. The MoE architecture allows Llama 4 to expand its capacity without escalating costs, offering a significant advantage for enterprise implementations."
Google, meanwhile, announced support for the new models in its Vertex AI Model Garden. It's a comprehensive library within Google Cloud's Vertex AI platform that serves as a central hub for discovering, testing, customizing, and deploying a wide variety of AI and machine learning models and assets. It offers a diverse collection of models from Google, third-party partners (like Meta, Anthropic, and Mistral AI), and the open-source community.
 [Click on image for larger view.] The Llama 4 Model Card (source: Google).
[Click on image for larger view.] The Llama 4 Model Card (source: Google).
A community staff post read: "Today, we're excited to announce that Llama 4, the latest generation of open models from Meta, is available for you to use on Vertex AI! This is a significant leap forward, especially for those of you looking to build more sophisticated and personalized multimodal applications."
Google highlighted the MoE architecture along with another feature.
"Furthermore, Llama 4 utilizes early fusion, a technique that integrates text and vision information right from the initial processing stages within a unified model backbone," Google said. "This joint pre-training with text and image data allows the models to grasp complex, nuanced relationships between modalities more effectively than ever before."
Along with being offered on the AWS, Azure and Google clouds, Llama 4 Scout and Llama 4 Maverick models are also available for download on llama.com and Hugging Face, with Meta noting users can try Meta AI built with Llama 4 in WhatsApp, Messenger, Instagram Direct, and on the Meta.AI website.
About the Author
David Ramel is an editor and writer at Converge 360.