In-Depth
Designing vSphere Environments for High Availability
Of course disaster recovery is important for any datacenter; but it's even better to not have to recover from a disaster.
As much as running an enterprise-class datacenter for the fun of it would be a dream job for some folks, that position doesn't exist, and funding a datacenter with Monopoly money hasn't happened yet. As it turns out, a datacenter is either the support system or the lifeblood of a business. In some cases, the services provided by the datacenter are internal-only and provide messaging services, file storage and host applications. Other times, the datacenter hosts customer-facing workloads like a Software-as-a-Service (SaaS) platform or an E-commerce site. In either example, it's vital to the organization that the datacenter systems stay online and available.
As one of the largest shifts in datacenter architecture in the past decade, virtualization has become the de facto method of provisioning server infrastructure in most enterprises. With the ability to drive efficiency and scale by packing more workloads into the same physical footprint, server virtualization is an economical advantage. With this advantage, however, comes one big risk: By the nature of this architecture, all the proverbial eggs are in one basket.
Bill Laing, corporate vice president of the Server and Cloud Division at Microsoft, famously wrote in a blog post, "The three truths of cloud computing are: hardware fails, software has bugs and people make mistakes." As such, designing a virtualized server infrastructure must take into account these risks to uptime. The system (vSphere, in the case of this article) must be designed with failure in mind.
Because failure is a guarantee, what can be done to minimize the impact on production workloads?
Of course disaster recovery is important for any datacenter; but it's even better to not have to recover from a disaster.
Use a vSphere HA Cluster
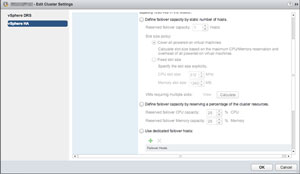
Using a vSphere HA cluster (shown in Figure 1) is paramount to running a production environment on vSphere. Possibly the most important reason to cluster ESXi hosts, High Availability (HA) allows the platform to intelligently restart workloads when a failure has occurred. The impact of this design decision -- HA vs. no HA -- is enormous; HA can be the difference between five minutes of downtime and five hours.
 [Click on image for larger view.]
Figure 1. Creating a vSphere HA cluster.
[Click on image for larger view.]
Figure 1. Creating a vSphere HA cluster.
Host Monitoring
The primary function of HA is to monitor for ESXi host failures in the cluster. If a host fails, either by losing power, experiencing a hardware malfunction, or losing access to network or storage resources, HA will automatically (within about five minutes) begin to re-launch those unavailable virtual machines (VMs) on another host.
Because rebooting VMs due to a small network blip would cause more harm than good, HA has a few mechanisms to verify whether failure has actually occurred.
Isolation Response Address: The first mechanism HA uses for failure verification is called the Isolation Response Address. When a host is participating in an HA cluster, it constantly attempts to ping this address to determine whether it still has network connectivity.
Out of the box, HA uses the default gateway of the management vmkernel interface as the address to test. A VMware Inc. recommended best practice that isn't configured automatically is to set up an alternate isolation response address. In the event that the default gateway of vmk0 is unreachable, HA will continue down the list of up to 10 other addresses to test. The Advanced Option to specify this alternate address is das.isolationaddressX, where X is a number from zero to nine.
Datastore Heartbeating: In conjunction with testing the availability of the Isolation Response Address, HA also uses a mechanism called Datastore Heartbeat to verify whether a failure has occurred. This is less useful in environments where many types of traffic share the same physical networking; but if the storage network is segregated, datastore heartbeats could help show that a host is up despite the isolation address being unreachable. An accidental HA failover would be avoided in this case.
Datastore Heartbeat selects two datastores based on the cluster configuration, and creates a folder on each called .vSphere-HA. The heartbeat files in this folder are updated on a regular basis by each host in the cluster. Capacity utilization isn't a concern, as this folder only consumes around 3MB on VMFS-5.
Admission Control
Because the point of HA is to be able to make VMs available again in the event of a failure, it would make little sense if precautions weren't taken to ensure that resources would be available to start those VMs once a failure occurs.
This is the purpose of Admission Control. In plain terms, Admission Control (when enabled and configured properly) is HA's guarantee that any running VMs in the cluster can be powered on on a surviving host. Without Admission Control, it's the Wild West when it comes to an HA failover, and only the strong survive the chaos.
Admission Control should be enabled and subsequently configured in every production environment. Not doing so is a major risk. Because different levels of resilience are required in different environments, the way Admission Control reserves spare capacity is configurable. The following three Admission Control Policy options are available:
- Host Failures Cluster Tolerates: This is the default option. Interestingly, it's also probably the most misunderstood and incorrectly configured. First, while this setting is the default, it's not good enough as configured out of the box. This policy uses a calculation called "slot size" to determine how many VMs can run on a given host. When tuned properly, this is fairly accurate, but without tuning it's woefully unhelpful. The assumption when an administrator hasn't configured otherwise is that each VM will use 32MHz CPU. In most cases, this is too small a value, and the calculations are skewed to allow more slots than should actually be available. From the Web client, an administrator should edit the cluster settings and manually specify slot size attributes that would accurately reflect the environment.
- Percentage of Cluster Resources: This is a bit easier to understand and calculate than the default policy. Essentially, the percentage specified to be reserved (CPU and Memory can be specified independently) will be withheld from the aggregate of resources in the cluster. The proper setting for this would be the percentage of cluster resources that one host contributes (or a multiple of that). As an example, a cluster containing six hosts should be set to reserve 17 percent, which is just slightly more than one-sixth. If the cluster needed to tolerate two failures, then 34 percent should be reserved (two-sixths).
The benefit of this policy is that it's less complex than the slot size configurations. The drawback, however, is that it isn't dynamic. If a host is added to the cluster and this setting isn't updated, cluster resources won't be properly reserved by Admission Control.
- Specify Failover Hosts: The final policy reserving cluster resources is similar to the idea of a hot spare in a RAID array. A specified host is online and idle, waiting to take over for a host with a failure. While this policy does have use cases, it typically isn't used due to the fact that it's more wasteful. Unless all other hosts will be run up to 100 percent utilization, this policy will actually cost more than a host's worth of resources.
VM Monitoring
VM Monitoring is an underutilized feature of vSphere HA, which is known primarily for handling host failures. VM Monitoring uses VMware Tools heartbeats, and observes network and storage IO to determine whether the guest OS in a VM is available. If a VM doesn't have any network or storage IO for a given period of time, and no heartbeats are being received from VMware Tools, HA can restart the VM. A typical example of this would be the Windows "Blue Screen of Death," in which VM Monitoring would properly diagnose this condition and restart the VM without needing administrator intervention. Although this won't likely fix the underlying issue, it does contribute to application uptime by getting the machine back up and running as quickly as possible.
Avoid Single Points of Failure
All of this HA failover business is assuming that a failure has actually occurred. When designing for vSphere environments, substantial consideration should be given to how failure of individual components can be sustained.
While catastrophic failure of an ESXi host is a possibility, much more likely is that a single network interface controller (NIC) will fail, or an intern will configure the wrong switchport, or a switch in the storage fabric will fail. While HA allows for minimal downtime (VMs begin restarting within five minutes), good resiliency in the physical and logical design will allow for no downtime when a single, redundant component fails.
vSwitch Uplinks
Because many VMs live on one piece of physical equipment, they all depend on the same few physical uplinks to get network traffic to the outside world. If 50 virtual servers all rely on four physical interfaces, a failure here could disrupt many workloads. Avoiding single points of failure in networking components is the key to staying online.
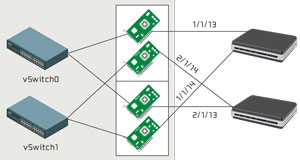
Physical NICs:Having multiple physical interfaces is critical to a successful vSphere implementation; not only for performance reasons, but for ensuring that VM traffic can still flow in the event of a failure on a physical link. An often-overlooked consideration is that although a vSwitch may have two uplinks, if both NICs are on the same PCI card, there's still a single point of failure. It's best when designing the vSwitch configuration to ensure it has uplinks from two different PCI cards, as shown in Figure 2.
 [Click on image for larger view.]
Figure 2. High availability is more likely when a vSwitch connects to two separate network interface controllers.
[Click on image for larger view.]
Figure 2. High availability is more likely when a vSwitch connects to two separate network interface controllers.
Physical Switches: In the same way, if a vSwitch has two uplinks but they both run to the same physical switch, there is a single point of failure. A resilient vSwitch will contain uplinks that run to separate physical switches in a stack, or to separate line cards in a chassis-based switch. Storage Connectivity
On the storage side, considerations are exactly the same. It does little good to provide what looks like multiple paths to a LUN if they actually all terminate in one place. When designing vSphere storage connectivity, be sure to run two completely independent storage fabrics whenever possible.
Physical HBAs: It's quite common for Fibre Channel host bust adapters (FC HBAs) to contain two ports. As mentioned previously, the intention is not to provide extra throughput or to provide redundancy at the port level; it's to provide HA by having one run to each fabric and provide a storage path completely independent of the other.
Develop an Availability/Recovery Strategy
Despite lots of planning and hard work, disasters still happen. Components still fail and people make big enough mistakes that redundancy or HA isn't enough to protect against a failure. For the organization to keep functioning, a plan must be in place to provide capability to roll back changes, recover lost data, and resume business operations from a secondary location. This protection scheme should be multiple layers deep so that the response can be appropriate for the magnitude of the disaster.
Snapshots
A relatively simple but effective way to ensure destructive changes can be rolled back is to regularly perform snapshots. Any modern storage array will have the ability to take a point-in-time copy of metadata and store it for later access.
From a vSphere perspective, this means if machines are modified or corrupted, an admin can recover the working VM from an earlier snapshot in very short order. The ease with which snapshots can quickly correct a derailed situation makes this technology a must.
Backups
Sometimes, being able to recover from a snapshot is either not granular enough or snapshot data doesn't go far enough back in time. For this reason, a backup solution must also be in place. Many an organization has found out the hard way that snapshots are not backups. To be fully protected, the two technologies should be used in tandem.
Replication
Although it's a rare occurrence, site-level disasters also need to be accounted for when the datacenter being online is critical to the business. HA from a site perspective means having a recent (relative to recovery point objective) copy of data off-site at another facility. Depending on the pre-defined recovery time objective, this data may need to be available immediately, or in very short order. Once replicated data can be accessed, systems can be restored at the alternate location and business can resume.
Asynchronous: There are two different modes of replication, and which one is a good fit depends entirely on the criticality of the workload being replicated.
The most common replication mode is called asynchronous, which means that local site operations proceed as normal, and then in the background the changes are replicated to the remote site. This is most common because it's the most attainable from a cost perspective.
The downside is that an asynchronous replication strategy has a "lag time." Depending on the rate of change and the speed of the connection between sites, this lag time can mean seconds' to hours' worth of data lost in the event of a disaster at the local site.
Synchronous: The preferred mode of replication is much more expensive, due to the components needed to make it possible. Synchronous replication actively writes changes to both the local and the remote systems. This means there's effectively no loss of data in the event of a disaster at the local site.
As ideal as this sounds, it's quite complicated to deploy and manage, and is only worth the cost to larger organizations. In many cases, implementing a system that includes synchronous array replication would cost much more than the cost of an outage.
The 3-Step HA Plan
Designing a vSphere environment for HA is no easy task, but these three steps will make a huge difference:
1) Make use of vSphere HA. This is one of the primary purposes for clustering ESXi in the first place. Take care to tune the HA settings to be appropriate for the situation; remember the default settings aren't good enough.
2) When developing a vSphere design, carefully avoid single points of failure. Be sure to consider every component, and whether that component is actually made up of smaller components. Try to add redundancy at the most granular level possible.
3) Last, develop an availability and recovery plan that makes handling a failure possible, and make sure the strategy has multiple layers. Different recovery layers should be able to address different magnitudes of failure. Remember Bill Laing's truths: hardware fails, software has bugs and people make mistakes. Plan for them!
(
Editor's Note: This article is part of a special edition of Virtualization Review Magazine
devoted to the changing datacenter. Get the entire issue here.)