News
Remember When Kubernetes Was Just a Container Orchestration Platform?
Remember when Kubernetes was just a container orchestration platform? That seemingly niche use case somehow propelled it into one of the fastest-growing and most popular open source software projects in history. Now its functionality has expanded to the point it handles just about everything in our new, modern, cloud-native computing cloudscape.
The open source project's host, the Cloud Native Computing Foundation (CNCF), reported that "Kubernetes is one of the fastest growing open source software projects in history" back in 2019 when the organization still called it a "widely used container orchestration platform."
Since then its reach has grown to the point it has been called everything from "the operating system for the Cloud" to "the foundation of distributed infrastructures."
The project's growth and evolution are illustrated in new research that shows it has overcome one of its early deficiencies: support for stateful, data-centric workloads. That means data-driven applications where data persists even when they are closed and started back up, unlike the early days of containers. Red Hat provides this definition of stateful workloads: "Conventionally we define as stateful workloads all those pieces of software or applications that in some way manage a state. Typically state is managed in storage and middleware software such as software-defined storage, databases, message queue and stream systems, key value stores, caches etc."
A post published early this year by WekaIO about "Stateless vs. Stateful Kubernetes" provides another take: "Stateful applications typically involve some database, such as Cassandra, MongoDB, or MySQL and processes a read and/or write to it. Typically, it will involve requests being processed based on the information provided. The prior request history impacts the current state; hence, the server must access and hold onto state information generated during the processing of the earlier request, which is why it is called stateful."
So how far has Kubernetes advanced on the stateful front?
"Stateful workloads on Kubernetes are pervasive and the most advanced users are seeing massive productivity gains," says Data on Kubernetes Community (DoKC), an open group founded in June 2020 with the goal of bringing practitioners together to solve the challenges of working with data on Kubernetes. That statement came in an Oct. 7 news release announcing a new survey-based report titled "Data on Kubernetes 2021." The organization engaged a research firm to survey more than 500 Kubernetes users in order to understand the types and volume of data workloads being deployed in Kubernetes, along with benefits and challenges, and factors driving further adoption.
"While Kubernetes was initially designed for stateless workloads, the community has made major strides in supporting stateful workloads," DoKC said in announcing the new report. "What we found is that Kubernetes has become a core part of IT -- half of the respondents are running 50 percent or more of their production workloads on it, and they're very satisfied and more productive as a result. The most advanced users report 2x or greater productivity gains."
And that even applies to database-driven applications and other stateful workloads.
"While Kubernetes has a strong stateless-centric past, 90 percent of organizations believe it's now ready for stateful workloads and a large majority (70 percent) are running them in production with databases topping the list. Companies report significant benefits to standardization, consistency, and management as key drivers."
To be sure, Kubernetes has had at least some kind of rudimentary stateful workload support since September 2016 when the first inklings were introduced in Kubernetes 1.4: "This release provides easier setup, stateful application support with integrated Helm." That's according to a timeline published by RisingStack.
The company Spot says stateful workloads on Kubernetes really took hold with v1.9 in December 2017. "Kubernetes has been supporting stateful workloads directly since version 1.9 when StatefulSets was made generally available," Spot said in a January 2020 blog post. "Kubernetes users have been asking for support for persistent volumes for a while and it is now mature enough to support stateful applications like databases, big data and AI workloads. Kubernetes support for stateful workloads comes in the form of StatefulSets."
According to the Kubernetes.io web site, "StatefulSets is the workload API object used to manage stateful applications."
Now, nearly four years after the introduction of StatefulSets, the DoKC's report reveals how far support for data-driven, stateful workloads has come.
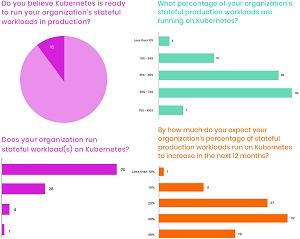 [Click on image for larger view.] Data on Kubernetes Is Widely Adopted (source: Data on Kubernetes Report 2021).
[Click on image for larger view.] Data on Kubernetes Is Widely Adopted (source: Data on Kubernetes Report 2021).
As far as what constitutes those workloads, the report says, "Respondents are running a wide range of stateful workloads on Kubernetes with the Databases in the top spot followed by a three-way tie including Persistent Storage, Streaming/Messaging, and Backup/Archival Storage."
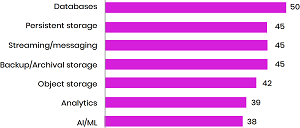 [Click on image for larger view.] Which of the Following Stateful Workloads Does Your Organization Run on Kubernetes? (source: Data on Kubernetes Report 2021).
[Click on image for larger view.] Which of the Following Stateful Workloads Does Your Organization Run on Kubernetes? (source: Data on Kubernetes Report 2021).
While the above graphic is for all respondents, the report also breaks down the same data as it applies to "Kubernetes leaders," defined as the 11 percent of respondents running 75 percent or more of their production workloads on Kubernetes.
"When we look at Kubernetes Leaders, Databases remain in the top spot but become more important -- jumping 11 percent -- while Persistent Storage becomes less important to this group, a reduction of 14 percent compared to all respondents."
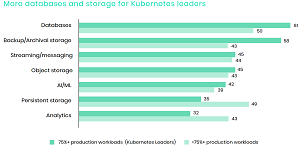 [Click on image for larger view.] Leaders: Which of the Following Stateful Workloads Does Your Organization Run on Kubernetes? (source: Data on Kubernetes Report 2021).
[Click on image for larger view.] Leaders: Which of the Following Stateful Workloads Does Your Organization Run on Kubernetes? (source: Data on Kubernetes Report 2021).
While the above graphics detail the types of workloads being used, that aforementioned WekaIO post also discussed containerized stateful application use cases and their challenges.
"Containerized applications need statefulness, as they are commonly deployed in hybrid and edge-to-core-to-cloud workloads, as well as CI/CD use cases," it said. "Here are some of the common use cases for containerized application deployments:
- Data analytics processing and AI/ML: Hadoop, Spark, Tensorflow, PyTorch, and Kubeflow are now increasingly adopting containers. And need to go over massive amounts of data repeatedly.
- MLOps: There are a number of stateful requirements when using containers for MLOps environments, such as checkpointing for large training jobs and sharing training and inference results.
-
Databases and messaging: Some applications recommend local flash for low latency. Using local flash on the POD's worker nodes will limit the capabilities of moving containers between different worker nodes in the POD for additional agility. That is the reason why a high-performance shared storage ... one that can provide the same or better latency while allowing for shared high performance data, would allow effectively using applications such as these:
- Single-instance databases like MySQL, PostgreSQL, MariaDB
- NoSQL databases like Cassandra and MongoDB
- In-memory databases like Redis and MemSQL and KDB+
- Messaging apps like Kafka
- Business critical apps like Oracle, SQL server, and SAP
The evolution of stateful applications on Kubernetes was also discussed in an August 2020 The New Stack podcast aptly named "The Evolution of Stateful Applications on Kubernetes," which featured Alex Williams, founder and publisher of The New Stack, and guests Tom Phelan, fellow, big data and storage organization, Hewlett Packard Enterprise (HPE), and Joel Baxter, distinguished engineer, HPE.
The guests were involved in furthering stateful applications on Kubernetes, dating back to their days at VMware, and discussed the history of that movement.
"We have things like operators in custom resource definitions, as Joel points out, we took each one of those pieces and we extended it as much as we could to support our stateful applications that we were running on Kubernetes because you mentioned, companies that originally designed from the ground up for stateless cloud-native applications, no one even tried to run a legacy stateful application on Kubernetes for years, right," Phelan said. "I think we're probably one of the first, first real people for him to do that. And so we looked at these tools and he found it was, you could do it, you could do it. So you can do StatefulSets and you can use persistent volume claims and you have your container storage interface for the CSI so you could associate it, but it was tough. It wasn't easy, it was hard."
They also discussed one tool that might make it easier these days, KubeDirector, "The easy way to run complex stateful applications on Kubernetes."
"There are plenty of operators in the open source community with which you can download and run your apps, but when we're talking about enterprises with a collection of hundreds -- if not thousands -- of legacy applications, they want to run on containers," Phelan was quoted as saying in a The New Stack post about the podcast. "They don't have the expertise for each of these applications," said Phelan. "So they are not typically going to be able to write an operator, which is a piece of Go code, that has intimate knowledge of the application and a very good understanding of the Kubernetes API."
The post described KubeDirector as a way to help port often numerous legacy applications to a containerized environment, stating that it helps to fill in the gaps that traditional operators cannot provide when shifting to cloud native.
"KubeDirector is able to process hundreds of YAML files by providing the operator functionality for the corresponding application," the post continued. " 'This means you can have hundreds of these YAML files and, with a single operator and a single instance of the KubeDirector, manage and control all the different types of legacy applications,' said Phelan. 'It's a really powerful tool that makes it very easy to add support for new applications to Kubernetes.' "
Phelan provided more on KubeDirector in a 2018 post on the Kubernetes.io web site, stating these capabilities:
- The ability to run non-cloud native stateful applications on Kubernetes without modifying the code. In other words, it's not necessary to decompose these existing applications to fit a microservices design pattern.
- Native support for preserving application-specific configuration and state.
- An application-agnostic deployment pattern, minimizing the time to onboard new stateful applications to Kubernetes.
Of course, Kubernetes has advanced in many other ways beyond its now-polished support for stateful, data-intensive workloads, to the point that IBM says, "Today, Kubernetes and the broader container ecosystem are maturing into a general-purpose computing platform and ecosystem that rivals -- if not surpasses -- virtual machines (VMs) as the basic building blocks of modern cloud infrastructure and applications."
Growing from a container orchestration platform to a basic building block of the modern cloud -- rivaling VMs -- is a heady trip in itself, but even more is expected.
"The future of IT is going to be about greater interactivity, seamless integrated experiences, predictive analytics, automation, decision making via machine learning, making sense of data exhaust, adding in augmented and virtual reality and a host of other applications we cannot even imagine yet," Red Hat said in a blog post last year. "These applications will run most effectively when they are offered the greatest flexibility and agility. Container-based, cloud-native apps orchestrated by Kubernetes, offers those attributes to become the building blocks of the modern IT infrastructure."
Several challenges to achieving that still remain, though, and one of the foremost is the lack of Kubernetes skill and talent faced by enterprises today, which the DoKC report alluded to.
The skills/talent conundrum is most prevalent among Kubernetes leaders, as the following graphic from the DoCK report shows:
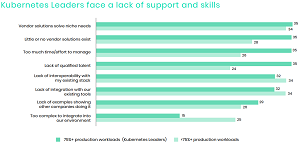 [Click on image for larger view.] Help Wanted (source: Data on Kubernetes Report 2021).
[Click on image for larger view.] Help Wanted (source: Data on Kubernetes Report 2021).
"Kubernetes Leaders face a different set of challenges with a four-way tie for first place: vendor solutions solve niche needs, little or no vendor solutions exist, too much time and effort to manage, and lack of qualified talent," the report said. "The talent gap was the most drastic difference when compared with all respondents, jumping 11 percent."
That certainly jives with a Virtualization & Cloud Review article from this summer, titled "VMware Study: Kubernetes Thrives, But Expertise Is Top Challenge." It said: "In selecting a Kubernetes distribution, lack of internal experience and expertise is still the biggest challenge in making such decisions (reported by 55 percent of respondents), while hard to hire needed expertise is also a notable challenge (37 percent). Lack of internal experience and expertise is also the top challenge in deploying Kubernetes."
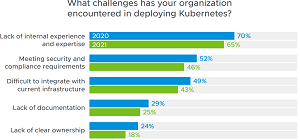 [Click on image for larger view.] Top Challenges (source: VMware).
[Click on image for larger view.] Top Challenges (source: VMware).
With experienced talent hard to find in-house and to hire, it's not surprising that the VMware report showed that managed Kubernetes services are enjoying increased popularity.
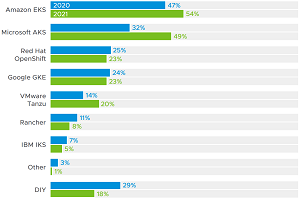 [Click on image for larger view.] Top Offerings (source: VMware).
[Click on image for larger view.] Top Offerings (source: VMware).
But those challenges are likely to be addressed and mitigated as Kubernetes continues to grow and evolve. A $147,732 average annual salary for Kubernetes talent -- topping out at $219,000 -- will certainly lessen the talent/skills gap, for one. Those figures were reported this summer by ZipRecruiter
So what's the final word on the future of Kubernetes? The answer, of course, comes in a comment posted about a year ago to a Quora question that asked just that: "Kubernetes future is bright. Kubernetes will continue to improve and expand upon its functionality, the types of applications it can support, and integrations with the overarching ecosystem. Kubernetes bringing the power of the infrastructure by keeping all the moving parts and dependencies will leverage the continuous growth across various infrastructures keeping them less complex. So Kubernetes should be your next Infrastructure-Management Platform."
Which could serve as a fitting tl;dr.