In-Depth
Front-Line Expert Answers Unstructured Data Sprawl Questions
Unstructured data sprawl happens when organizations accumulate massive amounts of files -- like documents, images, videos, emails, and backups -- across different systems, locations, and users with little organization or oversight. This uncontrolled growth makes it hard to find and manage data, drives up storage costs, slows down backups and recovery, and increases the risk of security breaches and compliance violations. Over time, it clogs up systems and creates chaos, making IT teams work harder just to keep up with what they have.
Those problems increasingly plague organizations trying to enhance their "data culture" and "data-driven" postures. The biggest benefit to this is control, which leads to lower costs, faster access to critical data, and stronger security and compliance. When data is organized, deduplicated, and properly managed, storage becomes more efficient, backup and recovery are faster, and it's easier to protect sensitive information -- saving time, money, and reducing risk across the board.
To help data pros get a handle on unstructured data sprawl, data expert Greg Schulz today helmed an online presentation put on by Virtualization & Cloud Review titled "Managing Unstructured Data: Expert Guide To Solving the 'Data Sprawl' Problem," now available for on-demand viewing.
Greg, a founder and senior advisor at Server StorageIO, an independent IT advisory, consultancy, and creative services firm, presented an hour-long online presentation chock full of information about the top unstructured data problems:
- Copy Management
- Data Protection (Backup/BC/BR/DR)
- Data Leak/Loss Prevention
- Expanding Data Footprint Impact
- Governance & Compliance
- Security & Access Controls
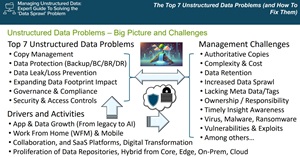 [Click on image for larger view.] Top Unstructured Data Problems (source: Greg Schulz).
[Click on image for larger view.] Top Unstructured Data Problems (source: Greg Schulz).
While all of his expert information is too extensive to present here, he also held a Q&A session at the end where attendees could submit questions about the presentation. To give you a taste of these presentations and the expert advice distilled by our presenters, here's a summary of those audience questions and answers.
Gaining Insight and Discovery of what You Have, Sounds Good, but How Do You Actually Do It?
"Look at what is available on the platform that you're running on. Okay, so whether you're running on Linux, whether you're running on Windows, whatever it happens to be, whether it's on-prem, the edge, whether you're running virtual, hyper-converged, whatever happens to be on the cloud, is look around and what tools are available for doing basic discovery. And when I say discovery, let's be clear that's not classic or traditional compliance type discovery or E discovery. This is the bigger, broader discovery of overall, what you have certainly that would encompass e discovery, things like that. But what do you have? What are your different data that you have out there in file systems, and what are the different databases that you have out there? And as you move up the stack, from infrastructure IasS into PaaS into SaaS, you'll find that there are different tools that are available that can be leveraged, whether you're running it on-prem, out at the edge or in the cloud.
 "So work with your partners to understand, what do they have, what do they recommend, what do they use so that then you're able to leverage those different tools to help figure out how can you get your arms around all this unstructured data. And the vendors should love having that opportunity to have that conversation."
"So work with your partners to understand, what do they have, what do they recommend, what do they use so that then you're able to leverage those different tools to help figure out how can you get your arms around all this unstructured data. And the vendors should love having that opportunity to have that conversation."
Greg Schulz, founder of independent IT analyst firm Server StorageIO
"So work with your partners to understand, what do they have, what do they recommend, what do they use so that then you're able to leverage those different tools to help figure out how can you get your arms around all this unstructured data. And the vendors should love having that opportunity to have that conversation."
How Can Emerging Data Orchestration Tools Automate Unstructured Data Life Cycle Management Without Compromising Rapid Recovery Times or Strict Security Requirements?
"Yeah. So there are several pieces to that, let's unpack them. First is the orchestration layer can be a great place to be able to launch different tools to go out and do this discovery. If you would first off as part of that configuration, if that's being configured through that orchestrator, it should have some knowledge, i.e. that this that that configuration tool, orchestration tool, it should have some knowledge of what has been configured, where for whom, on what system, or in what tenant, or what subscription, what, wherever that happens to be. So that should be a primary ... that could should be a good source of some basic knowledge and assessment. But that also means is that, what about the security implications. Well, how do you go about doing all that? Well, you may need to have an agent or a tool that has the authentication, the authorization to be able to go out and run and collect that information with the applicable rights, but also that tool is managing control so that only those who have access to it can use it and or its results.
"The bigger question that comes into play is, how do you do this across sites? How do you do this across systems? How do you do this across clouds, and how do you do this across things that you don't know about, okay. And that's where coordination across different orchestrations are, having a master orchestrator, if you would, comes into play. So for example, you've seen things like with Microsoft with Windows, or with with Azure, and Azure Arc has that ability to look across the Azure environment, per se, looking at different subscriptions, tenants, groups, things like that, but also the ability to reach out with authentication, with authorization into on-prem or edge type locations to help collect information, to do management, things like that. So the one of the bigger things that I didn't hear in the question but that should come up, is, what is the overhead impact of doing that crawling, of doing that discovery, an ideally it's a balancing act of low overhead. But how frequently do you need. Have that information updated."
How Do You Discover what Unstructured Data You Have when You Don't Know Where It Is?
"That's the classic conundrum, is that, say you've got an individual system, whatever that happens to be, you could certainly find different tools from the different providers that will go out there and help search and discover. You can go out to third-party tools. I mean, things like JAM Software, TreeSize, a lot of different tools that are out there, open source, ones that will go out there, and you say, 'here, I know of the systems. Okay, now go out and tell me about the system.' But then there is. a, 'wait a minute, what about that case where I don't know what systems I have,' all right? Now things can get interesting really quick, which is, you could go crawl the network, looking for these systems, but what security alarms are you going to set off? Now the good news is, you should be setting off some security alarms.
"The bad news is, you're able to go out there and look around and discover and find some different systems -- here's the Linux, there's a Windows, not really sure, well, that looks like a router, and if no security alarms are going off, that's not a good situation. So part of that could be, is coordinating with the relevant teams, those responsible that says, 'hey, you know what I'm going to be doing this crawl. And here are the protocols that are going to be used here, the ports that we're going to be touching, and we'll do it during this time frame. So if you get a bunch of alerts, kind of pay attention to them, but don't be totally alarmed. But you know, you may want to hear will even do it from this particular IP, etc.' That way all the alarms aren't going off. But what about you've got them in locations that are outside of your network? That's where then it becomes a lot trickier. And you need to start thinking about other ways that you could discover, that it could be, who is it that is using these different systems? Who are your users? What else are they using, just more, just reaching out and crawling and discovery."
Were Does AI Fit into All of this and How Does It Work?
Yeah, so look at this from two different standpoints. One, AI is a consumer of, actually, there's more than two parts to this. AI is the consumer of a lot of unstructured data. So it's consuming, whether it's for intended purposes, i.e., it's learning things like learning training. But also is AI being used to simply crawl and look around and discover, okay, so that's the one aspect. Is the AI consuming either in good ways or maybe an unintended ways. There's the other side to it, which is AI is being used to generate the unstructured data, whether it's text, scripts, code, apps, papers, articles, images, whatever it happens to be. So it's generating a lot of that. And as a course of it being generated, is their ability to add tags that tags, that data that says, 'hey, this is something that was generated and, oh, by the way, it was generated via AI. And oh, by the way, it pertains to this particular topic.' Okay.
"Then there is the aspect of AI being used for anomaly detection. So yeah, I certainly can see it being used here. Go out and summarize this article. Go out and summarize this webinar. Go out and summarize this presentation. Go out and summarize this meeting. Okay, things like that. But it can also be used to go out and look and say, 'Hey, what are the anomalies?' What's different about what we're seeing, going through logs, going through telemetry, looking through data, discovering, going granular, but also just going course, to see what's out there. What are the patterns? Who is this particular set of unstructured data, objects, blobs, files? Who are they associated to?
"Okay, let's go look to see who that is. And, oh, by the way, what else are they looking at? Okay, in certain to build graph type data all of a sudden you realize, hey, we just stumbled on a chain of something that may or may not be nefarious that then in talking with. Whoever that is, you find out, yeah, they're working on something that's appropriate. Or you might find out there is nobody by that name in the organization. All right, let's start to see, what can else we infer from that? And you're seeing this occurring right now within the different cloud providers, where they're able to look within their organization and peace this data together and based on prior things happening, to be able to go out and figure things out what's happening. So again, a lot there."
Do You Need Different Tools for Backing Up Unstructured vs Structured Data?
"Great question, and it depends. And it depends on what tool, what vendor you're using. Some vendors specialize in just doing structured data databases. Some work with block and file and databases and have plug-ins, some work with blocks and files and databases and structured unstructured and blobs and objects. It's, in other words, it's, all flexible, agnostic to them what they're they just have that capability. So it really comes back to the different vendors that have those different capabilities, to be able to reach and plug in to different applications, to work with the different types of data, as well as where the data stored and across the different platforms at different layers."
And More
Watch the on-demand replay for expert advice on the major unstructured data problems, along with a presentation from experts from Rubrik, the Zero Trust data security specialist which sponsored this summit. And be sure to continue your IT education efforts in upcoming summits and webcasts, where you can also ask questions of front-line experts and even win a prize (today each of the first 300 attendees received a $5 Starbucks gift card). So with that in mind, here's a selection of those coming up in April.