In-Depth
How Well is High Availability Protecting Your vSphere Environment?
You may not be as safe as you think. This tutorial shows you how to check.
As a consultant, I've spent quite a bit of time in front of vSphere clusters. In the last couple of years, I've spent a chunk of that time assessing the health of an environment, as well as the overall design. A service that proves to be very beneficial to my customers in the long run (and often immediately, as well) is when I review the configuration of the most important settings of ESXi and vCenter and determine if anything needs to change.
Sometimes vSphere infrastructures are designed and deployed by amateurs who have time to spare, but not a lot of experience or training. So they tinker and guess, and eventually they get it close enough to do what they want. In other cases, the environment was designed by an expert at inception, but has since succumbed to the all-too-common operational "rot" that happens after a professional services organization does a deployment and then turns it over to ill-prepared operations staff.
In this article, I'll address how you can check the No. 1 misconfiguration I've found when assessing the health of vSphere clusters in small and mid-size datacenters. In the enterprise, there's generally a proficient integrator/reseller (or VMware engineer) engaged closely enough to make sure these things are in order. But in the less pampered environments, even major misconfigurations can go un-caught until it's too late. In my experience, the most common victim of misunderstanding and ignorance as it relates to vSphere is vSphere High Availability (HA).
HA Misconfigurations
First, a clarification: in this case, I'm referring to the specific vSphere feature known as High Availability. When I use the term HA in this article, I'm referring to this feature, rather than to the generic infrastructure design consideration of providing high availability.
Next, a very quick primer on the purpose of HA. As I say to consulting clients, "HA is one of the primary reasons you buy vSphere in the first place." vSphere HA is the mechanism by which vSphere will recover and restart your running workloads on another host in the event of a node failure in a vSphere cluster.
Put simply, if an ESXi host spontaneously combusts, within roughly five minutes plus the time it takes to boot the virtual machines (VMs), HA will have restarted your running VMs on a surviving host such that they're available again.
This means that if HA were to be improperly configured and not function correctly, availability is at risk. A node failure could potentially result in offline workloads that cannot be restarted due to capacity constraints.
This is not a tutorial on how to properly configure HA; rather, it's a method for testing to see if you're adequately protected by it. To dig deeper and learn about how to actually understand and configure HA for yourself, I highly recommend the aging but ever-relevant work by Duncan Epping and Frank Denneman VMware vSphere 5.1 Clustering Deepdive, as well as the updated 6.x version of the book, which is available to read on Gitbook.
The HA Simulator Tool
I used to use a whiteboard to describe how HA works and help clients understand the potential impact of HA configuration on a failure. While this was an effective tactic, VMware has released a tool in the last year or so that makes the situation much more
real to my clients: the
VMware Resource and Availability Service.
Rather than a hypothetical discussion on what could be at risk due to an improper HA configuration, the service ingests real data from your environment, simulates a host failure, and uses the algorithms and predictable mechanics of HA to show the result. When a CIO sees that the actual, predictable impact of a host failure in his or her environment is a pile of unrecoverable machines causing a widespread outage of production systems, the reality takes on a new level of priority.
A Handful of Caveats
While this is an extremely useful tool for assessing the overall HA health of your environment, there are a few things to note when using it, to be sure that the results are properly understood. Before running a report from the service, consider the following:
- The Distributed Resource Scheduler (DRS) is an important symbiotic feature with HA. Without DRS, HA restarts are likely to overcommit a host, because HA does not natively have the placement and balancing intelligence of DRS. It's important to consider, when using this tool, that the assumption from the simulation's perspective is that both HA and DRS are enabled and configured.
- There's one flaw in the report delivered by the service that may make a situation seem more dire than it really is: the simulation doesn't take into account HA restart priorities. It's been my experience that organizations with improperly configured HA also do not use HA restart priority. However, take into consideration that the service could show a high priority VM not being restarted, while a low priority VM is restarted; in an actual failure, your HA restart priorities would be honored.
- The service supports vSphere 5.0, 5.1, and 5.5. According to the documentation at the time of writing, you won't be able to test 6.x clusters. Hopefully that feature is coming once the service can be validated for 6.x.
- The service uses a snapshot of the configuration and resource usage at a point in time. Although the results can be considered accurate based on that snapshot, actual resource utilization could be different at the time of a real failure. If the evaluation is not done during a peak utilization time and a real failure occurs during such a time, results might not be as favorable. The converse is also true. VMware recommends (for obvious reasons) using data from a period of heavy utilization when conducting this evaluation.
Acquiring the Dump File
Using this service is surprisingly easy. All it takes is grabbing a DRS dump file, uploading it to the service portal, and specifying the failure scenario you'd like to test. I'll begin by showing how to find the dump file to use. This process is a bit tricky the first time you do it, but in reality it takes far longer to explain than it actually takes to do. I suspect that if this service continues to be developed, VMware will make it easier and less labor intensive.
To begin, you'll need the name of the Cluster and the Datacenter object in which the cluster resides. We'll use this to browse the MOB interface for the cluster's MoID (the unique internal ID of the cluster). Use the following steps to get the dump file needed for the simulation:
- Use a Web browser to navigate to https://<vCenter>/mob/moid=group-d1. Be sure to replace <vCenter> with the IP or FQDN of the proper vCenter Server. You'll be prompted to log in using vCenter credentials. Once authenticated, you will get an inventory screen.
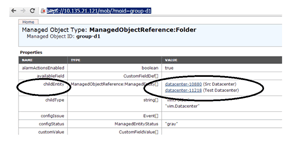
- Select the datacenter value from the "childEntity" field that represents the relevant datacenter object, as seen in Figure 1.
 [Click on image for larger view.]
Figure 1. Selecting the datacenter ID from the MOB inventory.
[Click on image for larger view.]
Figure 1. Selecting the datacenter ID from the MOB inventory.
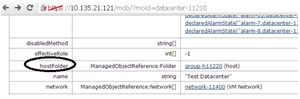
- Scroll down a bit and select the value for the name "hostFolder" as seen in Figure 2. In this case, "group-h11220."
 [Click on image for larger view.]
Figure 2. Selecting the host folder from the MOB inventory.
[Click on image for larger view.]
Figure 2. Selecting the host folder from the MOB inventory.
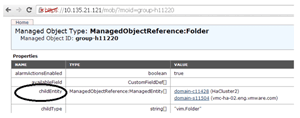
- Record the MoID of the cluster you want to evaluate. If, as in Figure 3, you'd like to run the evaluation service on "HaCluster2," the ID to note would be "domain-c11428." The official documentation notes that this ID will always be in the form: domain-cX, where X is a number.
 [Click on image for larger view.]
Figure 3. The MoID is found in the Value section of the "childEntity" key.
[Click on image for larger view.]
Figure 3. The MoID is found in the Value section of the "childEntity" key.
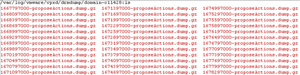
- Armed with the correct MoID, use KB 1021804 to find the location of the logs for the particular version of vSphere being evaluated. This KB article will help you specifically locate a folder called drmdump, which contains the compressed logs of actions both proposed and actually taken by DRS. The service will use your choice of the "proposed" logs to do the evaluation. Navigate into the sub-directory for the cluster in question (remember that this is referenced by the MoID that was obtained), as seen in Figure 4.
 [Click on image for larger view.]
Figure 4. The 'drmdump' directory, containing the dump files used in the evaluation.
[Click on image for larger view.]
Figure 4. The 'drmdump' directory, containing the dump files used in the evaluation.
- Select any "…proposeActions…" file with a timestamp that matches the time range in which you want to simulate a failure. Remember that VMware recommends simulating a failure at the worst possible time, to be sure that you're covered in all scenarios. Copy this file to your local machine for uploading.
Performing the Simulation
This is the fun part. Use the following steps to upload the dump file to the simulator service, configure the failure scenario, and find out whether the cluster is in good or bad shape.
- Navigate to the VM Resource and Availability Service URL at http://hasimulator.vmware.com/
- Click the nice, big "Simulate Now" button, as seen in Figure 5.
 [Click on image for larger view.]
Figure 5. Beginning the HA simulation.
[Click on image for larger view.]
Figure 5. Beginning the HA simulation.
- Drag the DRS dump file you have handy to the pane that slides out to the right, as seen in Figure 6.
 [Click on image for larger view.]
Figure 6. The DRS dump upload pane.
[Click on image for larger view.]
Figure 6. The DRS dump upload pane.
- When the DRS dump file finishes uploading, you'll have an opportunity to select the failure scenario you wish to simulate. The options are to have the simulator pick a host to fail (which eliminates your bias), or tell it which host(s) to fail, which allows you to simulate very specific conditions.
Assessing the Results
As soon as you've completed the previous step and run the simulation, you'll come face to face with reality. That may be a good thing and validate all the hard work you've done; or it may be a not-so-good thing, and highlight work that needs to be done to make the infrastructure that supports your business more reliable.
The resulting report considers VMs which will perform at 60 percent of normal allocations to be "not impacted" by the failure by default. This doesn't mean that there's literally no impact, but that the impact is acceptable given the degraded state of the cluster. Anything performing at below 60 percent of original capacity will be flagged.
The shock value that I look for to show my consulting customers -- and the value that may be helpful in catalyzing change in your organization -- is the red number seen in Figure 7that references VMs that failed to start. This means that in the event of a failure like the one you specified, these VMs will be entirely unavailable to the business until the failure is remedied. In the example, 9 more will also run with less than ideal resource allocations.
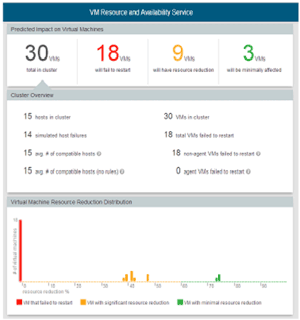 [Click on image for larger view.]
Figure 7. The report from a simulation, showing that 18 VMs failed to start.
Handling the Findings
[Click on image for larger view.]
Figure 7. The report from a simulation, showing that 18 VMs failed to start.
Handling the Findings
If running this simulation resulted in bad news for your environment in the case of a failure, here are some things you may want to consider to remedy the situation:
- Properly reconfigure HA. As I stated at the outset, it is very common to see misconfigured HA settings when I'm consulting. Correctly adjusting the way that HA calculates and reserves resources is crucial to ensuring a proper failover, where all resources continue to be available. The vSphere Availability Guide is sort of like the HA bible, and will help you get HA configured correctly.
- You may simply be low on physical resources. As much as the CFO hates it, you may really need to invest in another server (or five) to add to the vSphere cluster in order to properly sustain a failure.
- You may have DRS affinity/anti-affinity rules configured that severely limit where VMs can run. This can impact restarts in a failure scenario, so carefully review DRS rules to make sure they're needed and as unrestrictive as possible while still meeting requirements.
- VM sprawl is still a major problem in many organizations. If additional hardware isn't an option, perhaps it's time to look at turning off some old VMs that haven't been fully decommissioned, or cleaning up from abandoned R&D projects.
- If none of the above are feasible ways to get to a suitable failover, the "least bad" option is to configure HA restart priorities and VM reservations to protect your most important VMs in the event of failure. At the least, this will make sure that your business critical workloads are restarted and the Minecraft servers are the ones that don't come back after a failure.
The official documentation from VMware on how to use this tool is available here.