In-Depth
3 Common Challenges with Cloud-Based Disaster Recovery
When considering a move to the cloud for your precious data, keep these gotchas in mind.
Backup and disaster recovery (DR) has been a critical part of the datacenter for decades, and that won't be changing anytime soon. No matter what business you're in, there's a pretty good chance that a loss of either uptime or data would be costly to your business.
As a protection against natural disasters, human error, equipment failure and anything else that could go wrong, wise businesses invest in the "insurance" of a DR solution. Historically, that solution has been relatively primitive, yet effective. But in the post-Internet era, with high-speed connections to shuttle data anywhere on the globe, disaster recovery solutions have the potential to be quite extravagant and complex. Due to the cost of downtime in some organizations, the cost and complexity is sometimes justified.
Now, in a day and age where anyone can take a credit card and begin to build out a production-grade application in a world-class datacenter in mere minutes, some businesses are starting to leverage that same flexibility for their DR practices. For the purpose of this article, I'll refer to this practice as "cloud-based DR." Although that theoretically could mean something to do with availability within a private cloud platform, I'm using the term to refer to the use of public cloud resources from a provider like Amazon Web Services Inc. (AWS) or Microsoft Azure to be the "DR site" for a DR plan.
Why Cloud-Based DR?
Traditional DR has been -- in most cases -- mundane but effective. As long as it's maintained and the processes are followed to the letter, DR hasn't been too difficult. But there are a handful of common experiences among organizations that suggest that there's a motive for a new kind of DR:
- Organizational growth and change causes changes to the infrastructure. The backup strategy can be overlooked until it's too late and data is lost.
- The sheer scale of certain organizations causes the "insurance" of disaster recovery to be very expensive.
- Refreshing DR infrastructure is a slow and laborious process.
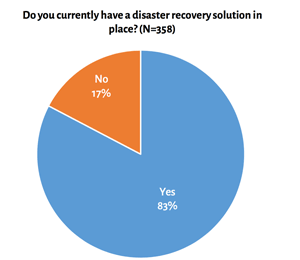
- As seen in Figure 1, which is based on research results from a recent DR as a Service (DRaaS) market report sponsored by Infrascale Inc., too many businesses still don't even have a DR solution. This is likely due to cost and complexity concerns.
 [Click on image for larger view.]
Figure 1. A simple chart showing the breakdown between companies that have disaster recovery policies in place, and those that don't.
[Click on image for larger view.]
Figure 1. A simple chart showing the breakdown between companies that have disaster recovery policies in place, and those that don't.
In light of these challenges, many businesses are looking at the agility that comes with leveraging public cloud resources and wondering, "Couldn't we use that for disaster recovery?" The answer is a resounding "Yes!" And it comes with a number of benefits. Some of the reasons an organization might choose to adopt a cloud-based DR strategy include:
- A reduced datacenter footprint means less expense from hardware, maintenance, utilities and operations staff. From the business's perspective, the environment is purely logical, so the overhead to maintain it is far less.
- Increase flexibility by shifting DR spend to an operational expense (OpEx) model. Because of the way cloud-based DR resources are purchased, there's little or no capital investment at the outset. The business is billed for usage on a monthly basis, just like a utility (power, water, gas and so on).
- Because the business is only billed for what's in use, the spend on DR resources can be substantially less than if the business purchased hardware, space and staff to run an entire second datacenter all the time. Because resources can largely be left powered off until disaster strikes, the majority of money is theoretically only spent in the event of a true disaster.
Unfortunately, it doesn't always work out as simply and effectively as that. As a matter of fact, a poorly designed, poorly understood cloud-based DR strategy can actually end up costing more in the long run than a well-designed on-premises DR solution. So what's the rub? What causes some organizations to fail miserably at implementing a cloud-based DR strategy?
Well, the possibilities are endless, but here are three common mistakes that businesses make when heading down this path. Understand and avoid these pitfalls, and your chances of success with cloud-based DR are an order of magnitude higher.
1. Underestimating Required Network Bandwidth
Because building a DR strategy around workloads running in a datacenter not owned by the company inherently involves moving data off-site, most organizations see this challenge coming and plan fairly well for their replication traffic. In a number of cases, there are many years of historical data from site-to-site replication that the business can comb through to find out exactly what sort of bandwidth is going to be required.
Many vendors who sell cloud-based DR tools even have handy tools that analyze the state of an environment and give a pretty good estimate of what kind of network bandwidth will be required, given the inputs. The good news is that implementers typically get this right the first time. The bad news is that the bandwidth needed to complete replication and meet service-level agreements (SLAs) with regard to the company's recovery point objective (RPO) isn't the only bandwidth in question.
Imagine for a moment that a water pipe servicing the bathrooms next to the datacenter bursts. The datacenter floods and has to be shut down completely. Fortunately, this business has a cloud-based DR solution, and all the high-priority workloads can be recovered in the cloud. Within a matter of minutes, business-critical systems are online and ready to accept user connections.
From a network perspective, what happens now that could've been overlooked during the planning phase? Every user is now accessing the applications over the WAN or VPN. And what are the chances that the business-critical applications were written with non-local user traffic in mind? Slim. Many of the applications assume the user is on the local network, and thus have no measures in place to reduce the amount of network traffic they produce or consume.
This is a really bad situation. Although replication has been working quite nicely ever since the solution was implemented and bandwidth has never been an issue, when the time comes to push the big red button and save the day, the system falls flat on its face because there isn't enough network capacity to support the user traffic.
To avoid this ugly situation, be sure the planning phase of a cloud-based DR implementation involves not only calculations with regard to keeping the off-site data up-to-date and within SLAs, but also with regard to user traffic when an actual recovery is needed.
2. High Data Transfer Costs
When it comes to billing for public cloud solutions, the best way to describe it is: "Death by 1,000 cuts." It's a penny here, a penny there, and next thing you know the monthly bill is $92,000, when it would have cost $45,000 to run the same workloads on-site. Without watchful oversight, an organization's cloud spending can nickel and dime it into a tough position.
Pretty much all resources are billed this way, but one fee that seems to really cause problems is the fee for data transfer.
Public cloud services providers charge a fee, both for data being ingested (entering their datacenter) and for data upon egress (exiting their datacenter). Figure 2 shows an example of a pricing chart -- in this case, for AWS EC2 -- for data transferred both in and out of the system. It looks very minimal -- a bunch of zeroes and $0.01 charges.
The real problem in many situations is caused by the fees tucked away at the bottom of the chart: fees for data transferred out to the Internet (not pictured in Figure 2).
 [Click on image for larger view.]
Figure 2. An Amazon Web Services pricing chart, showing the cost for data transfers.
[Click on image for larger view.]
Figure 2. An Amazon Web Services pricing chart, showing the cost for data transfers.
While everything else looks to be some harmless charges from zero to one cent, data transferred out to the Internet can cost between 5 cents (a discount for large amounts of data) and 15 cents, depending on the AWS region from which the transfer is taking place.
Although ongoing operations where data is transferred tend to be free or minimally costly, it can get expensive if an actual failure takes place. This is where the software you use to control failover, failback and replication can really make or break the strategy.
A poorly designed solution will require a full copy of the data from the failover site to be replicated back to the primary site before the failback process can occur. This means that if you've failed over a 40TB datacenter to AWS because of a disaster, getting your data back on-site (assuming you want to keep the data that has accumulated during the recovery window) will require a full replication of the entire dataset.
Not only will this potentially take ages, but it's going to hit you in the pocketbook. Replicating 40TB of data at something like $0.09/GB might not be the end of the world for some organizations, but in most cases it's an unexpected fee at the very least. And a fee like that in the case of a small business could be crippling.
This unforeseen challenge can't really be avoided; it can only be planned for. There are two primary ways to handle this situation. The first is to acknowledge that it's a reality and set aside an estimate of what it would cost to transfer the entire dataset back out as a part of the disaster recovery plan. Then that money is available in the event that a disaster ever occurs and the data needs to be recovered.
A much more palatable option is to leverage DR software that doesn't require a full replication of data before a failback. As this market has matured, most software vendors selling a cloud-based DR solution have taken this cost into consideration and provide ways to minimize the amount of data transferred out of the public cloud platform.
3. Not Clarifying SLAs
The final challenge that can sometimes be overlooked when implementing a cloud-based DR solution is that of the cloud provider's SLAs. It's important to consider that when you're leveraging another organization's services to guarantee or ensure the availability of your own, you've inherently put yourself at the mercy of that other company. Their promises in the way of uptime, availability and so on have a direct impact on your ability to provide adequate DR protection.
This is especially important to consider when pricing out a product, because as one would expect, there tends to be a tradeoff between cost and the SLA. For example, EBS (block storage from AWS) has a steep cost when compared to archive storage like Glacier (object-based archive storage from AWS), but the SLA for data stored within Glacier indicates that data will be available for retrieval within roughly 3 to 5 hours from requesting it.
This is a dramatic example that most organizations would catch and easily understand, but it clearly illustrates the point. When planning for a cloud-based DR implementation, the cost of 99.9 percent uptime vs. 99.9999 percent uptime can be the difference between the cloud provider's datacenter being affected by the same disaster, and a flawless recovery that makes IT look like heroes. Make sure to carefully weigh the tradeoffs you're making when settling on the provider and tier of service you will procure for your own cloud-based DR strategy.