In-Depth
Disaster Recovery Planning for Hyper-Converged Infrastructure
Is "shelter in place" really the right answer?
Most of the chatter these days about Big Data analytics envisions a sprawl of inexpensive server/storage appliances arranged in highly scalable clustered-node configurations. This hyper-converged infrastructure (HCI) is considered well-suited to the challenge of delivering a repository for a large and growing "ocean" (or "lake" or "pool") of data that is overseen by a distributed network of intelligent server controllers, all operated by a cognitive intelligence application or analytics engine.
It all sounds very sci-fi. But, breaking it down, what are we really dealing with?
HCI has never been well-defined. From a design perspective, it's pretty straightforward: a commodity server is connected to some storage that's usually mounted inside the server chassis (for example, internal storage) or externally connected via a bus extension interface (for example, direct-attached storage over Fibre Channel, SAS, eSATA or some other serial SCSI) all glued together with a software-defined storage (SDS) stack implemented to provide control over the connected storage devices.
What's Old Is New Again
The SDS stack provides all of the "value-add" functionality that was traditionally delivered via value-add software operated on the controller of an expensive shared or SAN-attached storage array -- functions such as de-duplication and compression, thin provisioning, incremental snapshots, snap-clones and disk-to-disk mirroring. Touted as "new," SDS is actually a retro-architecture, resembling System Managed Storage (SMS) software that was a fixture on mainframes from the 1970s forward.
SDS (re-)appeared a few years ago as the latest of many efforts by VMware Inc. to resolve performance problems with virtualized applications. Despite the fact that storage I/O couldn't be demonstrated in most cases to be the cause of slow virtual machines (VMs), and despite the preponderance of evidence that sequential I/O processing at the chip level was to blame for poor VM performance, VMware nonetheless cast blame on "proprietary, legacy storage" and proposed its wholesale replacement with SDS as the fix.
'Software-Defined' to the Rescue?
So, SDS was offered to solve a problem over which it had no influence or control. While "legacy" storage vendors had, in fact, leveraged proprietary value-add software joined at the hip to proprietary array controllers as a means to differentiate their commodity hardware kits from their competitors' (and in many cases to justify obscene prices for gear), this fact had little or nothing to do with virtual application performance. However, VMware's (and later Microsoft's) embrace of SDS saw the model trending (see
Figure 1).
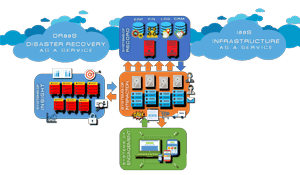 [Click on image for larger view.]
Figure 1. The kinds of functions usually provided on a hyper-converged infrastructure appliance as part of the software-defined storage stack.
[Click on image for larger view.]
Figure 1. The kinds of functions usually provided on a hyper-converged infrastructure appliance as part of the software-defined storage stack.
SDS was subsequently leveraged by VMware (and Microsoft) to create a proprietary stack of software and hardware represented as an "open" hyper-converged architecture: hypervisor, SDS, software-defined network (coming soon), hypervisor-vendor-approved commodity hardware. The result was completely open -- to anyone who built their infrastructure using only VMware or only Microsoft.
However, a number of third-party or independent software vendors also entered the market with their own take on SDS. Most improved in one way or another on the SDS stacks of the larger vendors; and, in order to claw market share, joined together with server vendors (most of whom were weary of being characterized as a "commodity kit" by VMware or Microsoft) to create HCI appliances. Take a farm of these HCI appliances, each with its own storage nodes, cluster them together, overlay with a workload parsing (spreading parts of the overall analytic workload around to different nodes) and analytics engine (to collate and derive information from the ever-growing pool of data storage across the nodes), and, voila, Big Data happens.
Understood for what it is, this kind of infrastructure is reminiscent of superclusters (supercomputers built from distributed server nodes). Some of the inherent ideas for protecting the data in this infrastructure and for recovering the infrastructure from machine faults are also borrowed.
Multi-Nodal Storage
For one thing, each HCI appliance has two or three storage nodes at deployment. With three-node kits, one node provides a quorum function -- overseeing data mirroring between the other nodes and approving the synchronicity of mirrored volumes and data.
With two-node kits, the quorum functionality doesn't require its own storage node. Vendors of the three-node-minimum storage configuration tend to issue separate software licenses for each node, which helps to account for why they prefer a standalone quorum node.
The data protection afforded by multi-nodal storage is simple: Data is replicated on two different sets of media at time of write -- whether the copy is made to two targets at once or is made from target node A, then to target node B, with an acknowledgement made of the second write before the process concludes (so-called two-phase commit).
The end result of this configuration is that the same data has been written to two (or three) nodes, enhancing its survivability in the event of a hardware failure in any one node.
Of course, this strategy is vulnerable to the failure of the node controller (the server), which will make the data on all nodes unavailable. It's also vulnerable to the propagation of erred data or corrupted data to all nodes.
The possibility of bad data being replicated is handled by some SDS vendors by providing a snapshot of block data in the primary target to a snap volume (another location on the node) prior to writing the new data to the primary target. In this way, an erred data write can be "backed out" of the primary volume if necessary.
High Availability
The possibility of nodal controller failure is handled by high-availability architecture, clustering the primary server with a mirrored server. If the two are operated in concert, with each supporting the identical workload, this is an active-active cluster that will survive a server failure without stopping operations. If one server remains offline or near-line, serving only to mirror the data on the primary until it needs to be activated to support workload, then the configuration is active-passive. In such a case, the second server-node controller activates when the primary server "heartbeat" is lost (suggesting server failure). Some data loss may occur, but the shift of the workload to the secondary cluster member is expected to be swift.
These are the basics of disaster recovery (DR) and data protection that you're likely to encounter in any Big Data HCI farm. Not surprisingly, this is where most DR planning ends. "Not surprisingly," because of a couple of unfortunate ideas that have crept into the architecture.
Big Data Concerns
First, there's considerable debate over the value of data in a Big Data environment. Some data scientists argue that the constant influx of data into the Big Data repository has a very limited shelf life. Imagine using Big Data to evaluate the validity of a credit-card purchase in Hawaii. The analytics engine might examine the last 10 purchases made with the card, evaluating where the credit card was presented at the time of each purchase. If minutes before the card is swiped in a reader in Honolulu, the same card is used in Kalamazoo, Mich., there might be a problem. If the analytics engine only examines the last 10 purchases, then what's the value of purchase 11 or 12?
If data only has a very limited useful period, a somewhat incomplete data-protection effort is understandable. Why protect a lot of data that has no value?
In many cases, firms believe that historical data may eventually have value, but they prefer not to incur the cost or "friction" created by moving a lot of data to an archive. Instead, many vendors prefer a strategy of "shelter in place."
Gimme Shelter
Shelter in place has different definitions, too. In some cases, especially among object-storage advocates, shelter in place might mean ending the mirroring of data and replacing it with a data-protection strategy based on erasure coding. Erasure coding involves the application of an algorithmic process to a piece of data that creates mathematically related objects that can be distributed across nodal volumes. If the original data is corrupted, it can be recovered using a subset of the mathematically related objects. This technique is useful for very infrequently changing data and uses less storage than redundant mirroring of all files.
Another meaning of shelter in place is to spin down or de-energize drives in the pool that contains infrequently accessed data. The theory is that quiesced data on unpowered drives can be made available again "at the flick of a switch," if needed, by the analytics engine. While the industry does support different power modes on some hard disk drives, issues remain regarding the wisdom, and efficacy, of turning off drives that contain "archival" data.
Both of these shelter-in-place strategies also run afoul of a bigger issue with HCI Big Data farms generally: the risk of a facility-level or milieu-level outage. If a facility burns down, or a pipe leak develops that requires a power down of hardware and evacuation of the facility, all of the shelter in place, CDP, incremental snapshotting, and intra- and inter-nodal mirroring in the world will not enable recovery.
Playing the Odds
Many hypervisor and Big Data vendors are quick to point to outage statistics suggesting that up to 95 percent of annual downtime results from logical and localized interruption events: application errors, human errors, component failures, malware and viruses. The largest portion of this 95 percent pie slice is scheduled downtime. The other 5 percent of annual downtime results from capital "D" disaster events such as building fires, weather events, geological events, nuclear or chemical disasters, and so on. They openly state that a sensible DR strategy is one that "plays the odds," that is, that high availability trumps DR.
This is the kind of thinking that can get an organization into trouble. The fact that only 5 percent of annual downtime results from disasters at the facility or milieu level is not to suggest that effective DR planning can safely ignore these potentials. At a minimum, if the Big Data operation is deemed critical to business operations, a copy of data supporting this critical set of business processes should be stored off-premises and at a distance sufficient to prevent it from being consumed by the same disaster that destroys the original data.
Given the huge amount of data that's being amassed in Big Data farms, replicating all data across a wire to another location or a DR-as-a-Service provider (or cloud-based Big Data infrastructure) might seem impossible. Moving just 10TB across an OC-192 WAN or an MPLS MAN will take a couple of hours (much faster than the 400-plus days it would take to move the same quantity of data across a T-1 connection). The alternative is cloud seeding.
Cloud Seeding
Cloud seeding involves making a copy of data farm bits to a virtual tape library (another storage node behind an SDS controller such as StarWind Software). Then, in an operation that doesn't take processor capability from the working servers, data is copied over to a tape system operating under the Linear Tape File System (LTFS, created by IBM and now an ANSI standard). Given the huge and growing capacities of tape, the portability of the medium, its resiliency, and combining that with the no-hassle straight copy of files or objects to tape media with LTFS, the result is a means to move a large quantity of data at the speed of any popular transportation method.
With a copy of your data loaded to tape, the media can then be sent to an off-site or cloud services provider that can store -- or load -- your data from tape into compatible infrastructure so it's ready for use if and when a capital D disaster occurs. The cost is minimal and the recovery capability afforded is awesome.
In the final analysis, hyper-converged infrastructure is a work in progress. The foundation of the technology, SDS, is still in flux as vendors struggle to determine what functions should be included in the SDS stack; how best to support hardware flexibility; and how to deliver workload agnosticism. Moreover, much work needs to be done on the data-protection story of HCI. Shelter in place isn't really a full-blown data-protection strategy; it's more akin to the laissez faire strategies for DR from three decades ago, which amounted to: "Take a backup and cross your fingers." Shelter in place and "hope for the best" won't cut it in an always-on world.