In-Depth
The Quest for Guaranteed Recovery Assurance
You probably have a disaster recovery plan in place. But do you know that it's ready if your worst-case scenario occurs?
- By Jim Whelan, Christine Taylor
- 08/02/2016
Most businesses have a disaster recovery (DR) plan. But unbeknownst to those companies, many of those plans will never work. That's not a problem if the business never experiences data corruption, or if an employee never walks off with a server, or if no tornado, hurricane, or earthquake ever strikes. The question is: Do you want to take the chance of these things happening and turning into a nightmare scenario? Because having a DR plan isn't enough: You need to know that it's going to work when you need it. The only way to do that is by periodically testing your DR plan with recovery assurance (RA) testing.
Business continuity (BC) allows the business to continue to generate revenue no matter what happens, and is the driver for data protection and DR. DR plans should counter a multitude of threats to applications and systems, ranging from relatively minor data loss or equipment failure, to a major natural disaster such as flooding or a hurricane.
Having an effective DR plan for these circumstances doesn't mean just a nicely written plan on which someone in IT spent a lot of time. It does mean that the DR plan is in place, that it covers applications by service levels and that it's guaranteed to work. This is a matter of basic business survival; losing your compute capabilities for any significant length of time constitutes a disaster -- and the definition of "significant length" gets shorter all the time.
You've Got Choices
Virtualization allowed IT to consolidate workloads by running applications in multiple virtual machines (VMs) on top of shared server hardware, making better use of available resources. These same benefits apply to DR.
In the "old days," IT would have to set up physical servers running dedicated applications at a DR site, mirroring what was running on the production floor. Now, they can keep applications running as VMs on generic hardware, with much more flexibility and at a lower cost, making comprehensive DR more feasible than back in the pre-virtualization, pre-cloud days.
However, while DR is now more feasible and more important than ever, it's also more complicated. Companies now demand tighter recovery point objectives (RPOs) and recovery time objectives (RTOs), applications running over multiple VMs, load balancing, boot order and dependencies. Other big complicating factors include the sheer size of data and backing up from multiple sites to multiple locations, including remote sites and the cloud.
Ultimately, RPO and RTO must rule the disaster recovery roost: RPO for the maximum amount of data that can be lost without significant business loss, and RTO for the maximum amount of time that an application can be down without significant business loss. Let's look at how well different solutions ensure acceptable RPO and RTO:
- Do nothing: This "solution" is more common than you might think. It's generally a combination of the unwillingness or inability to do serious DR testing, the fervent hope that nothing really bad will happen, and the over-optimistic belief that even if there is a disaster, the environment can recover before any serious damage is done.
- Restore from off-site backups. This is the most elementary of DR plans. It's workable in smaller environments with generous RPO and RTO, and a tested restore plan such as a contract with an off-site company to deliver data on removable media within 12 hours of an outage. However, the process is highly manual and error-prone, takes hours to restore from tape or optical drives, and may require rebuilding servers and storage from bare metal.
- Self-managed DR: These companies manage their own DR programs and are usually heavily integrated with the cloud. IT chooses hot, warm, and cold options depending on application priority and RPO and RTO. Hot options include immediate automated failover to the secondary site upon a threshold event. Warm options enable a failover site that IT manually launches as needed. Cold options present an environment that IT can prepare and launch when needed. The same IT group might invest in all three services, according to budgets and differing application priority. Whatever combination IT chooses, it's absolutely critical that they periodically test all three options.
- Cloud-based Disaster Recovery as a Service (DRaaS): Instead of internally managing DR, IT works with a cloud-based DR services provider to develop a custom plan. The provider is responsible for building and maintaining infrastructure and verification. It's not a hands-off process; IT works closely with the provider to communicate service levels and DR priorities, and to expand as needed. The DRaaS provider will do the heavy lifting of deploying and managing the recovery infrastructure and verifying recoverability.
What Is Recovery Assurance?
Let's talk more about verifying recoverability, or recovery assurance (RA); it's also called guaranteed DR, reliable DR, DR assurance or DR testing. At the simplest level, RA simply means doing enough testing on your backups and replications so you know you can recover systems in the event of a failure.
However, as the old saying goes, the devil is in the details. RA can be complicated because IT needs to pay ongoing, consistent attention to keeping applications continuously available. This is not a trivial undertaking.
First of all, the DR environment is subject to entropy.IT needs to regularly carry out DR testing to keep production and recovery environments in sync. Once a year, or even once a quarter, is probably not enough. Data grows, OSes are updated, patches pile up, applications are upgraded to new versions and so on.
RA also needs to be non-disruptive. As critical as it is, testing cannot compromise production. In order to test DR, some IT organizations try to take evenings and weekends to verify recovery operations.
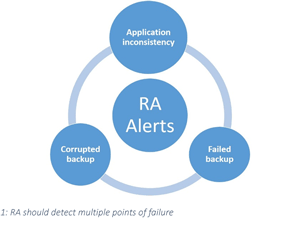
Finally, RA must be robust enough to detect and flag issues so IT can correct them. Typical examples include application-inconsistent backups across multiple interdependent VMs, failed backups and corrupted backups (see Figure 1).
 [Click on image for larger view.]
Figure 1. Your Recovery Assurance plan needs to detect mutliple points of failure.
[Click on image for larger view.]
Figure 1. Your Recovery Assurance plan needs to detect mutliple points of failure.
What Do You Need in an RA Solution?
- Automated testing. Manual testing has its place, but only automated testing can sufficiently test DR across a variety of service levels and applications. For example, critical applications might require a near-continuous process of backup and time-to-failover testing. Less-critical applications won't have to be tested as often, because IT will have the time to rebuild application servers in-house and restore data.
-
The ability to verify application-consistent backups. You'll likely be dealing with multiple VM applications and boot order orchestration, and possibly OS and software upgrades. Your RA solution needs to ensure that all of those things are checked out and in order.
-
The ability to account for failed backups. RA needs to note that a backup has failed and flag it, so IT can fix any problems and reissue a backup command. It also needs to verify completion and check for corruption on finished backups, to avoid being dependent on an unrecoverable backup set.
-
The ability to do sandbox testing. Verifying recovery in a sandbox environment lets you test and tweak your DR plan without disrupting production.
How To Deliver RA
You can do RA in-house or as a purchased service, or a combination of the two. There are two do-it-yourself approaches to RA: manually and using a third-party tool. The first method is usually inadequate, because a sufficient RA process is long and complex. If you're going to do RA in-house, it's far better to go with third-party tools and use one of the automated toolsets available.
These toolsets will enable you to non-disruptively test multiple applications for recovery. Although highly automated toolsets will probably cost more, they'll come with two big benefits: they'll work more thoroughly, and they'll let you test more frequently. When it comes to RA, don't practice a false economy.
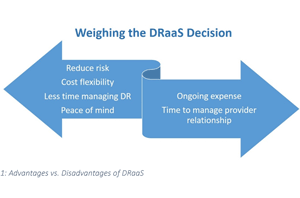
The second major RA option is to turn it over to a cloud-based DR-as-a-Service (DRaaS) provider. DRaaS in the cloud is worth looking into, with more and more established vendors entering the market every day. Benefits include offloading RA expertise from your staff to a provider who already specializes in it, and reducing risk by entrusting your RA process-to-recovery experts. If cost is a consideration (and when is it not?), you can selectively move critical applications to the service and take care of the rest in-house (see Figure 2).
 [Click on image for larger view.]
Figure 2. Advantages vs. disadvantages of DRaaS.
The Long and Painful Road
[Click on image for larger view.]
Figure 2. Advantages vs. disadvantages of DRaaS.
The Long and Painful RoadThere's good news and bad news about RA. The bad news is that there is no safe escape from the complexity of providing effective DR. The good news is that DR and RA technology and services are getting better all the time, and are much more accessible across the board to enterprise, small to midsize enterprise and small to midsize businesses. Strongly consider taking advantage of these tools and services. The time and money you might save by not doing DR well is negligible compared to the cost of a long and painful recovery process.
About the Authors
Jim Whalen is an analyst specializing in data protection at the Taneja Group (tanejagroup.com).
Christine Taylor is an analyst specializing in data protection at the Taneja Group (tanejagroup.com).