In-Depth
Storage Spaces Direct in Windows Server 2016
Microsoft's first attempt at creating a software-defined storage platform wasn't a big hit. Its updated version just might be.
One of the most difficult things in designing IT infrastructure is to get storage right. Think about it: Most server applications come with a minimum and recommended amount of memory and CPU capacity. But how often do you see "20 IOPS required per user," or, "average storage throughput required is 200 Mbps"? Add virtualization to the mix, and housing many virtual machines (VMs) on the same server, all with different storage access patterns, and it can get messy.
Microsoft provided Storage Spaces in Windows Server 2012/2012R2 as a first building block for software-defined storage (SDS). Windows file servers sharing out storage over the SMB 3.0 protocol, clustered together for high availability and performance, backed by SAS-attached external storage chassis with hard disk drives (HDDs) and solid state drives (SSDs) in tiered storage, provided an alternative to costly SANs while being easier to set up and manage.
Despite that, Storage Spaces wasn't a huge success, mainly because traditional vendors didn't want to sell cost-effective storage; they wanted to sell expensive SANs. Another issue was that Storage Spaces only fitted medium to large deployments where three or four separate servers, along with shared disk trays, made financial sense.
In Windows Server 2016 a new storage option is available: Storage Spaces Direct (S2D). Instead of using external disk trays, internal storage in each server is pooled together. This makes scaling easier: Simply add another server when you need more storage. It also opens the options for different types of storage, such as cost effective SATA SSDs and HDDs (as well as SAS) and non-shareable data storage such as NVMe (flash storage accessed via the PCIe bus instead of SATA/SAS). In short, S2D is Microsoft's response to VMware's vSAN.
In this article, I'll look at how S2D works, how it can be deployed, fault tolerance, networking and monitoring.
BEHIND THE SCENES IN S2D
There are two modes in which you can deploy S2D: disaggregated or hyper-converged. In a larger deployment, you'll probably want to scale your storage independently of your compute hosts; you'll have storage clusters (up to 16 hosts in each cluster) that present file shares to your compute hosts to house their VMs or SQL Server databases.
In smaller deployments, you might want to minimize the number of physical hosts and thus might opt for hyper-converged where each host has local storage that make up part of the pool, as well as the Hyper-V role for running VMs.
S2D will automatically use the fastest storage (SSD or NVMe) in your servers for caching. This is a dynamic cache that can change the drives it serves based on changes in storage traffic or SSD failure. The overall limit today in a cluster is 416 disks; much higher than the 80 drives max in Storage Spaces. Note that the caching is real time, unlike the job-based (optimizing once per night) caching that Storage Spaced used. Microsoft recommends at least two cache devices (SSD or NVMe) per node. When you're architecting an S2D system, plan for approximately 5GB of memory on each node per 1TB of cache storage in each node being used.
The new file system in Windows Resilient File System (ReFS) has come of age and is now the recommended option for S2D, as well as for Hyper-V storage in general. The only main feature missing compared to NTFS is deduplication, but this is coming.
If you have three or more nodes in your cluster, S2D is fault tolerant to the simultaneous loss of two drives or two nodes. This makes sense, because in a shared-nothing configuration like S2D you'll need to take servers down for maintenance or patching regularly, and when you have one node down for planned downtime, you need to be able to continue working if another node fails in an unplanned outage. In a two-node cluster, of course, it's only resilient to the loss of a single drive or node.
Two-node clusters use two-way mirroring to store your data, providing 50 percent disk utilization, so buy 16TB of SSD/HDD to be able to use 8TB. A three-node defaults to three-way mirroring, which has excellent performance but low disk utilization at 33 percent; buy 15TB and use 5TB.
Once you get to four nodes, however, things start to get very exciting. Here you can use erasure coding (parity similar to RAID 5), which is much more disk efficient (60 percent to 80 percent). Microsoft uses a standard Reed-Solomon (RS) error correction.
The problem with parity, however, is that it's very expensive for write disk operations; each parity block must be read, modified and the parity recalculated and written back to disk. Microsoft solves this problem (when you're running ReFS) by combining a three-way mirror using about 10 percent to 20 percent of a virtual disk with erasure coding on the same volume. Essentially the mirror acts like an incoming write cache, providing very fast performance for VM workloads. The data is safe because it's been written to three different drives on three different servers, and once the data can be sequentially arranged for fast writing it's written out to the erasure coding part of the volume. Microsoft calls this "accelerated erasure coding," although some articles refer to it as Multi Resilient Volumes (MRV).
Picking a resiliency scheme depends on your workloads. Hyper-V and SQL Server work best with mirroring, parity is more suitable for cold storage with few writes and lots of reads, while MRV excels for backup, data processing and video-rendering workloads.
(As a side note, neither erasure coding nor mirroring in Storage Spaces and S2D has anything to do with old-style Windows Server software RAID. It spreads the data in slabs across all available drives, providing outstanding performance due to parallelism for both read and write operations.)
In larger clusters (12+ servers), Microsoft utilizes a different parity scheme called Local Reconstruction Codes (LRC), which is more efficient when you have lots of nodes and drives.
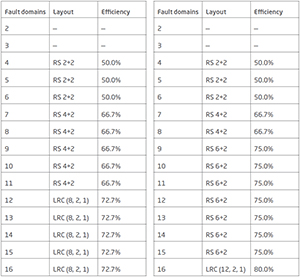
Table 1 shows the disk utilization you can expect based on number of nodes. The left-hand table shows number of nodes and a combination of HDD and SSD, and the right-hand table shows an all-flash configuration.
 [Click on image for larger view.]
Table 1.Disk utilization in Storage Spaces Direct.
[Click on image for larger view.]
Table 1.Disk utilization in Storage Spaces Direct.
If you have servers in multiple racks or blade servers in chassis, you can tag nodes in a S2D cluster with identifying information, so if you have a drive fail it'll tell the operator exactly where to go (down to the slot number and serial number for both server and disk) to swap it out. S2D will also spread the data out, making the setup tolerant to a rack or chassis failure.
Unlike Storage Spaces, the process for replacing a drive is very straightforward. As soon as S2D detects a drive failure, it will start rebuilding a third copy of the failed drive data on other drives (in parallel, shortening the time to complete the repair). Once you replace the failed drive, S2D will automatically detect this, as well, and rebalance the data across all drives for the most efficient utilization. You'll want to set aside about two disks worth of storage for these disk repairs in planning your storage capacity.
Microsoft has demonstrated 6 million read IOPS from a single S2D cluster (all flash), which should provide plenty of headroom for most VM deployments.
NETWORKING FOR S2D
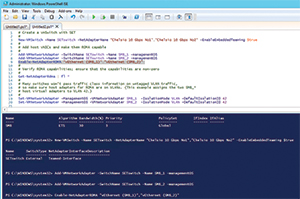
Storage Spaces requires separate networks for host-to-storage cluster traffic, a separate network for cluster heartbeat, and yet another network for VM-to-VM/Client traffic. In a hyper-converged scenario in Windows Server 2016, you can collapse all those networks onto two physical NICs (for fault tolerance) using Switch Embedded Teaming (SET), then use QoS or Datacenter Bridging (DCB) to carve up the available bandwidth (see Figure 1).
 [Click on image for larger view.]
Figure 1. Creating a SET switch for Storage Spaces Direct.
[Click on image for larger view.]
Figure 1. Creating a SET switch for Storage Spaces Direct.
Because a lot of data flows between the storage hosts over the Software Storage Bus, Microsoft requires a minimum of 10 Gbps Ethernet and recommends Remote Direct Memory Access (RDMA) networking.
RDMA networking comes in three flavors: iWarp, RoCE and Infiniband. The two latter flavors require special switches and network engineers to configure DCB, which is fine if you're setting up a whole datacenter with new hosts. I prefer Chelsio's iWarp because it's much easier to configure and troubleshoot, and you don't need special switches; any ordinary 10 Gbps or 40 Gbps Ethernet switch will work. Recently, Microsoft started supporting RDMA in Windows 10, so workstations with extreme network requirements (video editing, 3-D rendering and so on) can take advantage of the increased speeds.
RDMA's main benefit is that it increases your throughput (on average about 30 percent) while using minimal amounts of the host CPU.
TESTING S2D
My test lab consists of four Windows Server 2016 Hyper-V nodes, each with 32GB RAM. I have two SATA HDDs and two SATA SSDs in each host. (Note that these are consumer devices and not suitable for production deployments.)
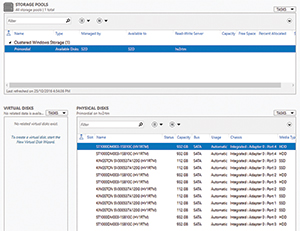
Networking is using Chelsio 2 x 10 Gbps RDMA (in two of the nodes) and Chelsio 2 x 40 Gbps (in the other two nodes), connected with a Dell 12-port 10 Gbps switch. I used Microsoft's Test-Cluster cmdlet (bit.ly/2v0QvFl) to see if the cluster was ready for S2D, followed by New-Cluster (bit.ly/2tbdkZW) to create the cluster. To see the available drives (they need to have no partition on them, and not be a system or OS disk), I used Get-PhysicalDisk (bit.ly/2v0QTnh), as shown in Figure 2.
 [Click on image for larger view.]
Figure 2. The storage pools created by Storage Spaces Direct.
[Click on image for larger view.]
Figure 2. The storage pools created by Storage Spaces Direct.
The Technical Previews of Windows Server 2016 required several steps to set up S2D, but in the released to manufacturing version they've all been replaced with Enable-ClusterStorageSpacesDirect (bit.ly/2tnDPXm), which automatically creates a single pool of all available storage. The final step is creating virtual disk(s) on top of the pool.
MANAGING AT SCALE
System Center Virtual Machine Manager 2016 lets you create a cluster from bare metal servers. With a single checkbox you can enable S2D, either for hyper-converged or disaggregated deployments.
System Center Operations Manager 2016 has a management pack (MP) for S2D, but the monitoring logic isn't in the MP; it's provided by a new storage health service in the OS itself. This provides health state across the whole cluster, as well as performance metrics for the S2D storage as a whole. The health service also covers Storage Replica and Storage QoS. For DIY health reporting (without OM or a third-party monitoring service), use Get-StorageSubSystem (bit.ly/2uiFeTA), then Get-StorageHealthReport (bit.ly/2tnZEWD). Cluster Aware Updating (CAU) is the Windows Server built-in patch orchestration engine. It's aware of S2D and will only patch (and potentially reboot) nodes where the virtual disks are marked as healthy.
THE FUTURE IS NOW
Hyper-converged is the way of the future, and S2D is a great technology for cost-effective VM storage deployments. I think S2D will be the default deployment for Hyper-V storage in many scenarios, and it's a solid competitor to VMware's vSAN.
Note that you need the Datacenter SKU, so S2D isn't an SMB solution, and that SQL Server 2016 databases can be stored on S2D.