How-To
How To Create a Hadoop Cluster in AWS
Amazon Web Services makes it easy to create structures without the expense and hassle of provisioning physical machines.
One of the really great things about Amazon Web Services (AWS) is that AWS makes it easy to create structures in the cloud that would be extremely tedious and time-consuming to create on-premises. For example, with Amazon Elastic MapReduce (Amazon EMR) you can build a Hadoop cluster within AWS without the expense and hassle of provisioning physical machines.
Before I show you how to create a Hadoop cluster in the cloud, I need to discuss a couple of prerequisites. If you're planning on running hive queries against the cluster, then you'll need to dedicate an Amazon Simple Storage Service (Amazon S3) bucket for storing the query results. It's critically important to give this bucket a name that complies with Amazon's naming requirements and with the Hadoop requirements. Specifically, there are two criteria that you must meet when naming your Amazon S3 bucket. First, the bucket name can only contain lowercase letters, numbers, periods and hyphens. Uppercase letters aren't allowed. Second, your bucket name cannot end in a number.
The other prerequisite that you need to be aware of is that you'll need to create an Amazon Elastic Compute Cloud (Amazon) EC2 key pair, if you don't already have one.
Once you have the prerequisite requirements in place, creating the cluster is easy. To do so, log into the AWS console and click on the Create Cluster button, shown in Figure 1.
 [Click on image for larger view.]
Figure 1. Click on the Create Cluster button.
[Click on image for larger view.]
Figure 1. Click on the Create Cluster button.
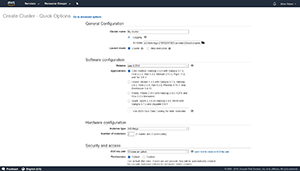
Upon clicking the Create Cluster button, you'll be taken to the Create Cluster screen. AWS has completely automated the cluster creation process. The only thing you have to do is answer a few questions about the cluster that you want to create. You can see some of the available cluster creation options in Figure 2. As you look at this figure, it's worth noting that AWS will by default display the Quick Options screen. If you need more granular control over the cluster creation process, then you can click on the Go To Advanced Options link that's displayed at the top of the screen.
 [Click on image for larger view.]
Figure 2. This is the Create Cluster -- Quick Options screen.
[Click on image for larger view.]
Figure 2. This is the Create Cluster -- Quick Options screen.
The first thing you'll need to do is provide a name for your cluster, and choose whether you want to enable logging. If you opt to enable logging, AWS will write detailed log information to the folder that you specify. It's worth noting that logging can only be enabled or disabled at the time that you create the cluster. If you're in doubt as to which option to use, it's best to go ahead and enable logging.
Next, specify the Amazon S3 folder that you want to use to store logging data, and then choose the desired launch mode. There are two options for the launch mode -- cluster or step execution. If you choose the cluster option, then AWS will create a long-running cluster. This is a cluster that will continue to exist (and run) until you terminate it. A step execution cluster will automatically terminate once it has completed the steps you specify. Incidentally, this article shows the options that AWS displays when you choose the Cluster option. If you choose the Step Execution option, then you'll see prompts asking you to select the steps that you wish to perform.
The next thing that to do is to choose your software configuration. The Software Configuration section prompts you to choose the version (or rather release) and the application that you want to run within the cluster.
The next section prompts you to specify your hardware configuration. This is where you choose the instance type that you want to use as the basis of the cluster. The instance type essentially corresponds to the size of each Amazon EC2 instance used within the Hadoop cluster. The default instance type, for example, is m3.xlarge. In addition to choosing the instance type, you can also choose the number of instances to include within the cluster.
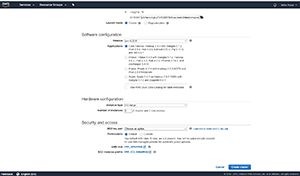
Finally, you'll need to provide the Amazon EC2 key pair that you want to use, and you'll have to specify whether you want to use default or custom permissions within the cluster. You can see what these options look like in Figure 3.
 [Click on image for larger view.]
Figure 3. AWS allows you to specify your hardware configuration, and your security and access settings.
[Click on image for larger view.]
Figure 3. AWS allows you to specify your hardware configuration, and your security and access settings.
Once you finish populating the various options, simply click on the Create Cluster button shown in Figure 3. This will cause Amazon EMR to create the Hadoop cluster.
In my next article I'll step through the process of how to run a hive script on this AWS Hadoop cluster.
About the Author
Brien Posey is a 22-time Microsoft MVP with decades of IT experience. As a freelance writer, Posey has written thousands of articles and contributed to several dozen books on a wide variety of IT topics. Prior to going freelance, Posey was a CIO for a national chain of hospitals and health care facilities. He has also served as a network administrator for some of the country's largest insurance companies and for the Department of Defense at Fort Knox. In addition to his continued work in IT, Posey has spent the last several years actively training as a commercial scientist-astronaut candidate in preparation to fly on a mission to study polar mesospheric clouds from space. You can follow his spaceflight training on his Web site.