How-To
How To Run a Hive Script on an AWS Hadoop Cluster
Once you've created a Hadoop cluster within Amazon Web Services, you can process data using a hive script.
In a recent article, I wrote about how you could create a Hadoop cluster within the Amazon Web Services (AWS) cloud. After completing that article, it occurred to me that it might be useful for to talk about how to run a hive script on that cluster. That being the case, I'm going to assume that you've already built a Hadoop cluster (check out the last article if you need help with that), and I'll show you how to use a hive script to process data.
To get started, open the Amazon Elastic MapReduce (Amazon EMR) console, and then choose the Clusters tab. You'll then need to click on your cluster. You can see what the list of clusters looks like in Figure 1.
 [Click on image for larger view.]
Figure 1. Click on the Clusters tab and then click on your cluster.
[Click on image for larger view.]
Figure 1. Click on the Clusters tab and then click on your cluster.
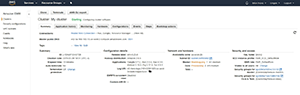
At this point, you'll see a screen like the one shown in Figure 2. As you can see in the figure, the last column on the right is labeled Security and Access. Within this column, click on the link just to the right of Security Groups for Master. This opens a browser tab listing your security groups.
 [Click on image for larger view.]
Figure 2. Click on the Security Groups for Master link.
[Click on image for larger view.]
Figure 2. Click on the Security Groups for Master link.
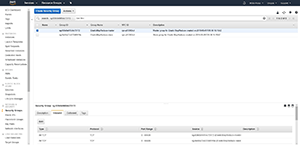
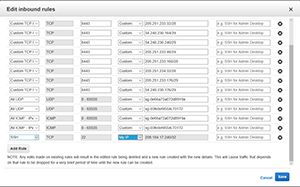
Click on the ElasticMapReducer-Master security group, and then click on the Inbound tab at the bottom of the screen, as shown in Figure 3. Click the Edit button, and then add a rule that grants SSH access for "My IP," as shown in Figure 4. When you're done, click Save and then create a duplicate rule for the ElasticMapReduce-Slave security group.
 [Click on image for larger view.]
Figure 3. Create an inbound rule for the ElasticMapReduce-Master security group
[Click on image for larger view.]
Figure 3. Create an inbound rule for the ElasticMapReduce-Master security group
 [Click on image for larger view.]
Figure 4. Create an inbound rule that gives SSH access to My IP.
[Click on image for larger view.]
Figure 4. Create an inbound rule that gives SSH access to My IP.
Now that the security groups have been prepared, you can add a hive script to your Hadoop cluster. As before, open the AWS EMR console (if it isn't already open), and then go to the Cluster tab and click on your cluster. Incidentally, you might have noticed in some of the previous figures that my cluster status was displayed as Starting. The status will need to be displayed as Waiting in order to submit a hive script.
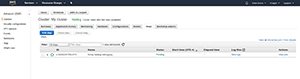
With that said, click on the Steps tab at the top of the screen, and then click on the Add Step button, which is shown in Figure 5.
 [Click on image for larger view.]
Figure 5. Go to the Steps tab, make sure that the cluster is Waiting, and then click the Add Step button.
[Click on image for larger view.]
Figure 5. Go to the Steps tab, make sure that the cluster is Waiting, and then click the Add Step button.
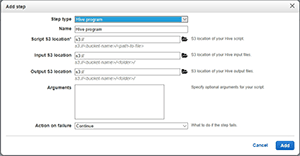
At this point, the console will open the Add Step window. The way that you populate this window is going to vary depending on the particulars of the step that you want to add. If your goal is to run a hive script, then you'll need to set the Step type to Hive Program, as shown in Figure 6. You'll also need to assign a name to the step.
 [Click on image for larger view.]
Figure 6. Set the step type to Hive Program.
[Click on image for larger view.]
Figure 6. Set the step type to Hive Program.
In order to run a hive script, you'll need to copy the script and your script's input files to an Amazon Simple Storage Service (Amazon S3) bucket. As a general rule, you should create three separate folders within the Amazon S3 bucket. One folder will store the script itself. A second folder will store the input files and a third folder will be used to store the output files. If you haven't already copied the script and the input files to their respective folders, you should do that before continuing. Once the files are in place, provide the folder locations in the space provided. You'll also need to provide any required arguments, as well as specify an argument on failure (continue, cancel or terminate).
When you finish, click Add. You should see the step run, and then eventually complete. Once the script finishes, the script's output will be written to a text file (assuming that's what the script was designed to do). This file will be located in the folder that you specified as the Output S3 location. You can see this option in the previous figure.
One more thing you need to know about the process is that when you're finished with everything, and you terminate your Hadoop cluster, the termination process doesn't remove the Amazon S3 bucket. If you want to remove the bucket, you'll have to do so manually.
About the Author
Brien Posey is a 22-time Microsoft MVP with decades of IT experience. As a freelance writer, Posey has written thousands of articles and contributed to several dozen books on a wide variety of IT topics. Prior to going freelance, Posey was a CIO for a national chain of hospitals and health care facilities. He has also served as a network administrator for some of the country's largest insurance companies and for the Department of Defense at Fort Knox. In addition to his continued work in IT, Posey has spent the last several years actively training as a commercial scientist-astronaut candidate in preparation to fly on a mission to study polar mesospheric clouds from space. You can follow his spaceflight training on his Web site.