News
IBM Open Sources Framework to Quicken AI on Hybrid Clouds
IBM Research has open sourced a new framework for working with Big Data/AI/ML projects on hybrid cloud implementations.
Specifically, the new CodeFlare framework simplifies the integration and efficient scaling of Big Data and AI workflows onto the hybrid cloud. It seeks to ease the manual drudgery of configuring setups, such as dealing with machine learning project activities like model training and optimization, data cleaning, feature extraction and so on. These workflow processes are called pipelines, and IBM hopes CodeFlare can make it easier to work with them without having to duplicate efforts or learn anew how to get pipelines to work after others have already done so.
"CodeFlare simplifies this process using a Python-based interface for what's called a pipeline -- by making it simpler to integrate, parallelize and share data," IBM said in a July 7 blog post. "The goal of our new framework is to unify pipeline workflows across multiple platforms without requiring data scientists to learn a new workflow language."
While all that time-consuming configuration, tweaking and other setup and deployment complexity can result in data scientists spending a lesser amount of time on actual data science, CodeFlare is intended to provide them with richer tools and APIs that they can use with more consistency in order to focus more on actual research.
Speaking of time-consuming activities, IBM reported that for one user CodeFlare reduced the time it took to analyze and optimize each of approximately 100,000 pipelines for training machine learning models from four hours to 15 minutes.
"With other users, we've seen CodeFlare shave off months of developer time, and allow them to tackle larger data problems than before," IBM said.
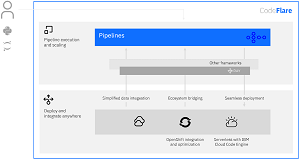 [Click on image for larger view.] CodeFlare (source: IBM).
[Click on image for larger view.] CodeFlare (source: IBM).
The open source project's GitHub repo lists its main features as:
- Pipeline execution and scaling: CodeFlare Pipelines faciltates the definition and parallel execution of pipelines. It unifies pipeline workflows across multiple frameworks while providing nearly optimal scale-out parallelism on pipelined computations.
- Deploy and integrate anywhere: CodeFlare simplifies deployment and integration by enabling a serverless user experience with the integration with Red Hat OpenShift and IBM Cloud Code Engine and providing adapters and connectors to make it simple to load data and connect to data services.
Along with the open sourcing, IBM plans to publish technical blog posts on how to use it, while at the same time improving it to support increasingly complex pipelines by:
- Providing enhanced fault-tolerance and consistency
- Improving integration and data management for external sources
- Adding support for pipeline visualization
And speaking of technical blog posts, one from last month details the future roadmap: "As we embark on this project, several key features are in our roadmap, the key ones are to provide API compatibility to SKLearn, the unification and exchange of data between Spark and SKLearn pipelines, the addition of more complex semantics such as sequential and aggregate states, different forms of firing semantics, and how to leverage these in various usecases spanning AutoML, large language models, and so on."
About the Author
David Ramel is an editor and writer at Converge 360.