How-To
Why an AWS EC2 Instance May Slow Down over Time, Part 2: Troubleshooting
After earlier describing some of the storage types that are used by EC2 instances, Brien now shows how this information plays into the troubleshooting process.
In the previous article, I explained that one of the more common problems associated with EC2 VM (VM) instances in the AWS cloud is that an instance may initially perform well and then slow to a crawl for no apparent reason. Oftentimes, this problem is related to the instance's storage configuration, which I outlined in the previous article. If you have not yet read that article, then I recommend going back and reading it before continuing.
The big takeaway from Part 1 of this series is that there are several different types of storage that can be used for the EBS volumes used by EC2 instances. Some of these storage types are optimized for throughput, while others are optimized for IOPS. While the two types of optimization might sound similar, there is a very key difference between the two.
As I pointed out in Part 1, a volume that is optimized for IOPS is actually configured to deliver a specific number of IOPS. When you create the volume, you can actually specify the number of IOPS that are needed. Throughput optimized volumes work differently.
Before I go on, I need to point out that General Purpose 2 (GP2) and Throughput Optimized HDD (ST1) are both considered to be throughput optimized. This is significant, because when you create a new EC2 instance and accept the storage defaults, the instance will often be based on GP2 storage.
Throughput optimized storage is a bit more complex than storage that has been optimized for IOPS. Remember, that when you create IOPS optimized storage, you can specify the desired number of IOPS. Throughput optimized storage, on the other hand, uses something known as a burst bucket. This is Amazon's way of saying that throughput-optimized storage has a specific amount of baseline throughput, but can also deliver bursts of higher throughput on an as-needed basis. While this basic concept is straightforward enough, there is more to the story.
As you may recall, when you create a volume that is optimized for IOPS, the volume size determines the actual number of IOPS that can be achieved. The same principle applies to throughput optimized volumes in that the volume's size determines its baseline throughput.
Just as the volume size determines the volume's baseline throughput, it also determines the burst throughput. The larger the volume, the larger throughput bursts it can handle. However, the volume's ability to handle throughput bursts is based on a system of throughput credits.
When a throughput burst is required, the volume checks to see if any throughput credits are available. If credits are available then those credits are "spent" and the burst is allowed. Incidentally, throughput credits are acquired automatically. All throughput-optimized volumes gradually accumulate throughput credits, and the larger the volume, the faster it will accumulate throughput credits.
This is the reason why a VM instance might initially perform really well, but then see its performance diminished over time. Initially, the instance is taking advantage of a "bucket full of throughput credits" and is using bursts to service the demand for storage throughput. As the bucket is emptied, however, there are no more credits that can be spent and the instance will be limited to operating at its baseline throughput level until more throughput credits eventually begin to accumulate, allowing another burst.
So how can you tell if a VM instance has exhausted its throughput credits? The easiest way to tell what is going on is to open the EC2 console and click on Volumes, followed by the volume that you want to examine. When the volume's page opens, select the Monitoring tab. This causes the console to display a series of charts related to the volume's performance.
As you can see in Figure 1, one of these charts is called Burst Balance (%). This chart essentially shows the percentage of throughput credits that are remaining. In other words, if the chart reflects a value of 0, then it means that all of the throughput credits have been used up. In the figure, however, the burst balance percentage is 100, meaning that the baseline throughput is adequate to service the instance's current needs and bursts are not currently being used.
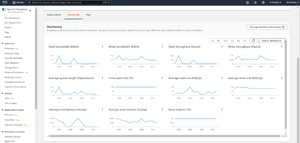 [Click on image for larger view.] Figure 1: The Monitoring tab can show you how bursts are being used.
[Click on image for larger view.] Figure 1: The Monitoring tab can show you how bursts are being used.
If you find that a volume's burst bucket is being depleted, then there are two ways that you can fix the problem. One option is to modify the workload to make it less demanding on the underlying storage. Of course this option isn't always going to be practical. The other option is to modify the instance to use a different volume type that is better equipped to deal with the workload's requirements.
About the Author
Brien Posey is a 22-time Microsoft MVP with decades of IT experience. As a freelance writer, Posey has written thousands of articles and contributed to several dozen books on a wide variety of IT topics. Prior to going freelance, Posey was a CIO for a national chain of hospitals and health care facilities. He has also served as a network administrator for some of the country's largest insurance companies and for the Department of Defense at Fort Knox. In addition to his continued work in IT, Posey has spent the last several years actively training as a commercial scientist-astronaut candidate in preparation to fly on a mission to study polar mesospheric clouds from space. You can follow his spaceflight training on his Web site.