News
Alibaba Cloud Furthers Open Source AI Movement with Two LLMs
Alibaba Cloud, which has been challenging the traditional "Big 3" cloud giants for years, has open sourced two machine learning large language models (LLMs).
The move from the Chinese company comes shortly after U.S.-based Meta (known for Facebook) made big AI news by open sourcing its Llama 2 LLM.
The open source LLM approach stands in contrast to that taken by proprietary offerings like those from OpenAI (creator of ChatGPT) that swayed from their original research purposes and are now being used to generate revenue for big investor Microsoft.
"By open-sourcing our proprietary large language models, we aim to promote inclusive technologies and enable more developers and SMEs to reap the benefits of generative AI," said Jingren Zhou, CTO of Alibaba Cloud Intelligence, in a news release this week. "As a determined long-term champion of open-source initiatives, we hope that this open approach can also bring collective wisdom to further help open-source communities thrive."
Alibaba said the models' code, model weights and documentation will be freely accessible to academics, researchers and commercial institutions as part of the company's effort to democratize AI. Organizations with fewer than 100 million monthly active users can use the LLMs for commercial purposes, while programs with more users can request a license.
The two LLMs are Qwen-7B, pre-trained on over 2 trillion tokens including multilingual materials code and mathematics, covering general and professional fields, and Qwen-7B-Chat, which as its name suggests was conversationally fine-tuned by being aligned with human instructions in training.
The Qwen-7B GitHub repo lists the benefits of the LLM as:
- Trained with high-quality pretraining data. We have pretrained Qwen-7B on a self-constructed large-scale high-quality dataset of over 2.2 trillion tokens. The dataset includes plain texts and codes, and it covers a wide range of domains, including general domain data and professional domain data.
- Strong performance. In comparison with the models of the similar model size, we outperform the competitors on a series of benchmark datasets, which evaluates natural language understanding, mathematics, coding, etc.
- Better support of languages. Our tokenizer, based on a large vocabulary of over 150K tokens, is a more efficient one compared with other tokenizers. It is friendly to many languages, and it is helpful for users to further finetune Qwen-7B for the extension of understanding a certain language.
- Support of 8K Context Length. Both Qwen-7B and Qwen-7B-Chat support the context length of 8K, which allows inputs with long contexts.
- Support of Plugins. Qwen-7B-Chat is trained with plugin-related alignment data, and thus it is capable of using tools, including APIs, models, databases, etc., and it is capable of playing as an agent.
On the performance front noted in bullet point No. 2 above, Alibaba reported that Qwen-7B distinguished itself on several benchmarks, illustrated in this graphic:
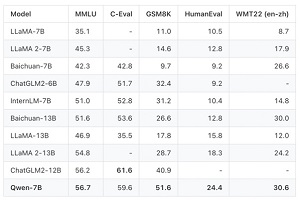 [Click on image for larger view.] LLM Benchmarking (source: Alibaba Cloud).
[Click on image for larger view.] LLM Benchmarking (source: Alibaba Cloud).
"In general, Qwen-7B outperforms the baseline models of a similar model size, and even outperforms larger models of around 13B parameters, on a series of benchmark datasets," Alibaba's associated GitHub repo reported.
Organizations can access the LLMs via the company's AI model community called ModelScope (Chinese language) or the Hugging Face collaborative AI platform (Chinese/English language).
A GitHub tech memo further explained the goal of the release:
We believe that while the recent waves of releases of LLMs may have deepened our understanding of model behaviors under standard regimes, it is yet to be revealed how the accompanied techniques of nowadays LLMs, such as 1) quantization and fine-tuning after quantization, 2) training-free long-context inference, and 3) fine-tuning with service-oriented data, including search and tool uses, affect the models as a whole. The open release of Qwen-7B marks our first step towards fully understanding the real-world application of such techniques. It is our hope that it will enable the community to analyze and continue to improve the safety of those models, striving to establish responsible development and deployment of LLMs.
While AWS, Microsoft and Google have long ruled in the cloud computing space, Alibaba has been dueling with companies like Oracle and IBM for fourth place in terms of market share and other metrics in a series of reports over the past few years. Its cloud computing strength comes mostly from the platform's Asia-Pacific presence.
Stay tuned to see if the company's AI moves (it introduced a proprietary LLM, Tongyi Qianwen, in April) improve its cloud computing market positioning.
About the Author
David Ramel is an editor and writer at Converge 360.