If the message was not clear enough, it is time to move away from the full install of ESX (aka ESX classic). VMware's ESXi hypervisor -- also called the vSphere Hypervisor -- is here to stay. The vSphere 4.1 release was officially the last major release that will include both hypervisors.
In the course of moving from ESX to ESXi, there are a number of changes you need to be aware of that can stump your migration, but none that cannot be overcome in my opinion. Here are my tips to make the transition easy:
1. Leverage vCenter Server for everything possible.
The core management features of ESX and ESXi are now effectively feature on-par with each other when using vCenter for all communication and third-party application support. Try to ensure that specific dependencies on specific host-based communication capabilities can be achieved with a vCenter Server connection or, better still, with an ESXi host directly. A good example of one direct task to an ESXi host would be syslog forwarding; this still can easily be configured directly on an ESXi host.
2. Ensure third party applications fully support ESXi.
There are plenty of applications that we all can use for virtualization. This can include backup, virtualization management, capacity planning, troubleshooting tools and more. Ensure that all vendors fully support ESXi for the products that are being leveraged for the vSphere environment. This also may be a good point to look how each of these tools support ESXi, specifically to ensure that all of the proper VMware APIs are fully supported. This includes APIs such as the vStorage APIs, the vSphere Web Services, the vStorage APIs for Data Protection and more. Here is a good resource to browse the vSphere APIs to see how they can be used both by VMware technologies, and leveraged by third-party applications.
3. Learn the vSphere Management Assistant.
The vMA will become an invaluable tool for troubleshooting as well as providing basic administration tasks for ESXi servers. The vMA is a virtual appliance that is configured to connect to the vCenter Server for a number of administrative tasks to be performed on an ESXi host. Be sure to check out this video on how to set up the vMA.
4. Address security concerns now.
Many virtualization and security professionals are concerned about the lack of ability to run a software-based firewall directly on the host operating system (as can be done with ESX). If this is a requirement for your organization, the best approach is to implement physical firewalls in front of the ESXi server's vmkernel network interfaces.
5. Address other architectural issues.
If there is going to be a fundamental change in the makeup of a vSphere cluster, it may also be time to address any lingering configuration issues that have plagued the environment. While we never change our minds on how to design our virtualization clusters (or do we?), this may be a time to enumerate all of the design changes that need to be rolled in. Some frequent examples include removing local storage from ESXi hosts and supporting boot from flash media (be sure to use the supported devices and mechanisms), implementing a vNetwork Distributed Switch, re-cabling existing standard virtual switches to incorporate more separation across roles of vmkernel and guest networking interfaces, and more.
The migration to ESXi can be easy with the right tools, planning and state of mind. Be sure also to check the VMware ESXi and ESX information center for a comprehensive set of resources related to the migration to ESXi.
What tips can you share on your move to ESXi? Share your comments here.
Posted by Rick Vanover on 06/14/2011 at 12:48 PM2 comments
VMware has made an important feature of the latest and greatest ESXi (a.k.a. the vSphere hypervisor) -- the command-line environment or tech-support mode -- a bit complex to access. (Tech-support mode was easy to access in older versions, and I cover it here in an
earlier post.).
For modern versions of vSphere, tech-support mode and other network services are controlled in the Security Profile section of the vSphere Client (see Fig. 1).
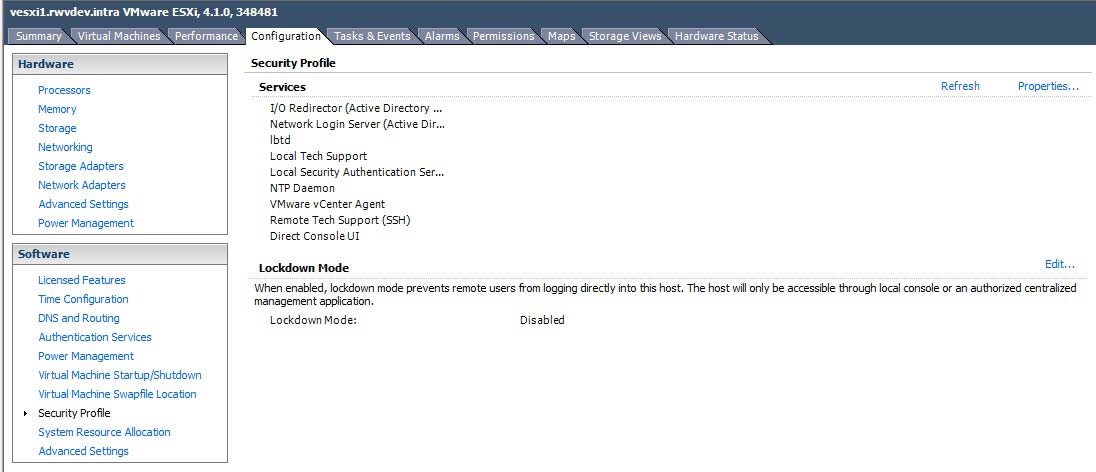 |
Figure 1. The vSphere client security profile allows control of critical services, including tech support mode. (Click image to view larger version.) |
Once tech local tech-support mode is selected to be running (either started one-time or persistently), the command prompt can be accessed from the direct console user interface (DCUI). Within the DCUI, accessing tech support mode is done in the same manner as previous versions, by pressing ALT+F1.
Because local tech support mode is now an official support tool for ESXi, the interface is somewhat more refined in that there is an official login screen. The tech support login screen is shown in the figure below:
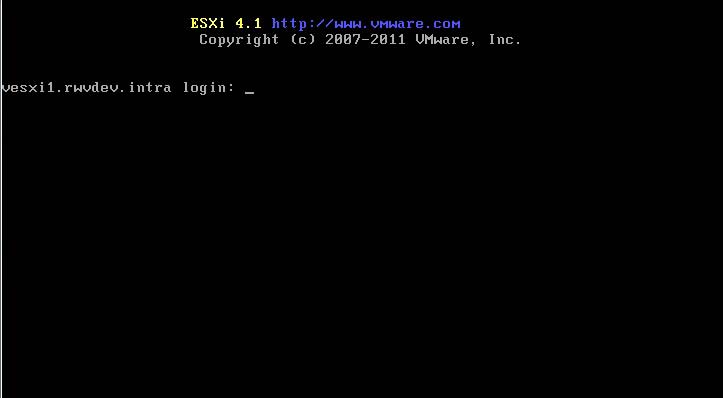 |
Figure 2. Accessing local tech support mode is less cryptic than previous ESXi versions. (Click image to view larger version.) |
Within tech support mode, a number of command line tasks can be performed. In my personal virtualization practice, I find myself going into tech support mode less and less. Occasionally, there are DNS issues that may need to be addressed; and reviewing the /etc/hosts file to ensure DNS resolution is correct and no static entries are in use. If you have been in the practice of using host files for resolution directly on an ESXi (or ESX for that matter) host, now is a good time to break that habit. A better accommodation would be to ensure that the DNS environment is entirely correct and all zones are robust for the accuracy required by vSphere.
Utilizing tech support mode is one of those things that you will need only occasionally, so give some thought to leaving it on persistently on an ESXi host. What strategies have you uses with tech support mode on vSphere? Share your comments below.
Posted by Rick Vanover on 06/08/2011 at 12:48 PM7 comments
Making virtualization work for small organizations is always tough. Recently, I've been upping my Hyper-V exposure, and in the meantime I've been using direct attached storage for the virtual machines. Here are some positive factors for using DAS for virtualization:
- DAS is among the least expensive ways to add large amounts of storage to a server
- There is no storage networking to administer
- Local array controllers on modern servers are relatively powerful
- Storage direct attached will be accessed quite fast over SAS or a direct fibre channel connection
Before I go on about DAS, I must make it clear that every configuration has a use case in virtualization. DAS in this configuration can be a great way to make a small virtualization requirement fit into ever-shrinking budgets.
DAS can be anything from a local array controller in drive slots on a Hyper-V server or it can be a drive shelf attached via a SAS interface or direct fibre channel (no switching). Figure 1 shows a Hyper-V server with DAS configured in Hyper-V Manager:
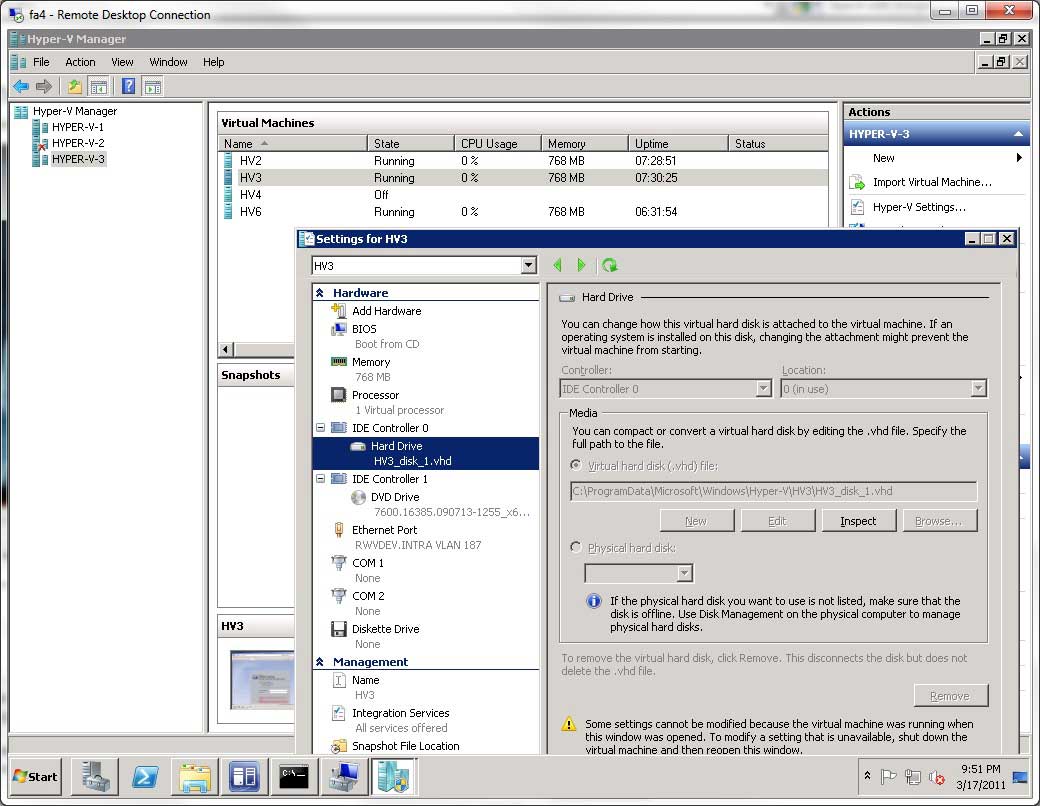 |
Figure 1. Configuring virtual machines in Hyper-V to use DAS can save costs and increase performance for small environments. (Click image to view larger version.) |
Of course there are plenty of concerns with using DAS for Hyper-V, or any virtualization platform for that matter. Failover, backups and other workload continuity issues come to mind. But for the small virtualization environment, many of those solutions come easy. Just as using DAS has the above mentioned benefits, there are downsides:
- Host maintenance made very complicated and migration not available
- Data protection complicated
- Expansion opportunities limited
Again with any situation, there are a number of solutions. This idea came to me in a discussion I had with someone from my offer to help get started with virtualization. For really small virtualization environments; a single host with DAS may be the right solution.
Have you utilized DAS for Hyper-V? Share your comments here.
Posted by Rick Vanover on 04/28/2011 at 12:48 PM2 comments
Even without a virtualization management package, vSphere administrators have long zeroed in on the attribute and annotation fields to organize virtual environments. Individual virtual machines have virtual machine (VM) notes to describe an individual virtual machine. Notes can be as simple as when the system was built, denoting if the server went through a physical-to-virtual (P2V) conversion, or it can be something where you add more descriptive notes fields for virtual appliances. Fig. 1 shows examples of individual VM attribute fields and notes.
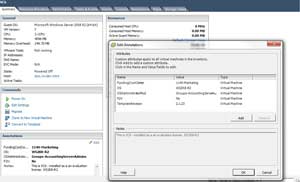 |
|
Figure 1. This virtual machine has a number of attributes defined and populated as well as the notes field providing a description of the VM. (Click image to view larger version.) |
Attributes can also be applied to hosts. Having host attributes can be very handy for something as simple as specifying the location of the ESX(i) host system. For troubleshooting vSphere environments, anything that can be organized in such a fashion that is self-documenting is a welcome step. Fig. 2 shows a host attribute applied with the rack location.
 |
|
Figure 2. This attribute specifies the physical location of the ESX(i) server. (Click image to view larger version.) |
In my personal virtualization administration practice, I've found it a good idea to do a number of things up front. I'll include a revision note attribute for critical indicators, such as the revision of the template in use. While each VM can be investigated within the operating system, it can be much easier to see which VMs originated from template version 2.1.23 (see Fig. 2).
The change log can be something as unsophisticated as a text file or as complicated as a revision-controlled document. In this way, each VM can quickly see their information on the summary pane of each VM, but also in the view of all virtual machines and can utilize a quick sort (see Fig. 3).
 |
|
Figure 3. The vSphere Client allows sorts based on attributes, which is a quick view into the running VMs in the environment. (Click image to view larger version.) |
Regardless of the level of sophistication of the vSphere environment, simple steps with attributes and notes on host and VMs can give a powerful boost to the information obtained within the vSphere Client.
How do you use attributes and notes? Share your comments here.
Posted by Rick Vanover on 02/22/2011 at 12:48 PM2 comments
With vSphere 4.1, VMware removed the easy-to-use Windows Host Update Utility from the standard offering of ESXi. Things are made easy when VMware Update Manager is in use with vCenter, but the free ESXi installations (now dubbed VMware vSphere Hypervisor) are now struggling to update the host.
The vihostupdate Perl script (see PDF here) can perform version and hotfix updates for ESXi. But I found out while upgrading my lab that there are a few gotchas. The main catches are that certain post update options can only be done through the vSphere Client for the free ESXi installations. As I was updating my personal lab, I went over the commands to exit maintenance mode and reboot the host from this KB article. It turns out that none of these will work in my situation -- vCenter is not managing the ESXi host.
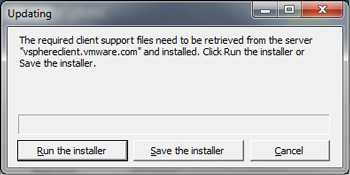
This all started when I forgot to put the new vSphere Client on my Windows system ahead of time. We've all seen the error in Fig. 1 when an old vSphere Client connects to a new ESXi server.
 |
|
Figure 1. When an older vSphere Client attempts to connect to a newer ESXi server, an updated client installation is required. (Click image to view larger version.) |
This is fine enough, as we simply retrieve the new vSphere Client installation and proceed along on our merry way. Unfortunately, this was not the case for me. As it is, my lab has a firewall virtual machine that provides my Internet access. Further, the new feature with vSphere is that the new client installation file is not hosted on the ESXi Server, but online at vsphereclient.vmware.com.
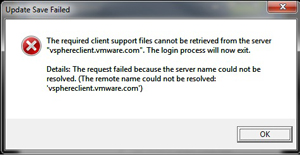
Fig. 2 shows the error message you will get if there is no Internet access to retrieve the current client.
 |
|
Figure 2. The client download will fail without Internet access. (Click image to view larger version.) |
The trick is to have the newest vSphere Client readily at hand to do things like reboot the host and exit maintenance mode when updating the free ESXi hypervisor.
It's not a huge inconvenience, but it's definitely a step that will save you some time should you run into this situation where the ESXi host also provides the Internet access.
Posted by Rick Vanover on 01/27/2011 at 12:48 PM3 comments
So many times I'm asked, "What's next with virtualization?" I find that somewhat funny, as I personally think we are never really done with the journey to virtualization. Whether there are bricks in the datacenter that cannot be virtualized for one reason or another or possibly the fear of moving the most critical applications to a virtualized platform, most real-world users never really finish.
My argument is that once everything is virtualized, it's time to optimize. The constant ebb and flow of the virtualized environment based on workload changes, organic growth, storage use and other events are all factors in gauging the overall state of the virtual infrastructure. Any positive impact to the environment that can make a 2 percent gain here, a 3 percent gain there and a 1 percent gain over there are all very welcome, especially if they can be done without additional cost.
I'll equate this to some experience I have at a previous role working as a solutions provider for one of the nation's largest retailers. The customer was always running around with calculators and stopwatches in the material handling environment. The logic was that if each system or facility could gain 2 percent efficiency, it would equate to the overall use of one system when that gain is aggregated across more than fifty systems in use.
Virtualization truly isn't very different. If small tweaks across a number of areas can improve detail performance measures, they may equate to an additional host's capacity to accommodate organic growth or give the environment enough headroom to allow a powered down host overnight with a feature such as VMware's Distributed Power Management feature.
Virtualization is all about the details, not the right-click. Now would be a good time to sharp-shoot the environment.
Posted by Rick Vanover on 12/16/2010 at 12:48 PM3 comments
Nothing is more frustrating than determining that a virtual machine cannot be migrated when you need to migrate a number of guests, such as when you're putting a host in maintenance mode. If
DRS is in use on a vSphere cluster at any level of the fully automated configuration, vCenter can generate recommendations and issue the vMotion instruction to the cluster.
Cluster-issued vMotion commands are easy to catch, as they are logged as being initiated by "system" instead of the person's username who may have sent an individual VM to be migrated. Depending on the migration threshold configuration (the sliding bar) for the cluster, this may be a frequent or a rare occurrence to have the cluster issue the command to migrate a guest.
While that is a fine set of functionality -- and I've used it a lot over the years -- vMotion occasionally will stop working on a host. Any number of issues can cause the stoppage, such as networking connectivity gaps, time offset or other factors. Usually the fix is a quick reset of the Advanced | Migrate | Migrate.Enabled value from 1 to 0 and then reset it back to 1. VMware KB 1013150 explains how to reset this on an ESX(i) host.
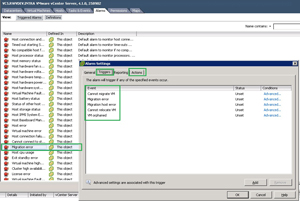
If this situation or some other obstacle to migrate a host arises, the vCenter Server will continually try to migrate the virtual machine and log its failure as often as the DRS refresh interval is configured. The solution to get a heads up on a potential issue with an ESX(i) host is to configure the migration error alarm (see Fig. 1) to send an e-mail, trap or page of the event (see Fig. 1).
 |
|
Figure 1. The conditions for the migration failure can be defined, customized and set for actionable alerts. (Click image to view larger version.) |
This little step along with corrective action can help keep the DRS algorithm in check for a cluster, so that the host workload stays balanced as intended by the cluster design.
This task is disabled by default, yet logged in the recent tasks of the vSphere Client as well as in the database; but it is easy to miss.
Have you utilized this alarm? How so, share your comments here.
Posted by Rick Vanover on 12/14/2010 at 12:48 PM2 comments
I've noticed a few commercial courses available for VMware training that are not provided by VMware Educations Services authorized providers. While training via a third-party without the official course material might have some benefits, such as bringing in real-world experience or very specialized content, most people go the VMware training route as a means to certification.
VMware is one of the few organizations that require a certification from one of their own course content programs delivered by an approved provider. This course is one of the basic courses on vSphere administration, which is the gateway to the VMware Certified Professional.
If VMware certification is the goal, then one should seek out the course material through the VMware Education Services Web site. Each prospective course-taker should register for a profile, and click on the Find a Class link. There, providers can be displayed by partner, location or course content.
The material offered by the other parties is generally topic-similar in nature to the course track of the VMware-sanctioned material, but not entirely. I've also noticed a few virtualization certifications show up from these programs, including the Certified Virtualization Expert (CVE) and ESXLab Certified Virtualization Specialist (ECVS).
One benefit, generally speaking, of independent certification content is that it may be favored by regulatory or government situations. That point was raised by virtualization and security expert Edward Haletky in this VMware Communities discussion when the CVE was first floated for discussion in the forums.
Based on the maturity level of virtualization certification for VMware technologies, my recommendation is to stick with the VMware material. Do you disagree? Share your comments here.
Posted by Rick Vanover on 12/09/2010 at 12:48 PM2 comments
DNS has always been a critical component or VMware server-based virtualization. When an ESX or ESXi cluster came into the mix, its criticality increased exponentially. One of the big differences between and ESX and an ESXi installation is the hostname. ESX will prompt it during the installation, where ESXi does a self-resolution to define its hostname.
Given that ESXi is now confirmed to be the hypervisor of the future, it good times to ensure the basics are in good order.
This is the reason why if an ESXi host boots up and displays "localhost" on the direct console user interface or DCUI (which, by the way is the official name of the yellow and grey screen); that means that the ESXi host as it is cannot resolve its name. There are a few considerations to configuring the host, however. Primarily, how is the host configured with IP addressing and DNS suffixes within the vSphere Client or via a host profile or installation script?
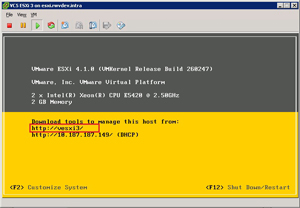
Fig. 1 shows a host that is correctly resolving its IP address to a DNS name in the zone that is configured. The host assigns its addresses via DHCP through a static reservation for the primary MAC address of a virtual switch with two vmnic interfaces assigned to it. Most production environments will not use DHCP, however.
 |
|
Figure 1. When a name other than localhost is shown, the ESXi host has correctly resolved its name. (Click image to view larger version.) |
The fact that the hostname can't be specified in the ESXi installation is also confirmed in the vSphere Client (see Fig. 2).
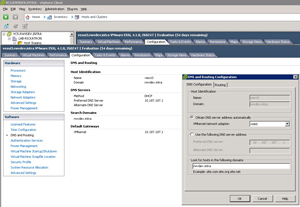 |
Figure 2. The vSphere Client doesn't permit for the name of the ESXi host to be changed. Rather the DNS server configuration, which permits hostname resolution. (Click image to view larger version.) |
DNS will continue to be a critical piece of the virtualized infrastructure, yet it is in a way made simpler by ESXi's configuration for the host names.
What tricks have you employed to configure DNS for ESXi hosts? Share your comments here.
Posted by Rick Vanover on 12/07/2010 at 12:48 PM3 comments
I can come up with plenty of reasons why you'd want to change the computer name of the vCenter Server, but too many times it seems too spooky to do so. While VMware has a few KB articles on fixing specific issues, such as
this one for a registry value; there's no good comprehensive guide for the name change issue. Changing the name involves quite a few steps, so I've collected them here:
Rename the Windows Server: This is the easy part and is no different than renaming any other Windows system.
Correct registry value: In the linked KB article, the "VCInstanceID" value needs the new fully qualified domain name for the server running vCenter.
Database: If the SQL Express database is used and it connects as "Localhost" within ODBC, chances are everything is fine. If the SQL database server is remote, again it should be fine. But it may be worth a call to VMware Support to ensure that you don't encounter any surprises.
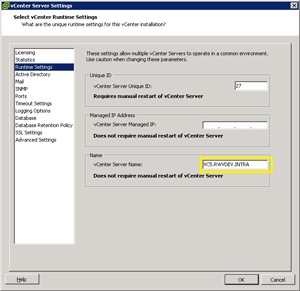
Runtime Server Name: This vCenter Server Settings value will need to reflect the new name; ironically, the setting will display as the previous name, even though you are connecting to and running as a new name (see Fig. 1).
 |
|
Figure 1. The vCenter Server Name is specified in this section of the vSphere Client. (Click image to view larger version.) |
Advanced Server Settings: The vCenter Server Settings options have two http paths for the SDK and WebServices interfaces. Those are not changed from the previous steps, and should be changed to reflect the new name (see Fig. 2).
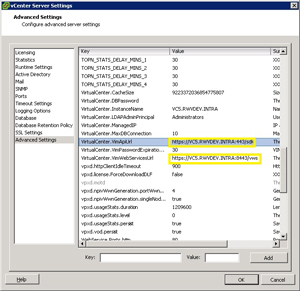 |
Figure 2. Two http interfaces into vCenter need to be changed to reflect the new server name. (Click image to view larger version.) |
DNS: There are no surprises that vCenter uses DNS to function correctly. I wouldn't recommend a manually created DNS CNAME record to point the old server name to the new computer name. But if all else fails, this may be a more attractive option than to rename back to the old name. Also make sure the ESX(i) hosts can successfully resolve the new vCenter Server host name.
Any Third-Party Applications: Anything such as a backup or monitoring solution that plugs into the vCenter Server will need to be reconfigured with the new name.
Overall, the process isn't that tough;, but it can be daunting. I recommend going through it on a test environment configured as similar to your production systems as possible first.
Do you have any other steps on this process to add to the checklist? Share your comments here.
Posted by Rick Vanover on 12/02/2010 at 12:48 PM4 comments
The virtual machine floppy drive is one of those things that I'd rate as somewhere in the "stupid default" configuration bucket. In my virtualization practice, I very rarely use it, and so I add it as needed. While it is not a device that is supported as a hot-add hardware component, that inconvenience can be easily accepted for the unlikely event that it will be needed. The floppy drive can be removed quite easily with PowerCLI.
To remove a floppy drive, the vSphere virtual machine needs to be powered off. This is easy enough to automate with a scheduled task in the operating system. For Windows systems, the "shutdown" command can be configured as a one-time scheduled task to get the virtual machine powered off. Once the virtual machine is powered off, the Remove-FloppyDrive Cmdlet can be utilized to remove the device.
Remove-FloppyDrive works in conjunction with the Get-FloppyDrive, which retrieves the device from the virtual machine. This means that Remove-FloppyDrive can't, by itself, remove the device from a virtual machine. The Get-FloppyDrive Cmdlet needs to pass it to the Remove-FloppyDrive command. This means a simple two-line PowerCLI script will need to accomplish the task. Here's the script to remove the floppy drive for a virtual machine named VVMDEVSERVER0006:
$VMtoRemoveFloppy = Get-FloppyDrive -VM VVMDEVSERVER0006
Remove-FloppyDrive -Floppy $VMtoRemoveFloppy -Confirm:$false
This is done with the "-Confirm:$false" option to forego being prompted to confirm the task in PowerCLI. Fig. 1 shows this script being called and executed to the vCenter Server through PowerCLI.
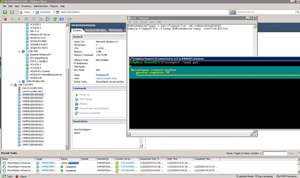 |
|
Figure 1. The PowerCLI command reconfigures the virtual machine to remove the floppy drive. (Click image to view larger version.) |
This can be automated with PowerShell as a scheduled task, and used in conjunction with the Start-VM command to get the virtual machine back online if the tasks are all sequential in a period of scheduled downtime.
Posted by Rick Vanover on 11/22/2010 at 12:48 PM0 comments
In the course of an ESXi (or ESX) server's lifecycle, you may find that you need to add hardware internally to the server. Adding RAM or processors is not that big of a deal (of course you would want to run a burn-in test), but adding host bus adapters or network interface controllers comes with additional considerations.
The guiding principle is to put every controller in the same slot on each server. That way, you'll be assured that the vmhba or vmnic enumeration performs the same on each host. Here's why it's critical: If the third NIC on one host is not the same as the third NIC on another, configuration policies such as a host profile may behave unexpectedly. The same goes for storage controllers: If each vmhba is cabled to a certain storage fabric, they need to be enumerated the same.
When I've added NICs and HBAs to hosts, I've also reinstalled ESXi. Doing so, though, has its pros and cons.
Pros:
- Ensures the complete hardware inventory is enumerated on the installation the same way.
- Cleans out any configurations that you may not want on the ESXi host.
- Is a good opportunity to update BIOS and firmware levels on the host.
- Reconfiguration is minimal with host profiles.
Cons:
- May require more reconfiguration of multipath policies, virtual switching configuration and any advanced options if host profiles are not in use.
- Additional work.
- Very low risk that the vmhba and vmnic interface enumeration is not the same as the install or the other hosts.
I've done both, but more often I've reinstalled ESXi.
What is your take on adding hardware to ESXi hosts? Reinstall or not? Share your comments here.
Posted by Rick Vanover on 11/18/2010 at 12:48 PM3 comments