News
LLMs vs SLMs: When to Go Big or Small in Enterprise AI
Microsoft this week made big news with its new Phi-3 family of open AI models, saying they redefine "what's possible with SLMs," or small language models.
So what is possible with SLMs, and when should an organization go big or small?
The answer to the latter question, as always, is "it depends."
SLMs have somewhat been flying under the AI radar as cloud giants like Microsoft and Google and other major industry players have sought to outdo one another with ever-bigger and more capable LLMs, with some touting training parameters numbering in the hundreds of billions.
However, those can be staggeringly expensive to train and deploy, and they can be overkill for many enterprise AI applications.
So LLMs have emerged along with a movement toward smaller, more specialized AI systems that can be trained on proprietary organizational data sources to serve a specific purpose rather than trying to be a jack-of-all-trades, do-everything tool.
Some key characteristics of SLMs include:
- Smaller parameter size (for example, millions vs billions)
- Lower computational requirements
- Faster training and inference times
- Task-specific training and specialization
- Improved efficiency and scalability
- Potential for deployment on edge devices or resource-constrained hardware
Regarding the latter, Microsoft asked its new AI about the advantage of running on a phone:
 [Click on image for larger view.] Phi-3-Mini Explains Itself (source: Microsoft).
[Click on image for larger view.] Phi-3-Mini Explains Itself (source: Microsoft).
The other characteristics listed above can make SLMs a more cost-effective, accessible approach for smaller organizations that don't have the resources to train and deploy LLMs.
For example use cases, an SLM might be designed to analyze customer service chats or translate between a small number of languages very precisely. This targeted approach makes them well-suited for real-time applications where speed and accuracy are crucial.
Microsoft provided benchmarking data to support its claim that "Phi-3 models outperform models of the same size and next size up across a variety of benchmarks that evaluate language, coding and math capabilities, thanks to training innovations developed by Microsoft researchers."
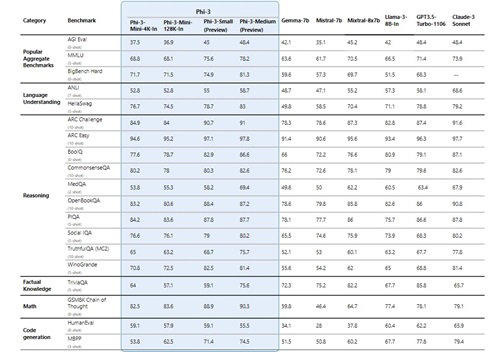 [Click on image for larger view.] "Groundbreaking performance at a small size" (source: Microsoft).
[Click on image for larger view.] "Groundbreaking performance at a small size" (source: Microsoft).
However, the company did note that "Phi-3 models do not perform as well on factual knowledge benchmarks (such as TriviaQA) as the smaller model size results in less capacity to retain facts."
Microsoft executive Luis Vargas this week said, "Some customers may only need small models, some will need big models and many are going to want to combine both in a variety of ways."
For customers in the education field, for example, SLMs might fit the bill, according to UNESCO (United Nations Educational, Scientific and Cultural Organization), a specialized agency of the United Nations (UN).
"When properly trained and optimized with relevant datasets, SLMs become powerful tools from which higher education institutions can derive significant benefits," UNESCO said last month.
One benefit of the go-small approach is a reduction in carbon footprints, with the agency saying: "While SLM technology is still in its infancy, it offers promising potential for higher education institutions seeking greener alternatives for their generative AI integrations. SLMs are well recognized for their lower energy consumption, providing a low-emission option for institutions looking to minimize their carbon footprint and reinforce their commitment to sustainability."
Other industries that might benefit from SLMs were listed by Splunk, a Cisco company: "Consider the use cases in medical, legal and financial domains. Each application here requires highly specialized and proprietary knowledge. Training an SLM in-house with this knowledge and fine-tuned for internal use can serve as an intelligent agent for domain-specific use cases in highly regulated and specialized industries."
Of course, many other factors come into play when an organization chooses which approach to take, but, taking into account all of the above, here are some general guidelines:
Choose an SLM when:
- Task complexity is low to medium (for example, text classification, sentiment analysis)
- Dataset size is small to medium (for example, tens of thousands to millions of examples)
- Computational resources are limited (for example, CPU, memory)
- Faster training and inference speeds are required (for example, real-time or near real-time)
- Edge deployment is necessary (for example, mobile, IoT devices)
- Customization and fine-tuning for specific tasks is important
- Cost and efficiency are key considerations
- High accuracy for a specific task is crucial (for example,, sentiment analysis, spam filtering)
- Working in a specialized domain (for example, finance, legal) with specific language patterns
Choose an LLM when:
- Task complexity is high (for example, long-form/creative text generation, multi-step reasoning, open ended Q&A, drug discovery)
- Dataset size is large (for example, millions to billions of examples)
- Advanced capabilities are required (for example, question answering, research)
- High accuracy and performance are critical
- Applications can tolerate higher latency and energy consumption
- Computational resources are abundant (for example, cloud infrastructure, GPUs, TPUs)
- Adaptability to new situations and handling unforeseen language use is important
- Orgs need a model that can handle multiple languages or broader domains
- Orgs are willing to invest in higher computational resources and potentially longer training times
"The claim here is not that SLMs are going to substitute or replace large language models," said Microsoft AI exec Ece Kamar this week about the debut of the Phi-3 model family. Rather, he said, SLMs "are uniquely positioned for computation on the edge, computation on the device, computations where you don't need to go to the cloud to get things done. That's why it is important for us to understand the strengths and weaknesses of this model portfolio."
About the Author
David Ramel is an editor and writer at Converge 360.