A few months ago I saw a headline that stuck in my mind: "VMware Admins are Storage Admins." While I can remember neither the source of the article nor its author, the idea expressed in the headline is central to understanding the primary challenge of the virtualization industry today. And it is directly related to the subject of benchmarking that I promised to continue from
my last post.
I am sure that by now you have seen more than a fair share of benchmark data published by the leading virtualization vendors. Sometimes the comparison of the benchmark data gets very heated and even provides a certain degree of entertainment. However, if you find enough patience to sift through the wordsmithing and see past the entertainment value, you'll quickly realize that there is actually little real data there.
All of the modern hypervisor technologies are essentially identical when it comes to the quality of implementation of the actual processor virtualization layer. The reason is very simple: Ever since Intel and AMD introduced the V-enabled processors (i.e., in the last five years) the hard task of virtualizing the running code has been done by the processor hardware. That is why, when you see the comparative benchmarks of various hypervisors, they are nearly identical when it comes to the computational part.
Any time you notice a substantial difference in reported performance numbers you should look very carefully at the benchmark configuration and try to understand what exactly was measured by the benchmark. It is not always trivial.
Consider the following automotive analogy: If you drive a Yugo and a Porsche between San Francisco and San Jose at 4pm on a Friday afternoon, you'd be measuring the average speed of the traffic jam on the Bayshore Freeway. What kind of a conclusion about the relative driving qualities of the two cars could you derive from the experiment? Well, you'd definitely know how comfortable the seats are in both cars, which may be all you need to know if you do most of your driving during rush hour on the Bayshore Freeway.
I often think about this analogy when reading through benchmark reports and studies published by virtualization vendors. Here is a good example: the study of performance gains provided by the dynamic resource scheduling in a cluster of several virtualized servers. This is a good, solid piece of work done by competent professionals. It shows that under certain conditions the dynamic resource scheduling software may increase overall productivity of a four-server virtualized cluster by up to 47 percent. That means you can get about 50 percent (let's be generous and round up a few percentage points) more from your servers merely by installing a new piece of infrastructure management software. Fifty percent of four servers are two servers, so by installing the software you'd be able to save yourself the cost of buying two more servers. Awesome.
Now let's dig below the surface a little bit. The paper specifies the hardware configuration for the benchmark: four servers connected to a shared storage disk array. The server configurations are listed as well -- number of CPU cores, memory, etc. I did a quick search and figured out that in the summer of 2009 (when the paper was published) such a server would cost about $6,000. So a 50 percent saving on the server hardware is worth about $12,000. That is pretty cool! I would definitely look into buying the piece of infrastructure software that can get such spectacular savings. Even if I pay a couple of thousand for the software license, I'd still save a lot of money on the hardware side.
Now let's look at the shared storage used in the benchmark. Getting prices for high-end storage hardware is a much more involved exercise than pricing servers -- it can be even more entertaining at times. Perhaps someone should start a Wikileaks for storage hardware pricing, though I am not sure if inviting the wrath of the mighty storage hardware vendors would be any better than inviting that of the world's governments, but I digress.
At any rate, I went through the exercise and figured that the list price for the storage hardware involved in the benchmark was -- are you ready for this? -- around $600,000. Now, I do understand that nobody pays list prices for these puppies. So let's figure a 30 percent discount. Heck, make it a 60 percent discount, for a nice round number of $360,000. It is still 15 times more than your servers. Looking at the price differential, it seems to me that rather than being ecstatic about potentially saving $12,000 on the server side you should be thinking about how to reduce the cost of storage. It seems like a much greater potential savings.
If you have read my previous posts on the I/O Blender problem you should be able to guess the reason behind this seemingly obscene price discrepancy between servers and storage. The highly random nature of the disk IO loads generated by virtualized servers requires a storage system capable of sustaining a very large number of IO operations per second -- IOPs. And the only way to get this with a traditional storage architecture is to increase the number of individual disks, often called the spindle count. That leads to a dramatic (I prefer to call it "obscene") increase in the storage costs.
Now imagine that instead of installing a dynamic resource scheduling software, you'd have an option to install a new type of storage management software that would allow you to dramatically (it is "dramatically" in this case) reduce the required spindle count -- perhaps by a factor of three times. You'd easily save up to $400,000 on your storage -- just add up how much more raw computing power you can get with this kind of savings -- about 60 TIMES more. And yes, such storage software does exist.
I hope this post gave you a taste of how and why to look beyond the obvious benchmark results. As always, I welcome any comments, questions, objections or other interaction.
Posted by Alex Miroshnichenko on 12/06/2010 at 12:48 PM2 comments
A lot of my spare time (which I define as "time not spent blogging") is dedicated to running performance experiments with storage configurations using complex computer systems and applications, which is actually rather fascinating. It may sound geeky, but I figure that if you've already gotten to the point of reading my blog, you won't complain about the geeky part.
Computer system performance is one of the most talked about but least understood concepts. Modern computers function as we expect them to, at least for the most part. The question is how fast they can perform those expected functions. Of course, at some point the quantitative difference in performance becomes a qualitative difference in functionality. If you don't believe that, try browsing your Facebook page (or almost any modern website) using a 10-year-old personal computer, or try watching Netflix online over a dial-up modem connection.
These are pretty obvious and easy examples of the performance difference and, like most things that are easy, they are not very interesting. A much more interesting and useful question is how to determine a practical real-world performance value of a given system before you have committed significant amounts of treasure to buying it and how to ensure that the ownership experience does not turn into an exercise in frustration. Or, putting it simpler, how do you know in advance that the system will perform according to your expectations?
First it would be nice to know what these performance expectations are. This is not as simple as it seems. We all can specify our performance expectations in terms of "I want it now!" but that is hardly a productive approach. We need some standard way to specify the performance requirements.
Often we know the performance data for the system components. For example, the new laptop you want your boss to buy you for Christmas has a CPU rated at 3GHz. This is wonderful, but how much do you as a user really care about that? Do you know how it would translate into the real-life experience you'd have with that laptop? Would you be able to watch your Netflix in HD or just in the standard resolution?
Now is the time to say the magic word: "benchmark." A benchmark is a set of procedures designed to simulate real usage and produce a quantitative result that is supposed to reflect the real-world performance of a given system. Benchmarks are often packaged as self-contained software tools to simplify their application.
The value of a benchmark is determined by how closely it approximates the real-world environment. Well, it should be determined by it, but often the benchmarks are designed to show off a specific technology. Because benchmarks produce numbers, marketing loves them and will go to great lengths to get a number that presents their product in the best light. These great lengths have been known to include specifically crafting benchmarks to show off the strengths of a specific vendor product. There is nothing wrong with it...as long as your concept of "real-world" coincides with that of the vendor. So it is up to you as a user to determine whether a given benchmark actually attempts to measure things important to you and your real world. This is a trivial task and is left as an exercise for the reader.
Second, running a benchmark is similar to running a scientific experiment. You really have to know what you are doing, which includes making sure that you use the right tools and understand the raw results of your measurements. It took 15 minutes to copy a movie image from one drive to another. Copying another image of the same size took 30 minutes. Do you understand why?
You have to account for the environment and various factors that may affect the result. If you are concerned about the bad quality of your Netflix online movies, for example, you should first check to see if your kid has installed and is running a torrent client. "Wait," you say, "she's only three months old!" Well, knowing kids these days, you should probably still check.
Jokes aside, storage performance benchmarking is probably the most obscure, least understood, and most misinterpreted area of computer technology. It is more of an art form, sometimes a black art. The main reason is that the absolute majority of storage systems are built with mechanical devices--disk drives. The huge gap in timing parameters of electronics and mechanical components leads to very tricky behaviors and difficulties in analyzing and predicting the performance.
Storage hardware vendors have developed most of the storage-specific benchmarks to provide a uniform way to compare their products. They could be quite sophisticated and in fact are not geared to put the best light on any particular vendor. They are, however, geared to put the best light on the storage hardware industry as a whole.
One thing to remember is that at the very basic level ALL products from storage hardware vendors can be described as a bunch (often a very large bunch) of commodity disk drives positioned behind (or inside) some kind of specialized computer. The disk drives are commodity products, they come from a very few well-known manufacturers, and all storage hardware vendors use the same drives. So the real differentiation and the value-add that storage vendors provide is in that specialized computer in front. It is important to understand this also accounts for the high price tag of storage systems: If you buy a single disk drive you'd expect to pay less than $100/TB, but if you buy a storage system the price is closer to $1,000/TB.
What is missing in the storage benchmarks results is the price factor. You can get the performance numbers as defined by the specific benchmark rules, but you can't get the price per unit of performance.
Next time, I'll discuss the details of storage benchmarks and how to interpret them in the world of virtualization.
Posted by Alex Miroshnichenko on 11/04/2010 at 12:48 PM2 comments
Solid-state drives have been grabbing a lot of headlines lately. SSDs hold promise for blazing fast storage performance. Unlike traditional hard disk drives (a.k.a. "spinning pieces of rust") they have no moving mechanical parts. The SSD term applies to devices based on a number of different technologies. However, recently it has been used primarily to describe devices based on flash memory. This distinction is important for our discussion.
Today all the major storage vendors, plus a lot of startups you probably haven't heard of, seem to have an SSD story. Based on the buzz at the Flash Memory Summit in August, one might think that all of the world's troubles, including global warming, can be resolved by switching all your storage to SSDs.
I am not so sure about the global warming bit, but SSDs are in fact a major breakthrough in storage technology. However, wholesale replacement of round pieces of spinning rust with square boxes full of flash memory chips is hardly a practical option.
First, using SSDs is still a very expensive proposition. Storage vendors recently announced "major price breakthroughs" by offering flash-based SSDs for $10,000 per terabyte. For comparison shopping, I suggest that you stop by your neighborhood electronics retailer to check out those two-terabyte hard drives for about $100.
Second, there are concerns about SSD durability. These concerns are being addressed by the industry, but here is the truth that no one can contest: SSDs have a finite number of write cycles. So whenever you're planning a long-term system where you have to do a huge number of update cycles, you need to take that into account. It is one thing to use a flash card in a digital camera, where even a British Royal paparazzo is unlikely to reach the write cycle limit. However, using flash memory for a high-frequency financial trading application on the other side of London is quite another matter. You may burn through the write cycle limit in a matter of months, if not weeks.
Third, they're not as fast as a flash memory datasheet would have you think. Unlike good old hard drives, flash memory is very asymmetrical when it comes to differences between read and write performance. Writes are much more expensive in terms of time required. This is particularly true for small, random write operations, which, as we learned from my previous post, is exactly the type of load that's generated by virtualization. Flash memory SSDs are extremely good at random read operations but weak at small random writes.
The reason for this is because you don't just write a data block to a flash memory. You have to erase it first. This is the nature of physics behind the flash memory devices. (I am afraid I can't explain it to you any deeper. I could many years ago when I had just gotten my degree in applied physics, but now we all have Google to tell us things we used to know.)
Even though the erase operation is fast, it can only be applied to a large portion of the memory cell at once, and the typical size is hundreds of megabytes. So if the cell happens to have some data stored in these hundreds of megabytes--and usually it does--you need to do something about that data--like relocate it to another section of the memory cell. Relocating data means that you have to write it, so you'd have to find another chunk to erase. Well, isn't that what we were trying to avoid with the first write? As you can see, the problem quickly snowballs into something rather non-trivial.
A freshly erased flash memory cell is easy to write to (that's what keeps paparazzi in business), but as the write operations arrive at random they fragment the free space. Soon any new write, no matter how small, would require a major reallocation of data before proceeding. So the writes can slow to the point that overall performance could be worse than that of a hard disk!
As you can see by now, the techniques to maintain acceptable performance in flash memory devices can be extremely complicated and resource intensive. Solving these issues requires a substantial investment in software development.
Of course, hardware vendors are constantly trying new techniques, methods and tricks to get around that problem, and so "enterprise-class" SSD devices have very sophisticated controllers--which add to the cost of the drive. One workaround often used is doubling the size of the memory but only presenting about half of it to you as usable space. In fact, you're paying for double the memory you think you have.
Cheap SSD vendors simply ignore the problem of poor random write I/O performance. Early adopters of flash SSDs in laptops discovered this when they paid hundreds of dollars for SSD upgrades from rotating disks, only to find that their computer became slower rather than faster.
Throwing an expensive box full of flash memory chips at your storage interconnection is not magically going to solve your problem of a virtualization storage performance bottleneck. You really have to have the correct file system and storage management software that can fully take advantage of the unique performance benefits and issues of SSDs. Implemented correctly, SSD can do wonders for your performance, but you first have to lay the proper foundation using the right tools and facilities.
Posted by Alex Miroshnichenko on 10/19/2010 at 12:48 PM1 comments
Unless you have been stuck on a remote tropical island without an Internet
connection for the past few years, you couldn't help but notice that every storage vendor has introduced at least one solution for virtualization. Putting aside the veracity of any superiority claims, the number of virtualization offerings from storage vendors is a key indicator that storage in the virtualized world is
different.
What makes it so? Well, one answer is surprisingly simple: the disk drive.
The hard disk drive, an assembly of spinning platters and swiveling actuators (affectionately referred to as "rotating rust") is one of the last mechanical devices found in modern computer systems. It also happens to be the primary permanent data storage technology today. Advances in disk drive technology have been nothing short of amazing -- as long we are talking about capacities and storage densities. When it comes to the speed of data access the picture is far from rosy.
Oops
Consider this: back in the 1980s, I played with Seagate ST412 drives that had been smuggled into the USSR through some rusty hole in the Iron Curtain. Those drives were tough enough to survive that ordeal. They could store about 10 megabytes of data with an average seek time of 85 milliseconds, and average rotational latency added another 8 ms. Fast forward 25 years: modern drive capacities go into terabytes in half the cubic volume. That's over 5 (five!) orders of magnitude increase. Access time? About 10 ms, less than one order of magnitude improvement. One can move the disk head actuator arm and spin the platters only so fast. Capacity has increased more than 10,000 times faster than access time.
This is a huge mismatch. We think about disk drives as random access devices. However, disk drives move random data much slower than sequential, up to a hundred times slower.
This fundamental property of disk drives presents a major challenge to storage performance engineers. Filesystems, databases, software in storage arrays -- are all designed to maximize the sequential I/O patterns to disk drives and minimize randomness. This is done through a combination of caching, sorting, journaling and other techniques. For example, in VxFS (the Veritas File System) -- one of the most advanced and high performance storage software products -- about half of the code (tens of thousands of lines) is dedicated to I/O pattern optimization. Other successful products have similar facilities to deal with this fundamental limitation of disk drives.
Enter virtualization: a bad storage problem gets a lot worse
Virtualization exacerbates this issue in a big way. Disk I/O optimizations in operating systems and applications are predicated on the assumption that they have exclusive control of the disks. But virtualization encapsulates operating systems into guest virtual machine (VM) containers, and puts many of them on a single physical host. The disks are now shared among numerous guest VMs, so that assumption of exclusivity is no longer valid. Individual VMs are not aware of this, nor should they be. That is the whole point of virtualization.
The I/O software layers inside the guest VM containers continue to optimize their individual I/O patterns to provide the maximum sequentiality for their virtual disks. These patterns then pass through the hypervisor layer where they get mixed and chopped in a totally random fashion. By the time the I/O hits the physical disks, it is randomized to the worst case scenario. This happens with all hypervisors.
This effect has been dubbed the "VM I/O blender". It is so-named because the hypervisor blends I/O streams into a mess of random pulp. The more VMs involved in the blending, the more pronounced the effect.
Figure 1 clearly shows the effects of the VM I/O blender on overall performance. It compares the combined throughput of a physical server running multiple guest VMs, each identically configured with an excellent disk benchmark tool called Iometer. The configuration is neither memory nor CPU bound, by the way.
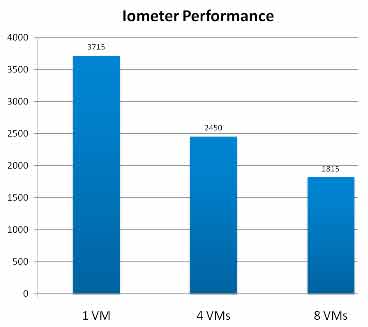 |
Figure 1. As we add more VMs, combined throughput drops dramatically.
|
The performance of a single VM is almost identical to that of a non-virtualized server. As we add more VMs, the combined throughput of the server decreases quite dramatically. At 8 VMs it is about half that of a single VM and it goes downhill from there. This is an experiment you can try at home to see the results for yourself.
Performance evaluation and tuning has always been one the most challenging aspects of IT, with storage performance management rightly attaining a reputation as a black art. Storage vendors tend to focus the attention on such parameters as total capacity, data transfer rates, and price per TB. As important as these are, they do not paint the complete picture required to fully understand how a given storage system will perform in a virtualized environment.
The somewhat ugly truth is that the only way to achieve the required performance in a traditional storage architecture is to increase the disk spindle count and/or cache size, which can easily push the total system cost beyond reasonable budget limits. If you don't have budget constraints, than you don't have a problem. But if you have an unlimited budget, you should be relaxing on that tropical island without the Internet connection that I mentioned in the beginning.
For the unfortunate rest of us, it makes a lot of sense to look at new approaches to control storage and deal with the I/O blender at the source -- in the hypervisor.
This has been a discussion on mechanical disk drives. Solid state disks (SSDs) do change the equation, but are not magic bullets. SSDs pose a number of non trivial caveats of their own. But this is a subject for another post.
Posted by Alex Miroshnichenko on 08/11/2010 at 12:48 PM2 comments
Any energized discussion around virtualization, if conducted long enough, will inevitably lead to defining storage management, which will then quickly turn to the subject of a clustered filesystem.
Clustered filesystems ensure a uniform presentation of storage resources and provide coherent filesystem semantics across all nodes in a computing cluster. This means applications running on different nodes may access files through the same APIs and the same semantics as if they were all on the same physical system. The workflow should seem obvious when we think about such file operations as 'create and delete,' but the actual details are far more intricate.
For example, take two applications that read and update the same region of a file and all reads and writes are completed as a single call. Proper filesystem semantics would guarantee that each application would see either the old version of the region, or the new version of the region, but never a mix between old and new. A clustered filesystem would ensure the same guarantee even for applications running on different physical nodes without requiring any involvement of additional application-level locking.
There are other nontrivial aspects implement correct filesystem semantics. It is not my intent to give an exhaustive overview of these, but I do wish to point out that it is extremely hard to implement a clustered filesystem correctly and in a way that does not impose severe performance limitations. A scalable coherent clustered filesystem with single system image semantics continues to be the 'Holy Grail' of storage management. Since the introduction of server clusters, which came into broad IT practice during the mid-1990s, a number of clustered filesystem products were developed. These products have experienced limited acceptance in the marketplace, primarily due to the number of applications actually requiring such specific functionality.
Now, with the proliferation of server virtualization, clustering and clustered filesystems are again a hot topic. The majority of all virtualization deployments are in fact clusters. Some unique benefits of virtualization, like live migration of VMs between physical hosts, can be achieved only in cluster environments.
It turns out that storage management in a cluster environment is less than trivial. Early vendors like VMware figured this out and developed basic tools for this purpose. As VMware chose to name their tool VMFS (VMware File System), the notion that storage in the virtualized world requires a clustered filesystem quickly became commonplace. Many legacy clustered filesystem vendors saw this opportunity and started positioning their technologies as the solution to the storage problems of the virtual world.
If only it was that simple. A clustered filesystem will provide a basic shared name space. And it is rather trivial to configure individual files on a clustered filesystem as virtual disk images for individual VMs. However, the core access patterns are drastically different from that of a traditional single-system image environment as described above. A virtual disk in a virtual server cluster is never accessed from different physical nodes at the same time. In fact, it is never accessed by more than one VM at any given point in time. Of course the access to a virtual disk may shift to different nodes in a cluster as virtual machines migrate, but access will never be simultaneous. A clustered filesystem would provide correct semantics for accessing virtual disks, and will in fact provide much tighter semantics, but these are not useful for the virtual server world.
There are other requirements for virtual disk access semantics – ones that are not supported by the traditional clustered filesystem architectures. Virtual disks are interesting beasts: There are a lot of them, they all tend to be related and look very similar, they breed like rabbits in Australia and they eat space just like them. So you really need specially designed storage management technologies to cope with them. A legacy cluster filesystem doesn't come close.
But what about VMware VMFS? It is called a "filesystem," isn't it? Yes, it is called that, but if you look carefully at the functionality it provides, it is first and foremost about managing virtual disk containers, it is not a clustered filesystem as legacy vendors would have defined it.
It is far less important how a product or a technology is named than what it does. As this blog column develops, let's explore the specific requirements and features of storage management in the virtualized world in greater detail.
Posted by Alex Miroshnichenko on 08/02/2010 at 12:48 PM2 comments
First off, a huge thank you to editor Bruce Hoard and the Virtualization Review team for inviting me to participate in this CTO blog forum. I look forward to exercising our collective thoughts on storage virtualization. Or should I say virtualization storage?
For most of my professional life I have been intimately involved in developing data storage management software. Having seen and touched a lot of technology over the years, I often experience déjà vu, something that other industry veterans can undoubtedly relate to. Whenever a new wave of innovation rises, be that client -- server computing, storage networking, storage virtualization or an iPhone, it is very easy to get excited about it (and commit to an expensive multi-year contract in return for dubious quality). And, at the same time, feel dismissive.
Storage virtualization: This is just RAID or volume management repackaged, right? Storage networking: Haven't they heard of NFS before? iPhone: Well, it is cute and I can use it to play Plants vs. Zombies. However, the main thing I have come to realize is that it takes time to understand the true impact of new technology.
I must admit, I had some of those dismissive feelings when server virtualization started emerging years ago. And I definitely did not fully appreciate the challenges that virtualization presented in the storage layer. It felt like a familiar if not trivial clustered storage problem, a problem that someone had surely solved. Well, that was almost true; a lot of vendors claimed to have solved it. Yet every large (and not so large) user of virtualization has plenty of gripes about how traditional storage worked (or didn't) in the virtual world.
It took a fair amount of time and effort to come to an understanding that the storage challenges presented by virtualization are rather unique, and that existing solutions were notaddressing them in a comprehensive fashion.
The unique storage challenges arise from the fact that virtualization changes the nature of the relationship between operating system software and computer hardware. In the old world, we always had a one-to-one relationship between a computer and an instance of the operating system running on it. The speed of creating (or as we say nowadays, provisioning) new computer systems was naturally limited by how fast we could procure hardware, connect it to a network and install an operating system on it. We did not really care about the storage an operating system image consumed as the boot disks were an integral part of the computer and were thought to be free. (They weren't, but we never noticed it.)
Virtualization changed that. Servers and workstations became software objects. And as software objects they acquired natural software lifestyles: We allocate them, copy them, move them around, back them up and delete them. They don't need to be running all the time, and can sit dormant for months making it easy to lose track of them while they eat a lot of disk space -- which we suddenly is not free. Server and workstation management in the virtualized world is in fact a storage management problem.
Physical server consolidation as one of the early benefits realized by server virtualization brought about another consequence: the cost of a physical system failing went up dramatically because now a failed piece of hardware brings down not one but several virtual machines. A few years ago a high availability cluster was something you reserved for a few select mission critical servers. Nowadays almost all of your servers are mission critical. Clusters are not only becoming ubiquitous, they also grow rapidly in scale. One of the most amazing features of virtualization is an ability to migrate live running virtual machines between physical servers for dynamic resource balancing which requires clusters of servers that interact seamlessly with clustered storage.
In general the storage problems in the virtualized world fall into three broad categories: performance and virtual machine density, storage sprawl, and virtual machine provisioning. They are all closely related and can be looked upon as different manifestations of the same underlying fact that virtual servers are different from physical. Virtual servers go through different life cycles, they produce different storage access patterns, and consume storage at different rates, and the list goes on. Old storage solutions only take you so far in the virtual world.
I welcome your comments as we frame these discussions and compare notes on the physical world moving into the virtual one.
Posted by Alex Miroshnichenko on 07/27/2010 at 12:48 PM0 comments