In-Depth
Storage: The Next Generation
Qumulo demonstrates its new file system, the heart of its software-defined-storage product.
I recently had a chance to spend some time working with a Qumulo Inc. Q0626 storage system. This is a new software-defined, second-generation, data-aware scale-out NAS storage system that uses a new file system, Qumulo Scalable File System (QSFS).
It's not a trivial manner to create an enterprise-grade storage system/file system, and they don't come around very often. Over the last two decades, I've seen very few show up; ZFS was introduced in 2004, the Isilon OneFS in 2003, Lustre in 2001 and WAFL in 1992. So when the new Qumulo storage system was released, I naturally jumped at the chance to work with it to see what benefits it could bring to the datacenter.
Brett Goodwin, VP of Marketing at Qumulo, invited me up to Seattle to work with the company's new product. I wanted the full experience, so we agreed that I would first do an install and then work a bit with the product. For the install the company did not provide me with a set of instructions -- I simply sat down in front of a rack filled with four Q0626 1U nodes and a TOR switch and was told to go at it, which was an interesting approach.
The folks at Qumulo believe that their software should be intuitive to the point where should you need instructions, they've failed at their job. I instinctively plugged the network cables into the top rack switch and plugged a keyboard, mouse and monitor into one of the nodes. About two minutes after I powered on the nodes, I was presented with an installation menu that simply needed an IP address range and a password. Once I put those in, it prompted me to select the nodes (which it automatically discovered) that I wanted to have join the cluster. It then instructed me to point a Web browser at one of the node's IP addresses. That was it. It took me less than 10 minutes from power up to form a 104TB storage cluster.
Architecture
Following my initial experimentation, Goodwin sat me down to explain the architecture behind the Qumulo storage system. Its initial offering, the one I had just configured, is the Qumulo Q0626 hybrid storage appliance. The naming scheme is straightforward: the Q prefix is for Qumulo, the next two digits "06" indicate the percentage of the appliance storage that is SSD-based, and the last two numbers "26" indicate the overall raw storage capacity of the appliance in terabytes. Qumulo is based on a distributed architecture where each node has both a software-defined storage (SDS) controller (Qumulo Core) and an underlying storage system running on commodity hardware.
The underlying storage devices use the QSFS. As Qumulo Core is a an SDS product, it can easily be implemented on other platforms. Moreover, the company does have a virtual edition of the product that runs on various hypervisors, but it's only approved for functional software product evaluations for now.
The specifications of the Q0626 appliance are straightforward, as it's built using commodity hardware. The 1U rack chassis has an Intel x86 processor, 2 x 800 GB eMLC SSDs, 4 x 6TB HDD, 2 x 10GbE SFP+, and a 1GbE IPMI network card.
The data is initially written and read from the SSD device; then the data accessed less frequently is written to hard disk drive (HDD) devices and striped as wide as practical. Each appliance comes preinstalled with the company's management product, Qumulo Core, which includes the QSFS file system. Qumulo supports NFSv3, SMBv2.1 and RESTful S3 protocols. Another interesting feature of the product is that it supports an "API-first" design methodology, where all the product's features can be accessed via API calls.
After forming the cluster, I logged into the Web console and was presented with a five-tab dashboard. Despite not being given any instructions, I was able to intuitively: create an NFS volume and mount it to an Ubuntu virtual machine (VM) hosted on my laptop; start to create, read and write data to files on the array using the benchmarking tool fio.
In the latter step, performance wasn't measured, because this was a preproduction version of the system; however, the IOPS and throughput were in line with other storage systems I've worked with that had similar hardware. All system files are protected by creating a copy on another node. Although the setup and use process was unusually straightforward and easy, that's not especially remarkable; any number of storage systems on the market can do the same. Its second-generation functionality features -- scalability, API interface and analytics -- are what really set it apart.
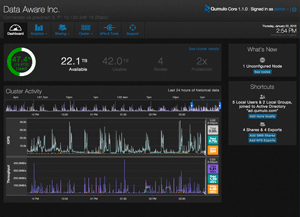
You can see the Qumulo dashboard in Figure 1. I like the clean layout and ease with which you can see the cluster activity in real time. For me, real-time analytics are particularly interesting.
 [Click on image for larger view.]
Figure 1. The Qumulo dashboard.
Scalability
[Click on image for larger view.]
Figure 1. The Qumulo dashboard.
Scalability
Goodwin said Qumulo needs a minimum of four nodes, and can scale up to 1,000 nodes. To test the ease of scale-out, he gave me a node and some network cables and told me to me to "go at it," then walked over to Starbucks for a cup of coffee and to watch it rain (Seattle, the land of coffee and rain).
I placed the node in the rack, cabled it up and powered it on; within two minutes, the dashboard indicated that it had one unconfigured node. Just three clicks later, the raw capacity of the cluster was increased by 26TB. Throughout the process, I didn't detect any decrease in performance. When Goodwin walked back in, I asked him about this and he said that the cluster will opportunistically rebalance the files over the nodes in order to preserve performance.
Software
Things got interesting when we started to talk about the agile development and delivery process, and the "API-first" philosophy of Qumulo. By using an agile delivery process, the company is able to deliver a full release and incorporate new features on a biweekly schedule as the features become available, rather than an arbitrary six-, 12- or even 18-month cycle.
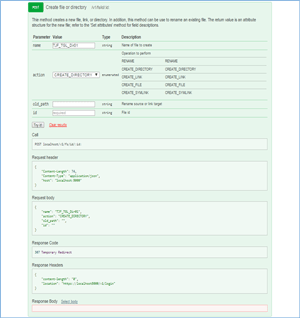
The company makes it easy to program and use the system API calls by including a tab that displays the API calls and sample code; it lets you execute the code from the Web interface. To test this, I created a directory on the system using the Web interface. Figure 2 shows the integrated API. As the entire system is API-based, anything the system is capable of can be accomplished via the API. This is a very useful and powerful feature.
 [Click on image for larger view.]
Figure 2. All Qumulo functions can be programmed via the API for extreme customization.
Analytics
[Click on image for larger view.]
Figure 2. All Qumulo functions can be programmed via the API for extreme customization.
Analytics
One of the major difficulties with storage today is being able to track the space consumed, the number of files on it and who's using the resources on a storage system. Tracking these analytics in real time, as I found out, is where Qumulo really shines.
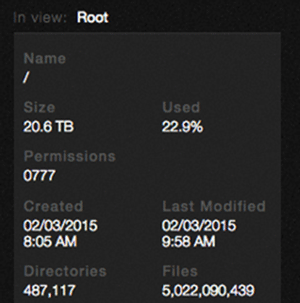
For the next part of my testing, Goodwin turned me over to David Bailey, head systems engineer at Qumulo, who had a four-node system he'd set up a week or so before. He'd created a script that was creating files, and lots of them -- more than 5 billion. What fascinated me was that the base system was keeping track of these files in real time. Figure 3 shows the system we were working on has more than 5 billion files and about half a million directories.
 [Click on image for larger view.]
Figure 3. A storage system with more than 5 billion files and nearly half a million directories.
[Click on image for larger view.]
Figure 3. A storage system with more than 5 billion files and nearly half a million directories.
I watched the dashboard as we created hundreds of files and then deleted thousands of files; the dashboard reported all of this in real time. On a traditional storage system using "du" or "ls" commands, it can take weeks to walk the directory tree to obtain this information on a system with billions of files. This difference is huge. This represents the power of a second-generation storage system.
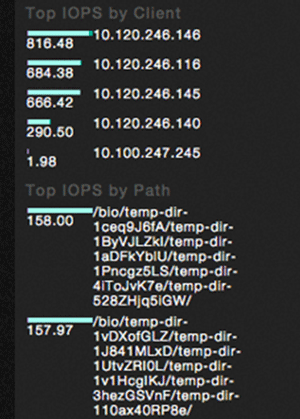
From the GUI, I could see which clients were consuming the most resources. I could also see to which directories and files were actively being written (see Figure 4).
 [Click on image for larger view.]
Figure 4. A snapshot of top system resource users and IOPS.
Disk Failure
[Click on image for larger view.]
Figure 4. A snapshot of top system resource users and IOPS.
Disk Failure
Then, "for fun," Bailey pulled a 6TB spinning disk out of one of the nodes (see Figure 5). The system reported a disk failure almost immediately, and reported that it would take 18 hours to re-protect the system. However, the heavily loaded system didn't indicate a slowdown in performance while the re-protection was taking place. Re-protection finished in 17 hours.
Bailey said that if the system wasn't under load, it would've been much quicker because it opportunistically re-protects the system -- more on the order of 8 hours. With this many small files, it would take first-generation scale-out systems days or even weeks to complete this re-protect operation.
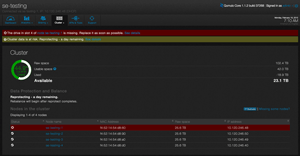 [Click on image for larger view.]
Figure 5. Rebuilding the system after a disk failure.
Rethinking Storage
[Click on image for larger view.]
Figure 5. Rebuilding the system after a disk failure.
Rethinking Storage
Over the span of the last decade, when most of the commonly used storage systems were developed, I've seen a dramatic change in the datacenter workload and the technology available to create a storage system. At least 10 years ago, we were storing thousands of files and we scaled out to a few nodes; today, we need to store millions and billions of files and scale out to hundreds and even thousands of nodes.
Luckily, the technology that we have to build second-generation storage systems has dramatically evolved over the past decade, as well; now, thanks to x86, we have the compute power to enable SDS that can rival and even surpass traditional first-generation storage systems. A single commodity SSD can deliver the same amount of IOPS as 200 hard drives.
It isn't just the hardware that's advanced -- our software development process has, as well. SDS, due to its agility and flexibility, has become commonplace; agile programming, with its timeless delivery methodology, has been embraced not only by Software-as-a-Service (SaaS) applications, but for enterprise products, as well. Various software vendors have bolted these technology advances onto their products, but their core architecture is still based on precepts that are 10 to 20 years old. Qumulo was designed to fully utilize these technologies from the ground up to deliver a second-generation storage system.
As I finished up with Goodwin and Bailey, they mentioned a few other items. Currently, the Q0626 appliance is the only product qualified to run production workloads; however, they also have a virtual edition (VE) that can run on a hypervisor or as an Amazon Web Services (AWS) instance, but is only approved for functional software product evaluations. They also took a few minutes to show me the product's "phone home" feature that can be used to proactively alert Qumulo Care (the company's support organization) to issues with the cluster.
As this is the company's first release, it hasn't added every feature it would've liked and will be adding additional features, such as erasure coding, via its timeless delivery method as these features are developed and tested.
Qumulo didn't start out as an academic project or the outgrowth of an existing product. The three primary inventors of the Isilon OneFS -- Peter Godman, Neal Fachan and Aaron Passey -- got back together a few years ago. They interviewed more than 600 storage professionals and came up with a new storage system that was designed to tackle the thorny issues that have been plaguing the people using existing storage solutions -- scalability, data awareness and ease of use. More specifically, they came up with a second-generation data-aware scale-out NAS storage system with a new file system.
Although I only mentioned my interactions with Goodwin and Bailey in this article, I'd like to thank Chris, Aaron, John, Jeff, Peter, Anh and all the other great guys at Qumulo for taking the time to work with me and explain their storage system.
For those that would like a deeper, more technical look at Qumulo, The Taneja Group (the company for which I work) has written a Technical Validation report (registration required to download PDF).