In-Depth
Disaster Recovery: Not Dead Yet
In the age of virtualization, many think high availability trumps disaster recovery. Think again: It's more necessary than ever.
One doesn't need to look very far to find hypervisor vendor marketing materials, analyst opinions and even a few trade press articles declaring the death of disaster recovery planning. Most are following a line of reasoning from the server virtualization evangelists to make the case that building server hosts with high availability (HA) in mind -- using active-passive failover clustering models, for example -- obviates the need for disaster recovery planning.
Add to the fact that most disasters are local in their cause and effect (surveys suggest that 95 percent of IT outages result from application and software glitches, hardware component failures, malware and viruses, and scheduled maintenance), and a business-savvy question must be asked: Why spend a lot of money to build the capability to recover from a bigger disaster -- a severe weather event, large-scale infrastructure outage and so on -- that has a low statistical probability of happening, anyway? It's not hard to think of other things to do with budget dollars than invest them in an insurance policy that may never need to be used.
Failing To Plan...
In reality, those arguments carry on a tradition of anti-planning sentiments dating back to Noah and the Ark. They tend to hold sway until one of two things happens: an "every-200-year" event like Hurricane Sandy (only to be followed by a second once-in-a-lifetime event the following year), or when a new regulatory or legal mandate requiring business continuity planning and data protection and preservation comes into force.
When either of those things occurs, senior management tends to take a greater interest in the preparedness of the firm for a disaster, and tends to allocate budget to the planning project.
The problem, however, is that few organizations have any personnel on staff who are acquainted with even the fundamentals of disaster recovery (DR) or business continuity planning (BCP). Some have been content to accept their vendor's word for it that deploying two virtual servers in a failover cluster constitutes "business continuity," though ISO Standard 22301, covering business continuity, defines the term quite differently.
Is the nomenclature important? Very much so, especially if your organization is claiming to adhere to the ISO standard as a demonstration of compliance with a regulatory requirement, such as the Health Insurance Portability and Accountability Act (HIPAA).
If patient health-care data is lost owing to a disaster that could have been prevented with basic data protections that would have been part of an ISO 22301 program, the health-care company could be on the hook for regulatory non-compliance. At a minimum, that might earn some unflattering coverage on the front page of The Wall Street Journal; at worst, it might open the door to countless lawsuits, not only for compliance issues but also for fraud.
Anonymous 1s and 0s
A real business continuity program focuses, as the name implies, on the business -- or, rather, on business processes. The planner undertakes a process to assess the criticality of each business process, which includes developing an idea of what processes require fast restores, and which can wait a while in the wake of an interruption event.
With process criticality determined, the planner locates the applications that support the business process and discovers the data associated with those applications. Data inherits its criticality from the process it serves. Without business context, data is just a bunch of anonymous 1s and 0s.
The analytical process concludes with a discovery of where and how data is hosted. It's necessary to find where the data physically resides to help determine the most efficacious way to apply protective services to the data. And, of course, planners also need to understand rates of change in data (how often it's updated), and rates of data growth to identify appropriate backup and recovery strategies.
A business process focus (see Figure 1) is essential for business continuity planning. It's the process, after all, that needs to be recovered following an unplanned interruption event. So, as onerous as it sounds, planners need to develop a clear understanding of the criticality of each business process. This investigation also identifies all relationships between business processes and interdependencies between their applications and data (which often are not intuitively obvious); a key requirement for building an effective recovery strategy.
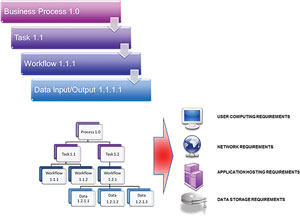 [Click on image for larger view.]
Figure 1. . A typical business process workflow.
[Click on image for larger view.]
Figure 1. . A typical business process workflow.
Business process criticality drives recovery time objectives, which, together with budgetary constraints, define recovery strategy options. The criticality assessment may also have other value: Because it's likely the first time since systems were first rolled out that anyone has sought to document the alignment of the business with its IT infrastructure, the information collected can be of enormous value not only in DR/BCP, but also compliance planning, archive planning and security planning.
Some key points are often lost in translation during discussions of stretch clustering and data replication over distance:
- Data de-duplication and compression doesn't make data move more quickly through a network interconnect. Think about a traffic jam: the SMART car moves no more quickly than the 18-wheeler.
- The 70km "latency wall" is fixed: No amount of link optimization will change Einstein's speed of light rules. Also, 70km isn't always "as the crow flies": in metro areas, a lot of distance is consumed by circuitous wiring paths, which must go around obstacles, up elevator risers and so on.
- You need to know exactly where a cloud DR service is located. The great connection speed you're seeing might just mean that the physical facility is right across the street, affording no meaningful DR protection at all.
Impact Analysis
This "impact analysis," as some call it, is the heavy lifting of DR/BCP. It's the only way to do an effective job of building strategies to protect data assets in a granular way that will support the organization's recovery priorities. It provides the only basis for fitting the right recovery strategy to the right recovery target, based on recovery time objectives.
There has never been one all-encompassing strategy for recovery; planners have always selected a spectrum of options for data and application re-hosting. Since the earliest days of mainframe computing, the options for safeguarding business application processing ranged from laissez-faire approaches (just take a backup and, if a calamity occurs, work with your vendor to resupply whatever hardware that has been lost), to full redundancy (what we call active-active clustering over distance with automatic failover to the remote site if the primary becomes compromised). Figure 2 shows the range of options.
 [Click on image for larger view.]
Figure 2. Many factors go into a proper backup/recovery and business continuity plan.
[Click on image for larger view.]
Figure 2. Many factors go into a proper backup/recovery and business continuity plan.
Clearly, redundancy (HA) provided the shortest recovery time, but it was also the costliest strategy to implement and maintain. This has limited its use.
Failover Clustering
As mentioned previously, there's no "one size fits all" strategy for DR or data protection, at least not one that fits all protection requirements well or cost-effectively. That goes double for failover clustering in the virtual server world.
In truth, organizations don't need, and can't really cost-justify, failover clustering for every application. Following most outage events, companies report that their focus was on recovering about 10 percent of their most mission-critical apps. The other 90 percent waited hours, days or even weeks to be recovered, without devastating consequences to the firm.
Clustering ‘Super-Processes'
Noting that HA clustering is not a cost-effective overall strategy, however, doesn't necessarily resonate with IT folks who have been inundated with hypervisor vendor claims about their "panacea" technology for built-in business continuity. Indeed, many virtualization administrators don't clearly understand the challenges of clustering or the prerequisites for making a failover successful.
Clustering requires some pretty heady provisions to be successful. It actually requires the careful implementation of two "super-processes." One is an ongoing software-based communication across a physical interconnect (usually a LAN) between two or more server nodes that essentially serves as a "heartbeat" monitor, continuously checking the health of the communicating nodes. If this heartbeat fails for any reason, the failover of workload from the active to the passive node is typically automatic (see Figure 3). (This is slightly different in the case of active-active clusters, in which workload is balanced between nodes until a node fails and the entire load shifts to the cluster partner.)
 [Click on image for larger view.]
Figure 3. A typical heartbeat-based, active/passive failover cluster.
[Click on image for larger view.]
Figure 3. A typical heartbeat-based, active/passive failover cluster.
The second super-process is ongoing data replication between the storage supporting each clustered server. A mirroring process is typically set up between the storage connected to each server, so that the same data will exist behind each server should a failover process need to be initiated.
Cracked Mirrors
A big problem with the mirroring superprocess is that mirrors are seldom -- if ever -- checked. Doing so requires that business apps generating data be quiesced, that caches be flushed to the primary write target storage, that the data then be replicated to the mirror storage, and that the mirroring process be shut down, just so you can look at both the primary and mirror volumes to check that both primary and replica data are the same.
Once verified, the mirror and business apps need to be restarted and re-synchronized, which can be a dicey process with career-limiting consequences if re-sync fails. Bottom line: mirrors mostly go untested, so there's no certainty that the data required to "seamlessly failover" from one host to the other is actually present on both systems.
Even with these technical and procedural challenges, failover clustering with mirroring is the prescription of most hypervisor vendors for ensuring continuity of workload processing and data availability. Indeed, this model is recommended by some vendors to ensure business continuity in the face of facility-wide disasters, in which recovery at an alternate location may be required. This "stretch clustering" or "geo clustering" strategy is also fraught with challenges (see "Stretching Your Cluster over Distance: Don't Forget About Einstein") and must be considered carefully.
Further complicating the world of virtual server failover is the ability of VMs to migrate from one physical host to another for purposes of load balancing, optimizing infrastructure resources or freeing up gear for maintenance. While potentially beneficial to datacenter agility, this capability might complicate the clustering/mirroring processes even more, turning it into a veritable shell game and growing the number of data replicas to the point where storage capacity demand accelerates beyond all acceptable rates.
Skyrocketing Capacity Requirements
The impact of disaster recovery strategy on storage capacity demand growth is a big concern in many firms. At confabs last summer, IDC analysts were revising their 40 percent per year capacity demand growth estimates upward to 300 percent per year in highly virtualized environments. This partly reflects shifting workloads, but also the "minimum three storage nodes behind each virtual server" configurations now being promulgated by VMware Inc., Microsoft and others as part of the trend toward software-defined storage models. The next month, Gartner Inc. doubled the IDC estimate, noting that it didn't take into account DR backups or other data copies.
Clearly, whatever strategies are selected for data protection and DR/BCP also need to respect available budget and collateral costs. Strategies also need to reflect the real world.
Given all this, it's clear that claims of traditional DR planning being relegated to the dustbin of history by HA architectures embedded in virtual server computing are wrongheaded and foolish. If anything, the advent of hypervisor computing has brought about an increasingly siloed IT infrastructure with proprietary hardware and software stacks organized under different vendor hypervisor products. This is having the effect of creating multiple, separate DR targets, each in need of its own strategies for protection and recovery.
Storm Warning
In the contemporary enterprise, where some apps continue to operate without hypervisors and where the virtualization environment features multiple hypervisors with separate server, network and storage components, the need for a robust DR/BCP program has never been greater. Truth be told, HA has always been part of the spectrum of strategies available to planners; but it introduced complexities and costs that found it's used only behind the most mission-critical applications, with the most demanding "always-on" operational requirements.
As we enter the new severe storm season, and the potential for data disruption it represents, it's probably wise to remember these points.