News
Virtualized GPUs Target Deep Learning Workloads on Kubernetes
Israel-based Run:AI, specializing in virtualizing artificial intelligence (AI) infrastructure, claimed an industry first in announcing a fractional GPU sharing system for deep learning workloads on Kubernetes.
The company offers a namesake Run:AI platform built on top of Kubernetes to virtualize AI infrastructure in order to improve on the typical bare-metal approach that statically provisions AI workloads to data scientists. The firm says that approach comes with limits on experiment size and speed, low GPU utilization, and lack of IT controls.
Creating a virtual pool of GPU (graphics processing unit) resources, the company says, abstract data science workloads from infrastructure to simplify workflows.
In an announcement today (May 6), Run:AI said its fractional GPU system lets data science and AI engineering teams run multiple workloads simultaneously on a single GPU, helping organizations run more workloads such as computer vision, voice recognition and natural language processing on the same hardware, lowering costs.
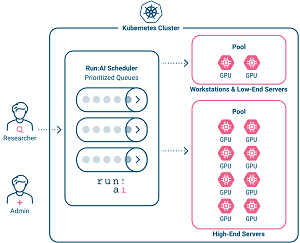 [Click on image for larger view.] The Run:AI Approach (source: Run:AI).
[Click on image for larger view.] The Run:AI Approach (source: Run:AI).
To overcome some limitations on how Kubernetes handles GPUs, the company resorted to some tricky math, effectively marking them as floats that can be fractionalized for use in containers, rather that integers that either exist or don't.
"Today’s de facto standard for deep learning workloads is to run them in containers orchestrated by Kubernetes," the company said. "However, Kubernetes is only able to allocate whole physical GPUs to containers, lacking the isolation and virtualization capabilities needed to allow GPU resources to be shared without memory overflows or processing clashes."
The result of the company's work to overcome that limitation are virtualized logical GPUs -- sporting their own memory and computing space -- that appear as self-contained processors to containers.
Especially useful in lightweight workloads -- including inference -- eight or more container-run jobs can share the same physical chip, while typical use cases allow for only two to four jobs running on one GPU.
More information on creating a virtual pool of GPUs is available here.
About the Author
David Ramel is an editor and writer at Converge 360.