In-Depth
Microsoft Radius, Keda, Copa and Dapr
Paul discusses the new and established offerings and how they can work together to help developers and infrastructure folks deploy and manage applications at scale.
As an infrastructure guy, I find it interesting to follow the modern, cloud-native, microservices-based IT space and how it's evolving.
I was there when containerization started gaining steam, realizing the immediate benefits compared to traditional virtual machine (VM) virtualization. I spoke to students about how it was a different approach and how Microsoft was building container support into Hyper-V and Windows in general. Predictably, once the "new-shiny" gloss wore off from the coolness of containers themselves, the challenges of managing them at scale arose. I remember writing an article in those early days, comparing different container orchestrators, and looking to see which one would come out on top. Of course, Kubernetes did and it's now everywhere, and every major cloud provider offers a managed version.
However, the challenges of writing distributed, microservices-based, cloud-native applications cannot be underestimated. Before containers, I was teaching students about high availability, reliable servers with redundant components, and software-based replication techniques in SQL Server and Exchange Server. Combine this with expensive SANs and redundant networking hardware and it was very complex, costly and hard to maintain. This was all how you "did it" on-premises when trying to provide high availability.
Then Microsoft (and AWS) started sharing how they built, managed and monitored their hyperscale cloud infrastructure. No SANs (I even wrote an article titled "there are no SANs in the cloud" which is now outdated as Azure offers Elastic SAN in preview), and no proprietary switch and router infrastructure. All of Azure's switching gear runs on the Debian-based Sonic, which (you guessed it) uses containers. And that's not a Microsoft-unique approach. You can buy Cisco switches (and others) running Sonic. And all the servers, storage and networking are commodity gear with nothing special to ensure high availability -- instead hardware is expected to fail. "One in a million chance" means that every day a server, rack, switch or storage unit will fail when you have millions of servers. So, you build the software that powers each datacenter to automatically mitigate failures. And then customers build applications to run on top of this resilient (as a whole, with individual components failing) fabric.
But this isn't easy, as it turns out. Even with containers, Kubernetes and platform services in each public cloud, it's not easy deploying and maintaining a scalable, microservices-based application.
This is where Microsoft's recently made public open source project Radius comes in, as do earlier projects such as Dapr, Keda and Copa. The first two are projects in the Cloud Native Computing Foundation (CNCF), with Keda in the graduated level and Dapr in incubating and with Radius and Copa having been submitted. In this article I'll discuss them and how they work together and see how they can help developers and infrastructure folks deploy and manage applications at scale.
Project Radius
No this isn't Remote Authentication Dial-In User Service (RADIUS) from 1991 which is still in use all over the internet for authentication and accounting of VPN sessions and the like. Project Radius is an application platform that enables IT to define, deploy and collaborate on cloud-native applications across public clouds.
Writing microservices-based applications is hard, resulting in complex deployments that are difficult to monitor and manage. Enterprises often want cross-platform portability, generally not to shift a working application from one cloud to another, but rather to be able to use the same tools across clouds (and on-premises). You also want to embed best practices and company policies in the infrastructure, without expecting developers to be ops experts as well as great devs. We thought that Kubernetes would be this cross-platform solution, but it turns out that applications are more than just containers. You need storage, secrets management, observability and monitoring -- and maybe a database backend and connections to other platform services. And your application is much more than just the pods running in Kubernetes; there's a whole world of external services that as a whole make up the service.
 [Click on image for larger view.] Project Radius Goals
[Click on image for larger view.] Project Radius Goals
In Radius, operators define Environments with platform configuration, infrastructure and policies, and developers define applications and their dependencies. This also lets you see the graph of the components that make up an application and frees developers from being concerned about configuring infrastructure -- through recipes. And that's cloud neutral; currently it works on Azure and AWS, but GCP and on-premises are on the horizon. And it builds on existing tools such as Bicep and Terraform.
This enables separation of concerns. The operations team builds environments based on internal policies for each platform (AWS, Azure and so on) with recipes, and developers containerize their application and bring it to Radius. As they deploy it, it ties the app to the infrastructure for deployment, and you can then visualize the app and all its dependencies.
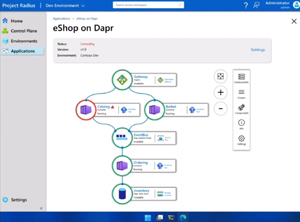 [Click on image for larger view.] Visualization Graph in Radius
[Click on image for larger view.] Visualization Graph in Radius
Shown below is an example application deployed to both AWS and Azure -- and you can see how the Redis cache service is deployed in both clouds but uses the different underlying services in each cloud. And since Radius is an API, it's easy to develop against.
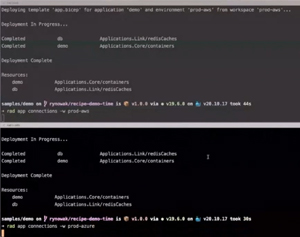 [Click on image for larger view.] The Same Application Deployed to AWS and Azure
[Click on image for larger view.] The Same Application Deployed to AWS and Azure
It's early days for Radius, but the vision is strong, and it makes sense for larger teams to be able to build an application once and then use recipes and environments to be able to lead developers into the "pit of success" by running a command and using the supplied recipes. Here's the introduction that Mark Russinovich gave at The Linux Foundation member summit on Oct. 25, and here's an introductory video.
Distributed Application Runtime (Dapr)
Dapr provides a sidecar container that takes care of complex challenges such as service discovery, message broker integration, encryption, observability and secrets management. In other words, the building blocks of microservices. The beauty of Dapr is that instead of developing against a specific message broker's API (and version) for example, you can develop against the abstraction layer in Dapr, making your code much more portable and development easier.
Version 1.10 added support for workflows and custom components. If there isn't a plug-in available for the datastore or pub/sub broker system you're using, you can write your own, handy for on-premises systems, for example.
There's even a commercial product built on top of Dapr, from Diagrid with some ex-Microsofties working for them, so it definitely has momentum in the market.
Kubernetes Event Driven Autoscaling (Keda)
There are two types of compute scaling in Kubernetes: horizontal where more containers / pods are added as load increases; and vertical, where the allocated CPU and memory for a pod is increased. Kubernetes has a built-in scaler, called Horizontal Pod Autoscaler (HPA), which looks at CPU and memory consumption and adds more pods. The problem with this approach is that it's happening after the fact; the CPU load is increasing as a result of the service as a whole being under load. Keda, on the other hand, lets you scale based on many events and metrics, including the number of messages in an incoming queue, for example. Keda also lets you scale to zero pods, which can be useful if your service has a fluctuating load that sometimes stops completely. A vendor-agnostic approach also helps, with many scalers plugging into Keda, but you don't need to know the specifics of each of them to be able to wire up Keda to work, although obviously using metrics from Prometheus is a common use case.
Copacetic
A lesser-known project is Copa, designed to manage security risks to containers. The time window between disclosure of a vulnerability and exploitation (for all software security issues, not just Kubernetes) is shortening, necessitating rapid patching in container images. But in most environments, that's not an easy task, rebuilding images, testing and so on is time consuming. This is where Copacetic comes in, allowing you to patch the underlying container image with another layer, obviating the need to rebuild the entire image.
This is early days, and the current version .05 can only patch OS level vulnerabilities; it can't patch application-level vulnerabilities. Copa relies on another open source project, Trivy, to supply a list of vulnerabilities. I'm a bit surprised that Microsoft's own container vulnerability solution, Defender for Containers (as part of Defender for Cloud) doesn't feed into Copa, but maybe that's coming.
Conclusion
The fact that Microsoft, once the devil incarnate when it came to open source software, is now a major contributor to many open source projects, including creating and sustaining projects that solve real-world problems for cloud computing, is noteworthy.
It'll be interesting to see what happens in the Kubernetes space going forward, and the elusive goal of easy to deploy and operate, cloud-native, microservices-based, modern application architectures come into focus and "best practices" crystalizes.