Recently, I attended the HP StorageWorks Tech Day in Houston. The event was a way for bloggers to see HP's storage products, from big to small. HP also showcased new products and the corresponding features that go into deciding on storage products for virtualized and non-virtualized infrastructures.
A few weeks ago, I mentioned how I've been playing with many different products and one of the products I have seen was the coolest Hyper-V demo.
During the StorageWorks Tech Day events, we were shown a demo of an 8-node Hyper-V R2 cluster that provided remote mirroring and high-availability technology across two sites. The demo was of the HP EVA 4400 storage series. The storage was also using the HP StorageWorks Cluster Extension for EVA software. There was a simulated latency of less than 400 kilometers (see Fig. 1)
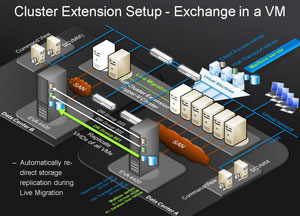 |
| Figure 1. This 8-node Hyper-V cluster extension provided protection between two sites. (Click image to view larger version.) |
What became pretty clear was that HP has a unique advantage in that they are positioned well across many partner ecosystem channels. In this example, where the servers and storage can both be HP solutions, and leveraging the strong Microsoft relationship the cluster extension, HP can deliver this functionality through System Center Virtual Machine Manager (SCVMM). With the storage system, it is important to note that clustered shared volumes (CSV) are currently not supported but are being worked on aggressively.
Finding robust Hyper-V solutions are rare, but I will admit seeing this demo was impressive and the largest Hyper-V cluster I've ever seen. It also is a reminder that the greater virtualization landscape is alive and well in the Hyper-V space.
Posted by Rick Vanover on 04/20/2010 at 12:47 PM7 comments
I'm always on the prowl for small tweaks that can individually make a small difference in the overall experience of a system. In the case of virtualization, this can allow me to squeeze a little more out of my systems.
For performance tweaks, of course the de facto vSphere resource is the Performance Management Best Practices document. But, while I chew through the document when it is updated, it doesn't have as many very specific configurations as I would like. There is logic in that, as you can get in trouble by over-configuring virtual machines, host servers or the storage.
With all that being said, I have come across one configuration that is in the ‘tweak' category which has been positive to my installations. The disk.schednumreqoutstanding value specifies a limit to the maximum number of outstanding disk requests to a specific LUN. The default value is 32, and for most situations is good enough. I have set this parameter to the maximum value (256) and have been very happy with the results. This value is set for each host in the advanced settings area (see Fig. 1).
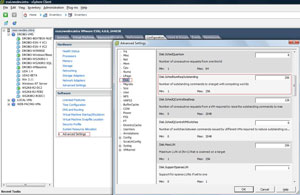 |
| Figure 1. This advanced value allows 256 requests to go to a single LUN. (Click image to view larger version.) |
I came across this somewhat obscure value from a number of posts from some of the best. EMC's Chad Sakacc's post on "VMFS – Best Practices and Counter-FUD mentions" this value, as well as VMware's Duncan Epping's post "Queuedepth and What's Next?" Even VMware KB article 1268 states that if you have more than one virtual machine per LUN, which most of us do, there can be benefits during intensive workloads.
Quantifying the value of this tweak will be up to you running a test before and after with an intensive workload. I know I liked what I saw, and it is in my standard configuration now.
Posted by Rick Vanover on 04/20/2010 at 12:47 PM0 comments
You think you know all of the hypervisors? How about this one: I recently took a tour of the
ScaleMP Versatile SMP (vSMP) hypervisor, which is interesting in that it's targeted to very high-performance workloads. The basic idea here is that commodity server equipment is aggregated together via a high-speed InfiniBand connection, either a switch or via a series of point-to-point connections. The vSMP hypervisor is targeted as a replacement for high-end compute environments in favor of replacing them with less expensive yet very powerful commodity servers. ScaleMP touts 60 to 80 percent cost savings over the supercomputer model with their vSMP hypervisor solution.
The vSMP hypervisor presents each local resource of the core technologies of a number of servers as an aggregated logical server. An example configuration would be 16 PowerEdge R710 servers, each configured with the new Intel Xeon 5500 (Nehalem) processors with two processors, 128 GB of RAM, 500 GB of disk space and four network interfaces. The vSMP hypervisor would aggregate those resources to provide a compute environment of 32 sockets (not even counting cores!), 2 TB of RAM, 8 TB of local disk and 64 network interfaces. This configuration would use an InfiniBand interface card connected to a switch as the interconnect mechanism. InfiniBand is still the most mainstream, high-bandwidth connection that is used in other technologies, such as virtualized I/O.
The local storage can be used, but the vSMP logical server can also connect to existing storage resources via fibre channel, NFS or iSCSI. It is interesting to point out that only a few of the servers would need to be connected to the SAN.
In the 16-host example, it may be a little overkill to have 16 mulitpath links to a SAN. This is because the InfiniBand backbone is a virtualized I/O channel for the logical server that can allow the logical server's connectivity to be right sized in all areas. Smaller solutions can be point-to-point in nature (see Fig. 1).
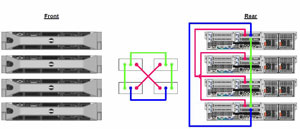 |
| Figure 1. The ScaleMP hypervisor connects commodity equipment via InfiniBand, shown point to point. (Click image to view larger version.) |
vSMP can scale to an incredible amount of aggregated capacity for one 'logical' server. What in the world would you run on this? High-performance systems such as enterprise data warehouse, business intelligence or modeling applications often require this type of performance.
Currently, ScaleMP supports a limited amount of hardware and software. Primarily, it's Linux 2.6.11 kernels and higher, including Red Hat Enterprise Linux 4/5 and Novell SuSE Enterprise Linux 10/11. ScaleMP is working to expand the operating systems that can be run on this platform by adding operating systems on top of the vSMP platform that do provide support for other operating systems via additional abstraction. The current compatibility matrix is also somewhat limited on hardware, but that too is an area for growth for ScaleMP.
The vSMP platform's three offerings are: vSMP Foundation for SMP, to create a basic, high-performance logical server; vSMP Foundation for Cluster, to add robust management to the high performance; and vSMP Foundation for Cloud, to work as a dynamic provisioning model for a private cloud infrastructure.
After a look at this aggregated logical server, short of calling it grid virtualization or Oracle RAC à la virtualization; it is very cool for the highest performing workloads.
What do you think of these very large logical severs? Share your comments here.
Posted by Rick Vanover on 04/15/2010 at 12:47 PM3 comments
As virtualization grows beyond the primary datacenters, opportunities arise to smaller IT footprints. Recently, I've started mentoring a few people in selecting a virtualization technology that is right for their needs. Some of these people read
my open-ended invitation to provide advice on how to get started with virtualization.
I find the hypervisor selection quite easy. It quickly becomes a decision process of what you are familiar with and what requirements exist for the infrastructure. For many small organizations, this is a fairly straightforward process.
Where it becomes sticky is when they're ready to select a storage product.
For a small environment consisting of seven or fewer virtual machines that have a nominal workload, a number of storage products can fit the bill. I've been working with, evaluating, researching and previewing storage solutions for these situations. Here is a roundup of a few storage products that I've been looking at:
Drobo: Last year, the DroboElite was released for the small and medium business as a more powerful option with additional connectivity for virtual environments. See this earlier post I wrote on the product. I like the built-in thin provisioning, adaptive RAID technology, sleek design elements and lack of concern for drive type to use. The DroboPro is similar.
SnapServer SAN S2000: Overland acquired the SnapServer series of products and has since offered a new series of products targeted to small storage requirements. The SnapServer SAN S2000 is an iSCSI storage device providing up to 120 TB. While that sounds very large (and it is), the architecture scales very high with today's inexpensive and large drives. The S2000 allows virtualization administrators to carve out RAID levels 0, 1, 5, 6, 10, 50 and 60. The equipment uses standard Intel Nehalem processors, but it is delivered on purpose-built equipment. The one issue I have with this storage platform is that if we are putting up to 120 TB on a SAN, it may be time to roll in a second controller for redundancy. The S2000 doesn't currently offer that functionality but may at a later date.
HP MSA P2000 G3: The Generation 3 iteration of the MSA 2000 Generation 2 brings in features to a product line that desperately can benefit from additional management. The MSA P2000 has one distinguishing feature that is somewhat unique for the price point: an iSCSI and fibre channel dual-personality functionality. This is perfect for my growing distaste of fibre channel switch and interface port costs. The dual-personality allows you to provision fibre channel storage to the hosts that need it, while providing iSCSI connectivity to the devices that need the lesser tier of throughput.
This is just a sample of storage offerings that can be relevant for the small virtualization environment. I'm looking into more and will share first impressions here.
Are you selecting storage for your smaller virtualization environments? If so, how do you go about deciding which products to use?
Posted by Rick Vanover on 04/08/2010 at 12:47 PM7 comments
For VMware vSphere environments, there is more to provisioning a disk than simply choosing thick or thin. Within the vSphere Client we are not given all of the information on how the disks are provisioned when they are created.
The distinguishing factor among virtual disk formats is how data is zeroed out for the boundary of the virtual disk file. Zeroing out can be done either at run time (when the write happens to that area of the disk) or at the disk's creation time.
The VMDK format, VMware's virtual disk format, is used in three primary ways:
- Thin Provisioned Disk: The thin virtual disk format is perhaps the easier option to understand. This is simply an as-used consumption model. This disk format is not pre-written to disk and is not zeroed out until run time.
- Thick Provisioned Disk (Zeroed Thick): The Zeroed Thick option is the pre-allocation of the entire boundary of the VMDK disk when it is created. This is the traditional fully provisioned disk format that we would use in the VI Client in previous versions. In the vSphere Client, this is the default option.
- Thick Provisioned Disk (Eager Zeroed Thick): This pre-allocates the disk space as well as each block of the file being pre-zeroed within the VMDK. Because of the increased I/O requirement, this requires additional time to write out the VMDK. This is also the required format for the FT virtual machine feature with vSphere.
Within the vSphere Client, the thin provisioned VMDK and eager zeroed thick options are displayed by checking the appropriate box. If the default option is selected (no boxes chosen), the VMDK format will be Zeroed Thick (see Fig. 1).
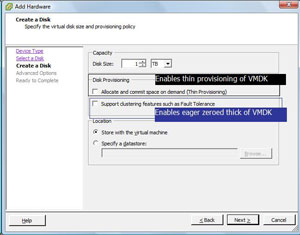 |
| Figure 1. Each VMDK option can be selected within the vSphere Client, including Zeroed Thick as the default format. (Click image to view larger version.) |
So, why is this important? For one, there may be a perceived performance implication of having the disks thin provisioned. The thin provisioning white paper by VMware explains with more detail how each of these formats are used, as well as a quantification of the performance differences of eager zeroed thick and other formats. The white paper states that the performance impact is negligible for thin provisioning, and in all situations the results are nearly indistinguishable.
Posted by Rick Vanover on 04/06/2010 at 12:47 PM0 comments
In a few circles in the virtualization community, some experts recommend stepping down the number of ports for virtual switches (vSwitch) in VMware vSphere, as well as VI3 installations. This was also evident in
a post last year where higher consolidation ratios may drive vSphere administrators to up the amount of ports on a vSwitch.
For VI3, a standard vSwitch has 56 ports assigned by default. From there, all of the guest virtual machines connect via their assigned port groups to that switch and decrement the port count one for one as the VMs have virtual network interfaces assigned. For vSphere, the default value stayed at 56 ports for a standard vSwitch but the new distributed virtual switch feature changes things a bit. Fig. 1 shows the default configuration for a standard vSwitch.
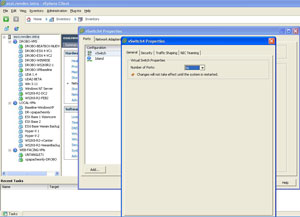 |
| Figure 1. The default configuration can be changed from 8 to 4088 ports on a standard vSwitch. (Click image to view larger version.) |
When the distributed virtual switch is used, additional configuration points as well as a higher default number of ports come into play. For the distributed virtual switch, a port group is assigned 128 ports by default.
In my virtualization practice for server consolidation, I’ve only had to configure the default values upward once where the consolidation ration exceeded 56 virtual machines per host. I realized this only when a virtual switch was put into maintenance mode, and migrations started to fail. In a simple example of a four-host cluster with 169 virtual machines, the default value of 56 ports per vSwitch per host wasn't sufficient with only one vSwitch in use.
The other side of the coin is to downward provision ports and to be as explicit as possible. The shortcoming of this practice is that the available values may not align to the desired quantity depending on the technology used. Take the example of three sensitive systems in a security zone that will not have additional virtual machines without a documented change. The issue is that vSwitch port counts go as low as 8 ports instead of 3 when using a standard vSwitch. If the new distributed virtual switch is used, explicit quantities such as 3 can be used.
Each requirement is different, but I’m leaning toward provisioning upward to avoid the stopping point that I hit once on a standard vSwitch. For distributed virtual switching, this can be complicated for larger clusters. I’ll take a play from storage practices to build it wide from the start and recommend creating a higher than default value for ports available for each distributed switch port group.
Posted by Rick Vanover on 04/01/2010 at 12:47 PM2 comments
Virtualization is a technology that can apply to almost any organization in a number of ways. The strategy that the small and medium business may use for virtualization would differ greatly from that of a large enterprise. Regardless of size, scope and virtualization technologies in use, there are over-arching principles that guide how the technology is to be implemented.
It is easy to get hooked on the cool factor of virtualization, but we also must not forget the business side. In my experience, it is very important to be able to communicate a cost model and a return on investment analysis for your technology direction. Delivering these end products to management, a technology steering committee or your external clients will be a critical gauge to the success of current and future technologies. Virtualization was among the first technologies that made these tasks quite easy.
The server consolidation approach is an easy cost model to make by outlining the costs for a single server's operating system environment (OSE) in the physical world, compared to that of the virtual world. It is important to distinguish between a cost model and chargeback, as few organizations do formal chargeback at the as-used level for processor, memory and disk utilization. While it seems attractive to have the electric company approach in billing for as-used slices of infrastructure, most organizations prefer fixed price OSE models for budget harmony. To be fair, there are use cases for as-used chargeback; I just haven't been in those circles.
So what does a cost model look like? What is the deliverable? This can be a one-page spreadsheet with all of the costs it takes to build a virtual infrastructure or it can be an elaborate breakdown of many scenarios. I tend to prefer the one-page spreadsheet that has the upfront costs simply divided by a target consolidation ratio. This will simply say what it takes to provide infrastructure for a pool of OSEs. You can then divide this to show what it may look like in the 10:1, 15:1 or higher consolidation ratios.
The next natural step is to deliver an ROI on virtualization technology. Virtualization for the data center (specifically server consolidation) is one of the easier ROI cases to make. Many organizations have not had the formal requirement to document an ROI; but it may be a good idea to do so. This will increase the likelihood of future technologies to work with virtualization as well as increase your political capital within the organization.
For an ROI model, you can simply compare the cost model of the alternative (physical servers) with the cost model of a virtualized infrastructure. For most situations, there will be a break-even point in costs. It's important to not over-engineer the virtualization footprint from the start yet set realistic consolidation goals.
An effective cost model and ROI can be created easily with organizations that are already using virtualization to some extent. For organizations that are new to virtualization, it is important adequately plan for capacity when considering migrating to a consolidated infrastructure. Check out my comparative report of three popular capacity planning tools to help make sure you don't under- or over-provision your virtual environment from the start.
How do you go about the business side of virtualization? Do you use formal cost models and ROI analyses in your virtualization practice? Share your comments here.
Posted by Rick Vanover on 03/29/2010 at 12:47 PM0 comments
Storage and related administration practices are among the most critical factors to a successful virtualization implementation. One of the vSphere features that you may be overlook is the paravirtual SCSI (PVSCSI) adapter. The PVSCI adapter allows for higher-performing disk access as well as relieving load on the hypervisor CPU. PVSCI also works best for virtual workloads that will require high amounts of I/O.
Configuring the PVSCI adapter is slightly less than intuitive, primarily because it is not a default option when creating a virtual machine. This is for good reason, as the adapter is not supported as a boot volume within a virtual machine. PVSCSI is supported on Red Hat Linux 5, Windows Server 2008 and Windows Server 2003 for use for non-booting virtual disk files.
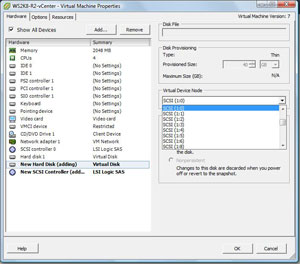
To configure the adapter, first review VMware KB 1010398 and make sure it is going to work for your configuration. The first step is to add another virtual disk file. During this step, you'll be asked which virtual device node to use. For non-boot volumes on most virtual machines, select a position higher than SCSI 1:0 (see Fig. 1).
 |
| Figure 1. The virtual device node outside of the first controller is key to using a PVSCSI adapter. (Click image to view larger version.) |
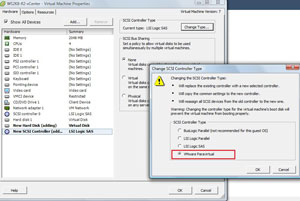
Selecting the higher value will cause the subsequent controller to be added to the virtual machine's inventory. Once the hard drive and additional controller have been added, the controller can be changed to the PVSCSI type (see Fig. 2).
 |
| Figure 2. Changing the type on the controller will enable the PVSCSI high-performance adapter. (Click image to view larger version.) |
At that point the guest is ready to use the PVSCSI adapter for the virtual drives that were added. I've been using the PVSCSI adapter and can say that it makes a measurable impact in performance on the guest virtual machine, so I will be using it in applicable workloads. The supported operating systems are listed above, but it is important to note that the PVSCSI adapter is not supported for use with a virtual machine configured for the Fault Tolerant (FT) availability feature until vSphere Update 1.
That is cool, but tell me something I don't know about vSphere features!
As a side note to the current vSphere features, it is also a good time to talk about future vSphere features. I had the honor once again to be a guest on the Virtumania podcast, where we received some insight to future vSphere features. In episode 4, special guest Chad Sakac of EMC explained some upcoming vSphere features, among them an offloading to storage controllers certain I/O intensive functions like deploying a virtual machine. If you have ever spoken with Chad, you know that the information he gives takes some time to absorb and set in. I recommend you check out episode 4 now.
Posted by Rick Vanover on 03/25/2010 at 12:47 PM3 comments
Last week, Microsoft announced a number of new virtualization technologies targeted at the desktop space. The additions are primarily focused on virtualized desktops, VDI and application virtualization. Somewhat of a footnote to all of this is that a new addition, dynamic memory, will apply to all Hyper-V virtualization, not just the desktop technologies.
Dynamic memory was featured at one point in the Hyper-V R2 product, but has since been rescinded as of the current offering. Its whereabouts has been a hot topic on VMware employee Eric Gray's vcritical blog and made rounds in the blogosphere.
The dynamic memory feature will apply to all Hyper-V workloads. It will work with a basic principle of a starting and a maximum allocation. The simple practice is to make the starting allocation the base requirement for the OS in question -- 1 GB for Windows 7 for example -- which is counter to what VMware's virtualization memory management technologies provides.
I had someone explain dynamic memory's benefits to me and the simplified version is that dynamic memory is an extension of the hot-add feature to allow more memory to be assigned to a virtual machine. Cool, right? Well, maybe for some and only if we think about it really hard. Consider the guest operating systems that support hot-add of memory. Doing some quick checking around, I end up with Windows Server 2008 (most versions), Windows 7 and Windows Server 2003 (Datacenter and Enterprise only).
The main thing that the enhanced dynamic memory will address is the lack of hot remove, which is a good thing. Basically, it is easy to do a hot-add, but what if you want to step it down after the need has passed? This is where the R2 features will kick in and reclaim the memory. I don't want to call dynamic memory a balloon driver, but it will automagically mark large blocks of memory as unavailable, which in turn will allow that memory be reclaimed back to the host.
One fundamental truth to take away is that Hyper-V will never allocate more than the physical memory amount. Any disk swapping won't take place in lieu of direct memory allocation.
Given that we don't have public betas yet, a great deal of detail still needs to be hammered out. Make no mistake: Microsoft's Hyper-V virtualization takes an important step in the right direction with the dynamic memory feature. It is not feature-for-feature on par with VMware's memory management technologies, but this increased feature set has sparked my interest.
Stay tuned for more on this. I and others will surely have more to say about dynamic memory.
Posted by Rick Vanover on 03/23/2010 at 12:47 PM1 comments
I have mentioned before that in my home lab, I use a DroboPro device that functions as an iSCSI target. It's a great, cost-friendly piece of shared storage that can be used with VMware systems. Recently, my DroboPro device failed, entering a series of reboots of the controller. I'll spare you the support experience, but the end result is that the company sent me a new chassis.
The Drobo series of devices support a transplant of the drive set to another controller. I followed the documented procedure, but ESXi was less than satisfied with my quick-change artistry. This is because the signature is different on the target. In the case of this storage controller, the new DroboPro controller is a different iSCSI target (though configured the same) path. From last month's "Which LUN is Which?" post, looking at the details on the full iSCSI name will show the difference. This means that when I pull in the specific volume (which was formatted as a single VMFS datastore), ESXi is smart enough to know that VMFS is already formatted on this volume.
In my specific situation, I have two VMFS volumes and two Windows NTFS volumes formatted on this storage controller (see Fig. 1), which ESXi recognized as VMFS volumes.
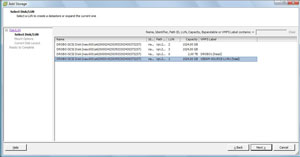 |
| Figure 1. Detecting the presence of the VMFS datastore is a critical step of reintroducing storage to the host. (Click image to view larger version.) |
We then have the option of keeping the existing VMFS volume signature, assigning a new signature or reformatting the volume. The text on the message box is less than 100 percent clear; chances are, people end up on this screen after some form of unplanned event (see Fig 2.).
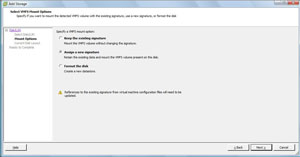 |
| Figure 2. The top option is the most seamless way to import the VMFS volume, whereas assigning a new signature requires intervention on the guest virtual machine. (Click image to view larger version.) |
Lastly you will be presented with the volume layout (see Fig. 3).
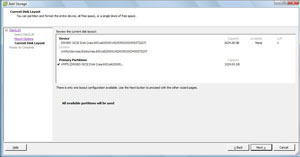 |
| Figure 3. This will summarize the volume layout before it is reimported into the host's storage inventory. (Click image to view larger version.) |
The final step is a host-based event called "Resolve VMFS volume" and the VMFS volume will reappear on the host. Virtual machines on that volume will have their connectivity reestablished to the datastore and be ready to go.
This is a scary process -- don't underestimate this fact. I did have a backup of what I needed on the volumes, but I was still more nervous than anything in this process. Hopefully if you have this situation you can review this material, check with your storage vendor's support and utilize VMware support resources if they are available to you.
Posted by Rick Vanover on 03/17/2010 at 4:59 PM0 comments
Last week, I had the honor of presenting at the
TechMentor Conference in Orlando. If you aren't familiar with TechMentor, you should be. Simply speaking, it is a track-driven series of training sessions brought to you by real-world experts on topics that everyone can use. Presenters this year included Greg Shields, Don Jones, Mark Minasi, Rhonda Layfield, and others.
In the virtualization track, we had a series of deep dives and technical sessions. The coverage very adequately represented Hyper-V and VMware, and it is tough to find good Hyper-V training from people that are actually using the technology.
I was pushing the VMware side heavily, but the natural conclusion is to make this seem like VMworld. TechMentor couldn't be farther from it. TechMentor is much more intimate and personal than VMworld. Sure, there are scores more attendees to VMworld. But, have you ever tried to stop and catch a quick conversation with someone at VMworld after a session? This isn't an issue at TechMentor, where the speakers are accessible.
This was my second year presenting, and one of the more popular sessions was my advanced conversion topic. I've maintained a running configuration of things I have learned over the years in performing physical-to-virtual (P2V) as well as virtual-to-virtual (V2V) conversions. The Visio diagram in Fig. 1 shows what can be a wonderful springboard for you to customize in your organization to collect lessons learned, avoid pitfalls with conversions and implement your own procedures, such as change controls and support contacts.
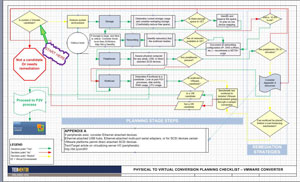 |
| Figure 1. This P2V flowchart allows you to go about your conversions with a procedural approach; note that this is one page; download the whole flowchart here. (Click image to view larger version.) |
I also presented three other sessions: data center savings with virtualization, virtualization disaster recovery, and virtualization-specific backups. It was a great time in Orlando, in spite of the rain, but I hope to be back next year delivering more good virtualization sessions.
Posted by Rick Vanover on 03/16/2010 at 12:47 PM9 comments
Last week, I had the honor of being one of the guests on the inaugural
Virtumania podcast. On the show we had
Rich Brambley,
Sean Clark (the guy with the hat) and
Mark Farley. Our topic was the VirtualBox hypervisor and what Oracle has in store with that and virtualization in general. Rich and I are avid users of VirtualBox in the Type 2 hypervisor space, and it was a good place to discuss how we use VirtualBox and where it fits in the marketplace. Here is a quick rundown of version 3.1.4 that have rolled into the product recently:
- Teleporation: This is a big one, as VirtualBox is the only Type 2 hypervisor that provides a live migration feature.
- Paravirtualized network driver: VirtualBox can have a guest virtual machine have a non-virtualized network hardware interface for Linux (2.6.25+) and select Windows editions.
- Arbitrary snapshots: This allows a virtual machine to be restored to any snapshot downstream, as well as new snapshots taken from other snapshots (called "branched snapshots" in VirtualBox).
- 2D hardware video acceleration: VirtualBox has always been somewhat ahead of the curve in multimedia support, and version 3.1 introduces support for Windows VMs to use hardware acceleration. The 3.0 release already added OpenGL 2.0 and Direct 3D support.
I still use VirtualBox extensively for my desktop hypervisor, but as far as what Oracle has in store for the end product, we don't yet know. We know that there is some form of product consolidation plans with Oracle VM in the works, but what specifically will be the end result is anyone's guess.
What we know for sure is that VirtualBox still is a good Type 2 hypervisor, and Oracle and company want to do more with virtualization. The polish and footprint in enterprises that Oracle and Sun have together are attractive. Consider further that the combined companies can provide servers, storage, hypervisors and operating systems. How much of that will end up in enterprise IT remains to be seen.
Posted by Rick Vanover on 03/11/2010 at 12:47 PM0 comments