How-To
Repairing a Failed AWS EC2 Windows Instance
Although EC2 is normally a reliable platform for hosting virtual machine instances, things can and sometimes do go wrong, and here Brien Posey explains how to fix problems with an instance's boot volume.
Although EC2 is normally a reliable platform for hosting virtual machine instances, things can and sometimes do go wrong. Occasionally for example, an instance's EBS volume may fall into an inconsistent state. If this happens to a data volume, then there are any number of tools that can be used to fix the problem.
In this blog post, I want to show you one possible solution for fixing such a problem. For the purposes of this discussion, I am going to be focusing on Windows instances, but you can use a somewhat similar technique to fix problems with Linux instances.
If you look at Figure 1, you can see that I have created two different Windows instances. Both of these instances are actually healthy, but for the sake of demonstration I named one instance Healthy and the other Unhealthy. We will pretend that there is a problem with the Unhealthy instance.
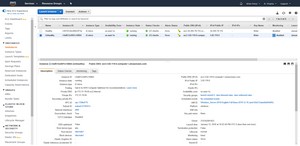 [Click on image for larger view.] Figure 1: We will use one of these instances to fix a problem with the other.
[Click on image for larger view.] Figure 1: We will use one of these instances to fix a problem with the other.
Before I get started, I need to tell you something really important. The screen captures shown in this article series show me detaching the boot disk from one instance, attaching it to another instance, and then using that secondary instance to do the repair. The reason why I am using the boot disk is just for the sake of simplicity. I wanted to avoid the confusion of having a lot of volumes to work with. In the real world though, the technique that I am about to show you should only be used on data volumes, not boot volumes. Performing this procedure on a boot volume will likely leave the instance in an unbootable state. It is also worth noting that this procedure assumes that the corrupt volume is a basic, unencrypted NTFS volume.
So having said that, let's assume that the "unhealthy" instance has a storage consistency problem. The first thing that we would need to do is to shut down the instance if it is still running.
The next step in the process is to figure out which EBS volume the unhealthy instance is using. One way of doing this is to go to the Elastic Block Store Volumes tab, and then look at the Attachment Information for the existing volumes. As you can see in Figure 2, the Attachment Information column lists the name of the instance that is attached to each EBS volume (although you may have to expand the column to see the instance name).
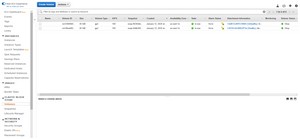 [Click on image for larger view.] Figure 2: The Attachment Information column lists the instance that is associated with each volume.
[Click on image for larger view.] Figure 2: The Attachment Information column lists the instance that is associated with each volume.
As you look at the figure above, one of the things that you may notice is that neither volume has a name assigned to it. Before you attempt to repair an inconsistent volume, I recommend assigning it a name. Otherwise it is going to become difficult to keep track of which volume went with which instance. If you look at Figure 3, you can see that I have named my volumes Healthy and Unhealthy, based on the instances that they are currently assigned to. While you are at it, make absolutely sure to make note of the device that the volume is attached to (in this case it is /dev/sda1). You will need to know this later on when you reattach the volume.
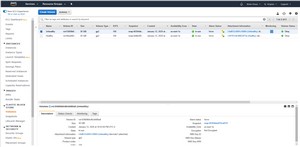 [Click on image for larger view.] Figure 3: It's a good idea to assign names to your volumes.
[Click on image for larger view.] Figure 3: It's a good idea to assign names to your volumes.
Now, detach the unhealthy volume from its instance, by right clicking on the volume and choosing the Detach Volume command, as shown in Figure 4. It is important to note that doing this will likely cause any suspended write operations to be permanently lost. It is also important to know that depending on how badly the volume is corrupted, the repair process may result in some data loss.
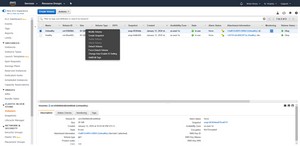 [Click on image for larger view.] Figure 4: Right click on the corrupt volume and select the Detach Volume command from the shortcut menu.
[Click on image for larger view.] Figure 4: Right click on the corrupt volume and select the Detach Volume command from the shortcut menu.
Once the volume has been detached, the next thing that you will need to do is to enable IO for the volume. To do so, select the volume, and then click on the Status Checks tab at the bottom of the screen. As you can see in Figure 5, the IO Status is currently set to Enabled. In a true failure situation, IO will most likely be disabled, so you will have to use an option on this tab to re-enable it.
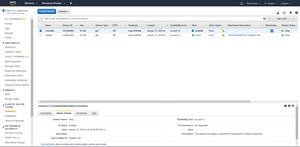 [Click on image for larger view.] Figure 5: Enable IO for the detached volume if necessary.
[Click on image for larger view.] Figure 5: Enable IO for the detached volume if necessary.
The next thing that you will need to do is to attach the volume to the virtual machine instance that is still functional. To do so, right click on the volume, and choose the Attach Volume command from the shortcut menu. When prompted, click on the Instance field, and then choose a healthy virtual machine instance, as shown in Figure 6.
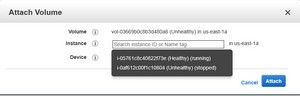 [Click on image for larger view.] Figure 6: Attach the EBS volume to a healthy virtual machine instance.
[Click on image for larger view.] Figure 6: Attach the EBS volume to a healthy virtual machine instance.
When you are done, you should see the unhealthy volume attached to a healthy virtual machine instance.
Now that we have attached the corrupt volume to another instance, it is time to repair the volume. I will show you how it's done in Part 2.
About the Author
Brien Posey is a 22-time Microsoft MVP with decades of IT experience. As a freelance writer, Posey has written thousands of articles and contributed to several dozen books on a wide variety of IT topics. Prior to going freelance, Posey was a CIO for a national chain of hospitals and health care facilities. He has also served as a network administrator for some of the country's largest insurance companies and for the Department of Defense at Fort Knox. In addition to his continued work in IT, Posey has spent the last several years actively training as a commercial scientist-astronaut candidate in preparation to fly on a mission to study polar mesospheric clouds from space. You can follow his spaceflight training on his Web site.