News
Google's Cloud AI Platform Pipelines Beta Simplifies Machine Learning Workflows
Google Cloud Platform (GCP) announced a new beta offering to simplify the deployment of complicated machine learning (ML) workflows that often have a lot of moving, interdependent parts.
Cloud AI Platform Pipelines can help organizations adopt the practice of MLOps, Google said of the term for applying DevOps practices to help users automate, manage, and audit ML workflows, which typically involve data preparation and analysis, training, evaluation, deployment, and more.
The new pre-release product -- which runs on a Google Kubernetes Engine (GKE) cluster -- comprises two major components, one consisting of infrastructure to deploy and run structured ML workflows integrated with GCP services, and one providing the pipeline tools to build, debug, and share pipelines and components.
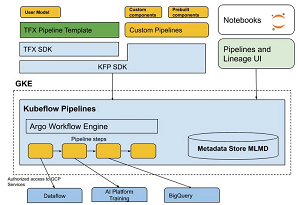 [Click on image for larger view.] The AI Platform Pipelines Tech Stack (source: GCP).
[Click on image for larger view.] The AI Platform Pipelines Tech Stack (source: GCP).
"Cloud AI Platform Pipelines provides a way to deploy robust, repeatable machine learning pipelines along with monitoring, auditing, version tracking, and reproducibility, and delivers an enterprise-ready, easy to install, secure execution environment for your ML workflows," said Google, which noted the product provides organizations with:
- Push-button installation via the Google Cloud Console
- Enterprise features for running ML workloads, including pipeline versioning, automatic metadata tracking of artifacts and executions, Cloud Logging, visualization tools, and more
- Seamless integration with Google Cloud managed services like BigQuery, Dataflow, AI Platform Training and Serving, Cloud Functions, and many others
- Many prebuilt pipeline components (pipeline steps) for ML workflows, with easy construction of your own custom components
Going forward, planned new features include:
- Multi-user isolation, so that each person accessing the Pipelines cluster can control who can access their pipelines and other resources
- Workload identity, to support transparent access to GCP services
- Easy, UI-based setup of off-cluster storage of backend data—including metadata, server data, job history, and metrics—for larger scale deployments and so that it can persist after cluster shutdown
- Easy cluster upgrades
- More templates for authoring ML workflows
Creation and management of the pipelines is done through the Google Cloud Console in a process explained in the announcement post.
More information is available in getting started documentation.
About the Author
David Ramel is an editor and writer at Converge 360.