How-To
Tips for Managing VDI, Part 7: Success vs. Failure
We have covered a lot of ground in this series of articles on VDI tips. There are many reasons why VDI implementations fail and succeed. In this last article I will point out one of the most important factors that can make it a success and talk about one of the reasons it failed in the early days.
Roll Out in Phases
Few successful VDI deployments are enacted using a "big bang" methodology, in which all users are converted to a virtual desktop in one fell swoop. I have found that most successful implementations take a gradual, organic approach to VDI implementations. Start with a few users, then expand it out to a small group of users, and then finally, after many of the kinks have been worked out, expand it to all of you remaining users.
 [Click on image for larger view.]
[Click on image for larger view.]
Using this multiphase methodology, it's possible to learn important lessons about the VDI users, the resources they consume and how to best manage the VDI system. Of course, during this process the VDI users and infrastructure should be monitored to ensure that it can meet the demands or handle any fluctuation in their workloads. This should be done over a period of time to ensure that it accommodates all their demands such as running end of the month reports.
By observing the actual consumption of resources and how it affects the end user experience, you can adjust the virtual hardware on the virtual desktops as needed in order to meet the user's expectations. Once these issues have been addressed you can move on to a larger group of users.
IO Storms
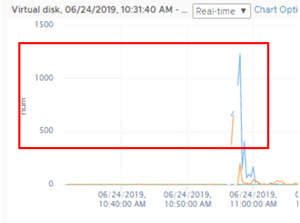
In the early days we saw a lot of VDI implementations fail and this gave VDI a bad name. The biggest issue we saw in the early days was known as an I/O or boot storm, when the storage simply could not keep up with demands put on it by VDI.
Commonly a desktop uses 10-20 IOIPs, but when a desktop boots-up it can take up to 1,000 IOPS. We also see an increased demand for IOPS during login, log offs and antivirus scans. This load when timed by tens or thousands of desktops brought a load that storage arrays could not satisfy, and unfortunately tarnished VDI's reputation.
 [Click on image for larger view.]
[Click on image for larger view.]
In the early days we dealt with I/O storms by pre-powering on desktops before workers arrived, but this didn't deal with the logon and logoff issue. We stripped the OS of unneeded services and drivers. These helped but didn't solve the root cause of the problem; traditional storage arrays could not supply enough IOPs to meet the needs of VDI.
To deliver the IOPS needed for an acceptable VDI experience a large number of HDDs were needed, and a large, costly storage array was needed to house them. This required a large upfront investment, and if the storage became unresponsive or failed, it would take out all the users that were running on it.
Complicating matters was that servers and storage systems were managed and administered by different departments which often had competing interests and priorities. Careful planning and coordination were required in order to deploy or change the resources allocated to the infrastructure needed to add more VDI users. Often these changes were disruptive, and the results were unpredictable.
Around this time, SSD drives emerged. Where an HDD drive delivers about 180 IOPS, an SSD can deliver about 5,000, meaning that it takes more than 25 HDD drives to have the same number of IOPS as a single SSD drive. When SSDs were first released they were expensive and traditional storage arrays didn't support them.
At the same time, and perhaps because of this hyperconverged infrastructure (HCI) emerged. HCI architecture uses software-defined storage (SDS) that utilizes the storage located on the HCI servers (nodes), meaning that storage and/or compute can be purchased and added seamlessly with single-node granularity. More importantly, both the storage and compute can be managed from a single console. HCI solutions were able to adopt SSDs much more quickly than storage arrays. But you didn't want to use all SSDs in your HCI nodes as they were more expensive and didn't have the capacity that HDD had.
In many ways, HCI is an ideal fit for a VDI environment as it allows growth to occur as needed without having to incur the large upfront costs required with a scale-up solution.
We seldom see I/O storms with modern VDI implementations. If we do, we have techniques and technologies to fix them.
Questions
For some reason I got some questions about I/O storms and HCI. Below is a sampling of these.
-
Q: What about virus scans?
A: All the major security companies have VDI versions of their products that deal with the I/O problem.
-
Q: Why not keep desktops always running?
A: A few reasons. A lot of early VDI implementations were in 7 x 24 call centers so the resources were pretty maxed out. Second, logons and logoffs can also cause a lot of I/O
-
Q: What about NVMe drives?
A: Yes, NVMe drives are becoming more prevalent and many storage arrays and HCI solutions use them.
Conclusion
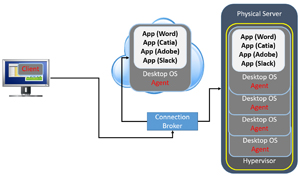
Remember that VDI is made up of many discrete components and we need to monitor them all in a holistic manner in order to ensure that it runs efficiently and that the end users have the best experience possible.
 [Click on image for larger view.]
[Click on image for larger view.]
In this series of articles, which is based on a session that I held for Redmond Magazine entitled EUC & VDI Management & Infrastructure Best Practices (available for on-demand viewing), I shared with you a few tips on ensuring that a corporation and its remote workforce have a good experience with VDI. However, these are just tips and suggestions, not firm guidance as each VDI implementation will have its own unique challenges that must be addressed individually. I do hope that you found this series of articles useful.
About the Author
Tom Fenton has a wealth of hands-on IT experience gained over the past 30 years in a variety of technologies, with the past 20 years focusing on virtualization and storage. He previously worked as a Technical Marketing Manager for ControlUp. He also previously worked at VMware in Staff and Senior level positions. He has also worked as a Senior Validation Engineer with The Taneja Group, where he headed the Validation Service Lab and was instrumental in starting up its vSphere Virtual Volumes practice. He's on X @vDoppler.