News
Firms Team Up for StarCoder2 'Open-Access' LLM, Here's What That Means
ServiceNow, Hugging Face and NVIDIA today released new open-access large language models (LLMs), the backing technology behind today's wave of generative AI breakthroughs like ChatGPT and all the Copilot AI assistants being used by Microsoft and GitHub.
Said to advance code generation, transparency, governance and innovation, the new StarCoder2 family of models were created in conjunction with the BigCode community, an open scientific collaboration dedicated to the responsible development and use of LLMs specifically tailored for code-related tasks. The project is managed by ServiceNow, which offers a cloud-based platform and solutions help digitize and unify organizations.
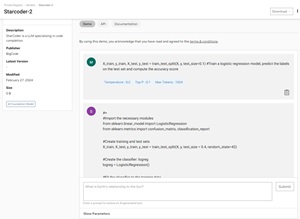 [Click on image for larger view.] An Example of the Starcoder2 Model Generating Code from the User Prompt (source: NVIDIA).
[Click on image for larger view.] An Example of the Starcoder2 Model Generating Code from the User Prompt (source: NVIDIA).
The new family of StarCoder2 models comes in three sizes:
- StarCoder2-15B: 15B model trained on 600+ programming languages and 4.3T tokens.
- StarCoder2-7B: 7B model trained on 17 programming languages for 3.7T tokens.
- StarCoder2-3B: 3B model trained on 17 programming languages for 3.3T tokens.
"Trained on 619 programming languages, StarCoder2 can be further trained and embedded in enterprise applications to perform specialized tasks such as application source code generation, workflow generation, text summarization, and more," the companies said in a news release. "Developers can use its code completion, advanced code summarization, code snippets retrieval, and other capabilities to accelerate innovation and improve productivity."
Following the trend of enterprise-specific LLM systems that can be integrated with company data (see GitHub Copilot Enterprise), users can fine-tune the open-access StarCoder2 models with industry- or organization-specific data using open-source tools such as NVIDIA NeMo or Hugging Face TRL, according to the release. "They can create advanced chatbots to handle more complex summarization or classification tasks, develop personalized coding assistants that can quickly and easily complete programming tasks, retrieve relevant code snippets, and enable text-to-workflow capabilities."
So What's an 'Open-Access' LLM?
While we have reported on "open-source LLMs" and "open-model LLMs," the term "open-access" LLMs is new to us. As things in AI are moving fast and new terms are being coined all the time, we wanted to confirm what the companies meant by an "open-access" LLM, especially as it compares to "open-source" LLMs and "open-model" LLMs.
We reached out and heard from NVIDIA, which provided the following explanation: " 'Open-access Large Language Model (LLM)' refers to a language model that is freely available for anyone to use or access, typically for research, development, or application purposes. 'Open-source LLM' allows for free access but also provides the source code. For StarCoder2, the license includes restrictions that apply to modifications of the model and applications using the model, including restrictions on distributing malicious code."
We also reached out to ServiceNow, which weighed in with this:
Here's how we differentiate between open-source, open-access, and open-model LLMs:
- Open-source: In the purest definition, open-source LLMs have no use case restrictions i.e. available for download and can be used in any way
- Open-access: Looks and feels the same as open-source LLMs, but open-access models have some use case restrictions i.e. available for download but cannot be used to cause harm
- Open-model: Publicly available for inspection and use (vs. a proprietary model that cannot be download or inspected for evaluation and training)
StarCoder2 is a family of LLMs that are open-models with open-access licenses, making it a good resource for enterprise engineers and developers who must comply with governance policies. Most open-access licenses are only available for research purposes, but StarCoder2 allows royalty-free commercial use.
The term "open model" for LLMs was popularized by BLOOM, as noted in a MIT Technology Review article that said: "Unlike other, more famous large language models such as OpenAI's GPT-3 and Google's LaMDA, BLOOM (which stands for BigScience Large Open-science Open-access Multilingual Language Model) is designed to be as transparent as possible, with researchers sharing details about the data it was trained on, the challenges in its development, and the way they evaluated its performance."
BigCode itself provided a description of the term in a 2023 scientific paper about about the new LLM's predecessor, StarCoder. The paper, titled "StarCoder: may the source be with you!," says:
Numerous open-access LLMs have been released to the AI community, although they are generally not as strong as closed-access ones. In this paper, we use the term "open-access LLM" when the model weights are publicly available. We still note that there are significant differences between open-access models in how transparent they have been about the training data and filtering techniques.
A 2023 article on the Width.ai site concurs: "Open-access LLM: Open access here means the model weights are available publicly on Hugging Face, GitHub, Google Drive, or similar services. However, it doesn't automatically imply that you can use the model for commercial purposes; many models only permit research or personal uses."
'Open-Model' LLMs
While the concept of complete open-source LLMs is pretty clear, we just last week reported on Google putting its advanced Gemini AI tech into a new "open-model" Gemma offering, with the purpose of helping developers build AI responsibly.
"Open models feature free access to the model weights, but terms of use, redistribution, and variant ownership vary according to a model's specific terms of use, which may not be based on an open-source license," Google said in a Feb. 21 post. "The Gemma models' terms of use make them freely available for individual developers, researchers, and commercial users for access and redistribution."
So, with all that straightened out, stay tuned to see what the next model for LLMs is.
About the Author
David Ramel is an editor and writer at Converge 360.