VMware's vSphere 4.1 release has a slew of new features. Some of them are interesting more than others. There is one central theme, ESXi. This 4.1 release is the last one of ESX, so now is the time to make a migration plan to ESXi. VMware has created the ESX to ESXi
upgrade center Web site to help you with it. The single, most attractive feature with ESXi 4.1 is the built-in Active Directory integration to the host. This is great for environments where identity needs to be managed all the way back to the user, and using root isn't the right answer.
A bunch of other features such as vscsiStats, tech-support mode for authorized users (other than root), and boot from SAN are now available.
One new feature that may be attractive to some environments is Total Lockdown. It's a feature that forces all host management to be performed through vCenter. The direct console user interface (DCUI) or yellow/grey screen is available in this configuration, but there is an option to disable the DCUI. So, now it is possible to not be able to manage the host from the ESXi perspective. Out-of-band mechanisms like virtual power buttons (on the HP iLO and Dell DRAC) can shut down the ESXi server, though ungracefully.
Administrators will be happy to hear that we can now do four concurrent vMotion events on 1 Gigabit Ethernet networks. Should 10 Gigabit Ethernet be in use, this number increases to eight concurrent vMotion events.
I'm not exactly crazy about the version 4.1's memory compression feature. The compression of the memory pages before swapping makes for a more efficient transfer in and out of swap space, but like many administrators I find myself well-provisioned on memory resources. In fact, in most environments I'm not even overcommitting anymore, thanks to favorable RAM costs for servers compared to a few years ago. I'm also somewhat irked that we do not have a fix to the PVSCI driver that is coming in Update 3, but this is only affecting a small number of installations.
Overall, I'm happy for the release and will be swiftly upgrading all environments. How about you?
Posted by Rick Vanover on 07/13/2010 at 12:47 PM5 comments
Like many virtualization administrators, I strive to keep my hypervisor up to date. But, what about updating the lowly server itself? Sure, the hardware is a commodity nowadays; yet this can never be overlooked.
All of the major server vendors have firmware updates for the hosts that we use for VMware ESX, ESXi, Hyper-V or other platforms. It is especially important considering that if you contact your hardware vendor for support, the first thing they will request os that you update your servers. Do you stop at the servers? Not really.
Keeping updated also applies to the storage controllers and hard drives of your SAN for your virtual infrastructure. This is a much trickier and less than comfortable experience for storage that is in use. Servers, on the other hand, update very painlessly with vSphere's maintenance mode or Hyper-V live migration.
Updating the Hyper-V server is easy, as the Windows online firmware updates will run seamlessly. For ESX and ESXi systems, you'll likely need to reboot the host into a special environment to update the drive. You can do this either with a boot CD-ROM or USB key that loads a special environment just for updating the firmware (BIOS) of the server. For VMware ESXi systems, you can check your BIOS level without rebooting the server by logging directly into the host, as in Fig. 1 (you can't do this through vCenter, ironically).
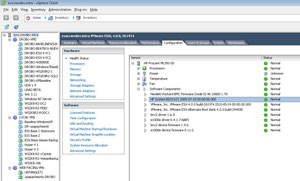 |
Figure 1. With ESXi, you can check your BIOS level without rebooting if you log directly into the host. (Click image to view larger version.)
|
In this example, I can determine the date stamp for the BIOS type (D21) in the case of this server, which is the current rev of the BIOS.
The server makers put a lot of effort into the QA process for BIOS and firmware development for servers and storage. This was evident at the recent HP StorageWorks Tech Day where were given a peek into part of the firmware test process for servers and storage.
Posted by Rick Vanover on 07/08/2010 at 12:47 PM10 comments
Last month on Virtumania podcast #16, "
The one about vExperts and VMworld," we talked about VMworld. It's a good reminder that VMworld is right around the corner. The event will be markedly different in 2010 than other years.
The first change is how sessions will be offered and scheduled. The new arrangement as I understand it will be that there will be fewer sessions offered more frequently. This is in response to attendee feedback that they can't get the sessions they want to attend.
The second change is that the two VMworld events are scheduled close to each other. VMworld in San Francisco is Aug. 30 through Sept. 2 and the Europe show in Copenhagen runs from Oct. 12-14. Historically, VMware has worked to have some major announcement at each event. With the events scheduled close to each other, that pressure is reduced.
I'll be at VMworld in San Francisco this year and I'm coming with a new perspective on the event. Basically, I'm of the opinion that we are at a make or break point with Hyper-V virtualization. VMware's server virtualization market share can only go down. This is somewhat unfortunate because I still think VMware has the superior solution, yet history has shown that Microsoft in the long run will win. I can very clearly remember how Novell NetWare (version 3!) was a superior product to Microsoft for file serving, yet the market went in Microsoft's direction. Application support was ultimately the killer for NetWare; I am watching the market carefully nowadays.
Aside from my soapbox rant, I am looking forward to VMworld. Primarily, I think the partner ecosystem for VMware is maturing, and I'm excited to see what is available in person.
Will you be attending VMworld this year? What do you look forward to at the event? Share your comments here.
Posted by Rick Vanover on 07/07/2010 at 12:47 PM1 comments
When it comes to adding small tweaks to a vSphere environment for performance gains, you can count on me to find little nuggets of information to keep the infrastructure continually fined tuned.
Recently, one of the basic features of VMware's Distributed Resource Scheduler (DRS) came up as a reminder to help virtual machines perform better. One of DRS's features is the ability to set separation or combination rules. Historically, I'd use a separation rule to keep virtual machines spread around so that should one host go offline, the impact is not too great.
DRS combination rules, or "keep together" configurations as they are called in DRS, can be just as helpful. You see, if you configure a DRS rule to keep one or more virtual machines on the same host; you may in fact lead to a substantial performance gain.
Take, for example, a client-server application that has clients that connect to a Web server that interacts with an application server and a back-end database server. If all three virtual machines (Application, web and database) are configured with DRS to be on the same ESX or ESXi host, you can greatly increase the intra-VM traffic between these systems.
When VMs are on the same host, the VM to VM traffic does not use the physical switch ports to send network traffic. This traffic doesn't actually leave the virtual switch, and thus will use CPU cycles for network traffic. I won't quantify my results, but will say that it clearly leads to increase overall application performance when they each have this benefit.
The DRS rules are configured as part of the cluster settings (see Fig. 1).
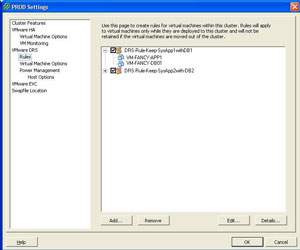 |
| Figure 1. Configuring DRS rules as part of the cluster settings via this dialog. (Click image to view larger version.) |
Using DRS rules to keep virtual machines together complicates things in a sense. The primary complication would be, the loss of a host would fully impact the application. Conversely, the entire solution may be rendered useless should one of the components be offline anyways.
A smaller issue may arise by using DRS rules in that it complicates the DRS algorithm, although vSphere is enterprise-class and it should not be an issue.
As a general recommendation, overly complicated DRS rules are likely not a best practice, as things can get complicated in larger clusters and in situations where host capacity is reduced.
Have you noticed DRS combination rules helping out VM-to-VM performance for applications that contain multiple VMs? If so, share your experience here.
Posted by Rick Vanover on 06/29/2010 at 12:47 PM1 comments
I have mentioned in a number of posts on the "Everyday Virtualization" blog how I favor ESXi over ESX for hypervisor selection. This is due to VMware's clear strategy that ESXi is the preferred platform going forward. Within the vSphere Client, the experience is virtually indistinguishable from ESX. If you need to retrieve logs from the ESXi host, these can still be via the vSphere Client with the familiar
generate diagnostic bundle task.
While VMware for most situations will point administrators to the vSphere Client for tasks like this, techies like you and I still want knobs to switch and dials to turn. The ESXi host has log files, though slightly different than what you may have worked with in ESX. There are three main log ones for ESXi:
- vpxa.log: Located in /var/log/vmware/vpx/ for vCenter agent (vpxa)
- hostd.log: Located in /var/log/vmware/ for base ESXi log
- messages (no file extension): Located in /var/log/
Ironically, I observed that the hostd.log's first line reads "Log for VMware ESX, pid.." even though it is ESXi. Getting to the log files can be done a number of ways. One of the two ways that I will share to access the logs is to use my previous monthly how-to tip on how to use the command line interface for ESXi.
The second and likely the easiest way to get direct access to log files is to use the built-in host Web transfer engine. If you browse to https://esxi.rwvdev.intra/host (esxi.rwvdev.intra is my ESXi host, insert your host name here) you can access the critical files on the host using local authentication (root or other users set up; see Fig. 1).
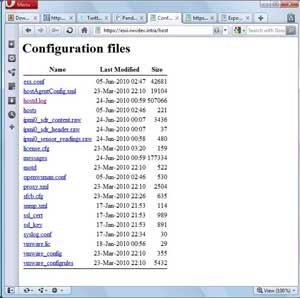 |
| Figure 1. A Web page for my lab system hosted at ESXi. (Click image to view larger version.) |
Note that I do not have the vpxa.log file listed, as the host is using the free ESXi and does not have the vCenter agent installed.
Deciphering the logs is an entirely different beast compared to Windows or application logs that you may be familiar with. The best resource to decipher these logs is the VMware Communities family of Web sites, as well as any active support contract with VMware that you may have for your installation base.
Do you use these two ways to access the logs most frequently? Or do you also use the centralized options, PowerShell tools, host screen or other mechanisms? Share your comments here.
Posted by Rick Vanover on 06/24/2010 at 12:47 PM2 comments
I always find it fascinating when a technology company reveals some of its internal practices on any infrastructure segment that is of interest to me (see "
What we can learn from the big boys"). Recently, I came across a Microsoft resource on how they have adopted Hyper-V with Windows Server 2008 R2 in one of their internal IT infrastructure teams that supports the Microsoft.com Web presence. The
TechNet page outlining how the Web presence was moved to Hyper-V has a nice document outlining the infrastructure and operational practices as well as a video.
Though the material is presented to show that Microsoft is not immune to virtualization challenges with infrastructure that you and I face, I take a few issues with the points raised. Primarily, Microsoft has one fundamental advantage to almost everyone else in the world: Microsoft licensing costs. I would assume that Microsoft's internal licensing costs are much less than that of the rest of the world, and possibly zero. This is a big distinguishing factor that isn't raised in the material.
The other thing I take issue with is that at one point in the video, it is mentioned that Live Migration with Windows Server 2008 R2 with Hyper-V is the centerpiece of a private cloud offering. Migration as a centerpiece? I had to listen to that section twice.
But the one thing I really was scratching my head on the most was the concept of a maintenance node. In their blade server implementation, one of the 16 blade server hosts was allocated to the role of a maintenance node. This presented 15 active hosts in the blade enclosure once the maintenance node was accounted for. This is a fundamental difference than my VMware background and I've never done anything like that, but I do see the operational benefit to have extra capacity on demand for maintenance. It isn't additional available for extra compute capacity or memory, however.
There are plenty of good nuggets in the material. One section links to how Microsoft maintains high availability for the Microsoft.com Web site architecture. These are good design principles that anyone can roll into their environments. Of course, we all cannot design to the level of the Microsoft's of the world, but it is nice to know how they do it.
What is your impression of Microsoft's implementation for Hyper-V for Microsoft.com?
Posted by Rick Vanover on 06/22/2010 at 12:47 PM5 comments
This week I had a chance to peek into the world of storage for virtualized infrastructure during HDS Geek Day, a series of briefings from Hitachi Data Systems. (Disclosure: HDS Geek Day was an on-site blogger event in San Jose, Calif. Read my full blogger disclosure here.)
As a blogger, I came in with an open mind and no preconceived notion about HDS storage products. What I do know, however, is that my short list of top-notch storage bloggers knows a lot about HDS and generally speak well about them. This includes Devang Panchigar, Chris Evans and Nigel Poulton; all of whom were at the event.
One of the sessions in day one that discussed some future technologies around HDS's vision for virtualization caught my attention, and it's not available in the form of a product yet. The idea was to leverage storage technologies for storage efficiency for multiple virtual machines versus a technology like linked clones or primary de-duplication. This session was presented by Miki Sandorfi, chief strategist for file and content services at HDS.
What caught my attention was to have integration with the virtualization stack to use storage technologies to provide disk usage efficiencies that would work with all virtualization products. This integration would use storage snapshots and virtual disk versioning to provide storage savings that resemble de-duplication on disk.
This object store versioning technique would use snapshots and versioning on the storage system to provide disk usage savings for virtual machines. The obvious example is a VDI implementation where the source disk is very similar. There would not be delta VMDKs or differential VHD files, only versions of the file system object and shapshots.
Do you want your storage managing the differential data sets of virtual machines (desktops or servers), or would you want the virtualization engine to manage the task? Share your comments here.
Posted by Rick Vanover on 06/17/2010 at 12:47 PM4 comments
VMware has a
feature suggestion mechanism, but just ask
Jason Boche if he feels that this vehicle is effective.
I've got a few wish list items that I'd like to see in VMware vSphere. These are based primarily on day-to-day tasks coupled with a preference to do everything in the vSphere Client. I'd like to see vSphere offer the following:
Storage vMotion to allow single VMDK migration and change to thin-provisioned discs. This can be done with PowerShell finesse, and a single VMDK migration can be done with the SVMotion remote command-line option, but we are at a point where it should be available in the vSphere Client. Ironically, the Andrew Kutz plug-in for VI3 did allow this functionality sans the thick-to-thin options.
FT virtual machines to protect against single instance storage. This is quite the lofty wish, but I would love to see FT functionality include an option to replicate storage to another VMFS data store. Ideally, this datastore would be on a separate storage controller or storage network. While FT protects at the host level, we are still locked on the single instance of the virtual machine on the storage. In my dreamboat armchair architect mind, it is a modified version of existing storage migration and changed block tracking features. To be fair, some hairy topics will arise when dealing with logical issues (array parity errors) on the storage system compared to hard failures.
Improved free virtualization offering. I'll make it very simple: Citrix and Microsoft have superior free virtualization offerings. There is definitely a market for free virtualization, and it does lead to bigger virtualization implementations. On a recent Virtumania podcast, Gartner analyst Chris Wolf and I agreed that the free offering by Citrix and Microsoft are leading in this category. In my dreamy world of an improved free offering, I'd see vCenter manage multiple hosts and virtual machines without all the features of the licensed editions.
Crawl the Microsoft stack. System Center and other Microsoft offerings are crawling around in VMware environments. Is it time to return the favor? To be fair, it would be a tremendous task to select applications and operating systems to manage within vSphere as well as a monumental political storm. This could include integration with Microsoft Clustering Services to fail-over systems based on infrastructure events.
Just ideas for what vSphere could do better.
What ideas do you have for vSphere and have you shared them in the online forum? Share your comments here.
Posted by Rick Vanover on 06/15/2010 at 12:47 PM5 comments
I'm always on the prowl for virtualization tools and tweaks that can give the administrator better insight into their virtual environment. VKernel has released
StorageVIEW to provide insight into datastore utilization for VMware environments. It queries vCenter, ESX and ESXi hosts to give datastore latency for the five datastores with the highest latency. StorageVIEW also shows datastore throughput per virtual machine (see Fig. 1).
StorageVIEW queries the ESX or ESXi hosts for this data directly and is not very aggressive in its polling interval. It has all of the markings of being an application that runs on a dedicated system (or at least dedicated monitor) to give a visual green or red indicator for the busiest datastores based on the thresholds configured.
One additional plus for StorageVIEW is that you can run it from your desktop (Windows XP, Vista, 7, etc.) and pass explicit permissions to the host or vCenter Server. Even with the configurable thresholds, StorageVIEW doesn't do too much other than change the color of the associated datastore. This isn't the tool to have e-mail alerts, pages or automatic Storage vMotion events to evacuate a datastore.
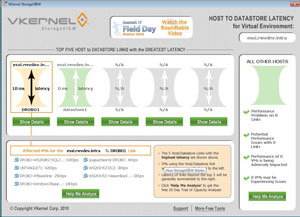 |
| Figure 1. StorageVIEW provides a view of the datastore throughput on the VMs on my ESXi system in my lab. (Click image to view larger version.) |
The tool also works with the free ESXi server installation. Be sure to get this tool while you can to see if your datastores could be rearranged based on this information. Too frequently, virtualization administrators put virtual machines on datastores solely based on storage consumption in terms of GB on disk (even I am guilty here). In effect, we're only approaching storage for vSphere in a unidirectional fashion by focusing on free space.
While StorageVIEW is free to give a peek into what is going on per datastore, it should not be the only tool used to see how you are doing on your storage. But for something that's free, it does a good job reporting where the host is at. StorageVIEW is available for download from the VKernel Web site.
Posted by Rick Vanover on 06/15/2010 at 12:47 PM1 comments
In virtualization circles, conversations usually go like this: "What's your name?", "Where are you from?" and the much harder to answer question of "How are you using virtualization?"
When it comes to describing virtualization in terms of virtualized desktops and servers, it can be tricky. Desktops can logically be defined as a group such as a call center or remote workforce. Quantifying server virtualization can be easy or not easy. I'd love to say that I am 100 percent virtual for all servers, but I can't quite say that.
What I can do is quantify my percentage of virtualized servers in terms of eligible systems. It is easier to determine an eligible system by defining an ineligible system. An ineligible system is one that cannot be made virtual for one of the following reasons:
- The application vendor does not support virtualization. They are out there, unfortunately.
- A piece of hardware which cannot be virtualized. USB devices can be virtualized, however.
- The server is located in an environment (data center) that does not have a virtualized environment available to it. The best example in this case is a remote site with a limited infrastructure footprint.
With these ground rules, I will make statements like "I am one system away from being 100 percent VMware virtualized in data center X for all eligible server systems." In most situations, infrastructure heroics can't change the hard-stop issues of the above three scenarios with the exception of the small data center. It doesn't make sense to me yet to have a hypervisor with one virtual server on it, even with direct attached storage. A remote site with two servers is a different story.
How do you answer the question: "How virtual are you?" Share your comments here.
Posted by Rick Vanover on 06/10/2010 at 12:47 PM4 comments
For many virtualization implementations that were installed a year or two (or three!) ago, you may now have an opportunity to give a mid-life boost with a memory upgrade to the host hardware without breaking the bank. Back then, the purchase price of a server with a large amount of memory could break the virtualization model.
It is always a good idea to check prices on small upgrades for the host infrastructure. Based on list prices, you can add about 1 GB of RAM for about $50 for many common server models. Of course, this depends on the type of slot availability on each host server. We still see 8 GB memory modules commanding a premium, but 4 GB modules are quite affordable. I use the Crucial store all the time to quickly get a street price on memory for the particular server in question. These prices closely align to HP, Dell and IBM prices, as they may source their material from Crucial. I have also purchased server memory from Crucial on numerous occasions and it has always worked for me first time.
When memory is added to a host, you should do a burn-in test of the new modules for about 24 hours. An ESX or Hyper-V host will use memory in the system in a more comprehensive way than a traditional application server, so you want to ensure you do not have any issues from the start. In fact, VMware says that most of the Purple Screen of Death (PSoD) messages are due to bad memory modules.
Since Windows Server 2008 has become a mainstream product, we see more virtual machines with a higher memory requirement. The Standard version of Windows Server 2008 R2 can have a maximum memory allocation of 32 GB. For Windows Server 2003 systems (still very prevalent in the data center), the maximum memory allocation for the x86 Standard Edition is 4 GB, much to the secret rejoicing of virtualization administrators.
In my virtualization practice, I keep getting an upward push in memory requirements. Do software vendors really need their products to have 8 GB, 16 GB or more memory? I will provision to the supported requirement, but closely monitor usage. After that, all bets are off!
Have you given your VMware or Hyper-V hosts a memory boost mid-life? I've done it a few times and it is a good way to boost host capacity without adding hosts and licensing, especially in light of the current guest operating system landscape.
Posted by Rick Vanover on 06/08/2010 at 12:47 PM5 comments
VMware's HA feature is good enough for most availability solutions, but it has caused me more grief than benefit over the years. The VI3 era product had some issues that caused virtual machines to reboot, and even on vSphere we still find ourselves reconfiguring a host for HA when minor errors occur.
All of that I can live with, but what really has burned my stomach over the years is the invisible inventory that is reserved with admission control. Admission control is the overhead that is reserved, which I refer to as invisible; to provide the compute and memory capacity to pick up the workload on virtual machines that are disconnected from a host.
Admission control is a complicated beast with the default settings being 'good enough' for most installations. If you have a small cluster, you may find yourself running up into brick walls, where admission control prohibits you from powering on additional virtual machines.
In those situations, it is time to consider two key configuration points. The first is to set HA rules that specify which virtual machines are to be powered on in an HA event. There can be clear examples, such as development systems not being set to power on during an HA event.
The other strategy is to set custom admission control values on the cluster's HA settings (see Fig. 1).
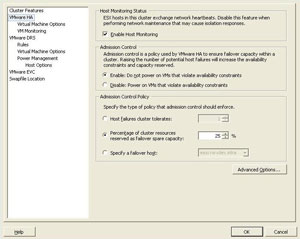 |
| Figure 1. Customizing the admission control value can allow you to reserve a designated amount of capacity in the HA cluster. (Click image to view larger version.) |
You have two options for setting HA admission control options: percentage of cluster resources and specifying a failover host.
In the case of a smaller cluster, you may find yourself wanting to go the percentage route. This way a single host, which may represent 50 percent, 33 percent or 25 percent of the total available compute and memory capacity contained in a two-, three- or four-node cluster, respectively. A single host reserved in the invisible inventory associated with admission control is a significant hit to the total resources without a break in your licensing costs. If individual virtual machines are assigned an HA action and a percentage of cluster resources is set for HA admission control, you can configure the reserved inventory to be more in line with your requirements.
Likewise, if you have a larger cluster that may include servers of mixed configuration (faster processors or more RAM), you may want to designate a specific host to act as the failover node.
The default option of one host failure to reserve for an HA event can be overly cautious for many environments. If admission control errors start to show up, reconfiguring HA in one of these two ways coupled with individual virtual machine response configurations will address these limits.
Posted by Rick Vanover on 06/03/2010 at 12:47 PM2 comments