For a good part of this year, I have been part of a tremendous opportunity to see a virtualized storage platform come to existence. This week, Hitachi Data Systems released the Hitachi
Virtual Storage Platform. The VSP platform is an enterprise storage platform of extreme scale, with a maximum configuration offering 255 PB in six racks.
Virtualized storage is a great way to extend the virtualization initiatives that have made many heroes in datacenters around the world. As the VSP product was launched, there was a clear priority to reflect the infrastructure trends of today's datacenters. The VSP was designed to integrate with virtualization technologies such as VMware vSphere and Hyper-V.
VSP does not support VMware's vSphere API's for Array Integration at the release, but an incremental software update is scheduled for later this year. This isn't exactly a surprise as many of the storage products that are in the VAAI program are in the “announced support” stage versus “available now.” A few products had VAAI support for storage products ready at the vSphere 4.1 release including the modular storage offering from HDS, the AMS 2000 line. A handful of other storage products were ready from the start, with a few more making announcements for support by the end of the year having participated in the VAAI program with VMware (see my post on VAAI). A vCenter Plug-In for the VSP will be released soon.
In the course of seeing the VSP become a product, I had an opportunity to meet with engineers and product managers to understand the priorities for creating a new virtualized storage system.
The VSP took a new approach to a number of items related to virtualization, architecture and software. Aside from the upcoming VAAI support, the VSP focused on creating a series of virtualized components through the system. Enterprise storage systems such as the VSP and its competition have a number of components and interconnections that are critical architectural factors in the scale and performance of the system. For example, the VSP utilizes commodity processors (Intel quad core) on the storage directors (back end and front end) which are a big improvement over the preceding ASIC architecture. VSP can also provide automated storage tiering at the entire volume or sub-volume level with Hitachi Dynamic Tiering. This can be incredibly beneficial if a virtual machine creates a hot spot on disk and needs to be prioritized to another tier of disk when vSphere's Storage I/O control can't meet the needs of the virtual machine.
What I learned is that virtualized storage is going to only become more important in any large virtualization strategy. I'm quite excited to see what will be coming in the next iteration of VAAI features and how the virtualized storage landscape changes with new products for the current needs of the virtualized datacenter.
Note: I attended blogger events sponsored by HDS, which are governed by my official blogger disclosure.
Posted by Rick Vanover on 09/30/2010 at 12:47 PM1 comments
I'm still digesting the material I got at VMworld 2010 . The show had two over-arching themes: cloud and VDI. It's not entirely surprising, as these are new segments for VMware and the larger virtualization market. While those are good things to focus on, I and others still need to focus on the virtual machines we have in use.
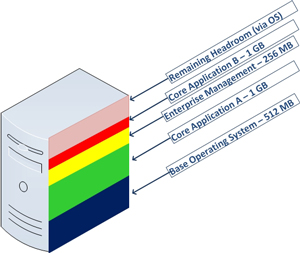
Virtual machine memory management is still one of the most tactical areas of virtualization administration. Something I'm watching closely is how new operating systems will impact my daily practice. My practice mainly revolves around Windows-based virtual machines, and Windows Server 2008 R2 is the server operating system of choice. Too many times applications give a generic list of requirements, and infrastructure administrators are left making decisions that may impact the overall success of the installation. One strategy is to identify what the memory would look like on a new virtual machine in terms of slices that represent each requirement. Fig. 1 shows a sample virtual machine with two core applications.
 |
|
Figure 1. Having a visual representation of the memory requirements is a good way to plan what the virtual machine memory may look like. (Click image to view larger version.) |
It's an incredible challenge for a virtualization administrator to provision exactly what memory is required, yet balance headroom within the guest for unique workloads. We also have to be aware of the host environment. It very well may be that in a year the application's requirements may double, thus the performance and resource requirements may double as well. Fortunately, server virtualization allows ease of scale in most areas (CPU, disk, network) but memory can be more tricky to implement. Memory is relatively inexpensive now, but that may not be the case forever and we may end up flirting with host maximums for older Hyper-V or VMware vSphere hosts.
The takeaway is to give consideration to each operating system's limits. This will impact what headroom would be available for a guest virtual machine as well as the aggregated impact on the host. A few years ago, administrators dodged a bullet with Windows Server 2003 Standard (x86) having a 4 GB limit for a virtual machine. For Windows Server 2008 R2 Standard edition, the limit is now 32 GB. It is possible that applications that are replacing older servers running Windows Server 2003 to now require double, triple or more RAM than the previous systems. Luckily, a number of virtualization tools (many of them free) can aid the virtualization administrator in this planning process. This MSDN resource has memory configuration maximums for all versions of Windows.
Virtualization administrators should pay special attention to the limits, requirements and aggregate memory capacity with insight to future needs. For this aspect of workload planning, what tools (free or not) do you utilize to assist in this process? Share your comments here.
Posted by Rick Vanover on 09/28/2010 at 12:48 PM7 comments
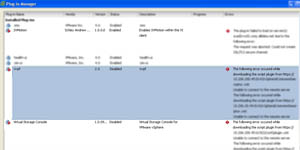
One benefit of vCenter is the plug-in framework, which allows a rich ecosystem of partner software to be installed in the vSphere Client and work with vSphere. While most installations will automatically install a vSphere plug-in, you may be pondering on how to remove them. This is important as many software programs are used on an evaluation basis or any carryover plug-ins from a vCenter 2.5 to 4.0 upgrade. It's easy to find a stale plug-in by viewing the Plug-In Manager .
 |
|
Figure 1. vCenter Plug-In Manager shows installed plug-ins (Click image to view larger version.) |
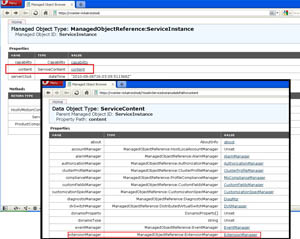
To remove plug-ins on the vCenter Server, go into the vCenter Managed Object Reference at http://vcenterservername/mob (if you're accessing it remotely, use https). Authenticate with vSphere credentials and then click on content and then the extension manager
 |
|
Figure 2. To remove plug-ins, go to the MOB and then the Extension Manager (Click image to view larger version.) |
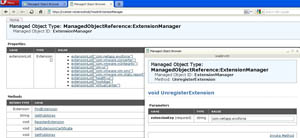
From the list of installed extensions, get the text of the plug-in that you want to remove , but don't take the extensionList[" part of the name, nor the "] at the end. Click the "UnregisterExtension" link at the bottom of the page and enter the plug-in name.
 |
|
Figure 3. Unregistering the plug-in (Click image to view larger version.) |
Click the Invoke Method option to remove the plug-in. The message in the browser may be a little less than intuitive, but at that point the plug-in is removed from the MOB. Subsequent vSphere Client connections won't load it during the discovery stage of their load. Should you be using vCenter Linked Mode, remove it from all vCenter Server systems as well. This easy step can help keep your vCenter server environment clean of unwanted plug-ins as well as keep vSphere Client connections cleaner.
Posted by Rick Vanover on 09/24/2010 at 12:47 PM6 comments
In my post, "
Religious Issue #6: Thin Provisioning," a number of people piped up with comments, as I expected. I'm a fan of thin provisioning and use it in almost every situation for my virtualization practice. But, there is one side of thin provisioning that is more of an art than a science: managing oversubscription.
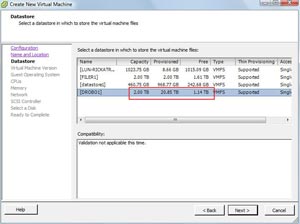
The basic premise of oversubscription is that by the space savings of thin provisioning, the provisioned amount can exceed the threshold of raw capacity. In my personal lab, I have oversubscribed the primary VMFS datastore by over 18 TB (see Fig. 1). This isn't what I would do in the real world, but nonetheless it is tracked by vSphere.
Oversubscription is not necessarily a bad thing; in fact, SAN admins have been doing this for some time. For the typical Windows administrator who has graduated to virtualization administrator, managing oversubscription may be a new skill.
I'd like to point out one caveat to thin provisioning: performance. Thin provisioning by itself has minimal impact on a virtual machine's performance. In Tuesday's post, Scott Drummonds posts a few of his thoughts and a link to VMware thin provisioning white paper. (Thanks, Scott!) In that resource, Figure 4 shows that thin provision has effectively no impact on performance.
 |
|
Figure 1. The VMFS volume has allocated virtual machines much more storage than is available. (Click image to view larger version.) |
My observation on thin provisioning is that the same datastore may have been heavily consumed by free space of a virtual machine, is now populated with the real usage of a virtual machine. We are now able to achieve a greater datastore density, and based on the workloads on that type of disk, we may observe performance differences simply by consolidating more.
Managing oversubscription is best served by the built-in vSphere alerts. How do you hedge off oversubscription, and is the 15-percent threshold (default value) adequate for your needs? Share your comments here.
Posted by Rick Vanover on 09/23/2010 at 4:59 PM2 comments
Within virtualization circles, there is debate about whether or not to use thin provisioning on the hypervisor. Thin provisioning is available on all major hypervisors, including VMware's vSphere 4. For vSphere, thin provisioning of a virtual machine disk file (VMDK) incrementally grows the disk as the guest operating system increases its storage requirement.
Thin provisioning with vSphere has a number of caveats. First, there is no incremental shrink. This means if that the guest operating system incurs a growth of 1 GB, and then that space is removed from the guest; the 1 GB is still consumed within the VMDK. The solution is a Storage vMotion activity which will resize the destination VMDK to the actual consumption on disk. Storage consumption usually only goes up; so this behavior isn't exactly too much of an inconvenience in the everyday administrator's storage management practice.
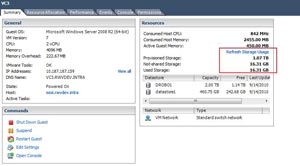
The good news is that if the guest virtual machine consumes an additional 1 GB of storage in the above example and then is removed and subsequently replaced by another 1 GB of growth on the guest operating system's file system, the net growth is only 1 GB. Guest virtual machine behavior may dictate otherwise, but this is a generalization. You can check the used vs. provisioned storage amounts for a vSphere virtual machine in the summary section of the vSphere Client (see Fig. 1).
 |
|
Figure 1. The provisioned amount compared to consumed amount for a thin provisioned disk on a virtual machine will show the usage at that moment. (Click image to view larger version.) |
The potential downside to a thin provisioned VMDK is the behavior associated with the guest virtual machine and the frequency of metadata updates. On a VMFS volume, a metadata update is a coordinated transaction across all hosts and paths connected to the datastore. This is probably the one downside of the VMFS architecture as there is not software coordinator node or management layer as other clustered file systems have in place. When the VMDK file grows in its thin provisioned state, a metadata update occurs for each growth operation. Aside from growing a virtual machine, the following activities constitute metadata updates, according to VMware KB 1005009:
- Creating a VMFS datastore
- Expanding a VMFS datastore onto additional extents
- Powering on a virtual machine
- Acquiring a lock on a file
- Creating or deleting a file
- Creating a template
- Deploying a virtual machine from a template
- Creating a new virtual machine
- Migrating a virtual machine with VMotion
- Growing a file, for example, a Snapshot file or a thin provisioned Virtual Disk
Generally speaking, metadata updates are something that you want to avoid and are probably the biggest ding against thin provisioned VMDKs. If you have good insight into the application's growth behavior, you may not want to thin provision those frequently growing virtual machines. Of course, you could rely on the storage system to do the thin provisioning and avoid the metadata updates.
How do you approach thin provisioning for vSphere virtual machines? Share your comments here.
Posted by Rick Vanover on 09/21/2010 at 12:48 PM7 comments
While VMware users a slew of new features in vSphere 4.1, I still mourn the loss of the vSphere Host Update Utility. This nice Windows-based tool made it very easy to upgrade an ESXi host from one version to the next, as we did when we went from ESXi 3.5 to 4.0. It also made updating ESXi hosts with hotfixes a breeze as well.
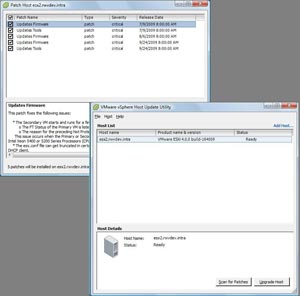
With vSphere 4.1, the free installation of ESXi now dubbed vSphere Hypervisor does not have the Host Update Utility (see Fig. 1). It was part of the vSphere Client Install package as an option that would allow administrators to apply ESXi updates to the host as well as deploy an upgrade .ZIP file.
I have not received official confirmation why the tool wasn't included, but my suspicion is that it is to drive customers to purchase some form of vCenter Server and use Update Manager to keep the hosts up to date. Another reason might be that ESXi's command-line interface is no longer labeled "unsupported." Within the command-line interface, administrators can now use the esxupdate or vihostupdate utilities, but tThese are far less intuitive than the smooth operations of the Host Update Utility. For the free ESXi installations, it isn't exactly "supported" but at least it is not "unsupported." I expect it to be confusing, yet I guess this twisted mind of mine can make sense of this change of heart by VMware.
 |
|
Figure 1. The Host Update Utility is nifty, but it's not in the new vSphere update. (Click image to view larger version.) |
At VMworld 2010 I attended a session on ESXi. I asked the presenter, a VMware employee, what the technical reason was for removing the tool. I didn't get a clear answer, but he asked us if we would like to see it back. Of course I would, but I won't hold my breath. This is yet another setback in a series of cuts or dead-ends to free products from VMware, and I don't expect the trend to stop soon.
Do you miss the Host Update Utility? Share your comments here.
Posted by Rick Vanover on 09/16/2010 at 12:47 PM9 comments
If you are like me, it may seem that there is simply too much e-mail to keep track of. Here's one that caught my eye: an important product bulletin about a potentially urgent driver issue for ESX and ESXi installations that utilize a Broadcom interface with the BCM57711 chipset. This issue posted on
HP’s Web site is applicable to VMware ESX and ESXi systems version 4.0 Update 1.
The basic issue is that the driver steps down the network queue depth to a value of 1 with the driver configuration that comes with this version of ESX and ESXi. The HP support document has steps to correct the issue, but this is concerning as it applies to a number of popular models of servers. Just from the HP line, this includes many of the ProLiant DL, BL and ML series systems.
The resolution is to use the esxcfg-module command to pass a new value to the driver’s running configuration. The HP support document points to a VMware readme file that has options to correct the running configuration for the driver instance loaded on the ESX or ESXi host. A reboot is required to make the change take effect and of course, a test environment would be a good idea to ensure that all functionality works as expected before you return each system to a cluster to host virtual machines.
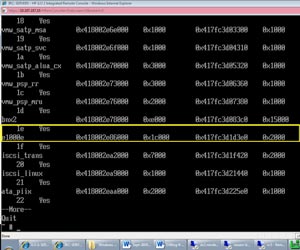
To determine if the BCM57711 chipset is in use, there are two places to look on a host. The first is to look in the Network Adapters section of the vSphere Client for an ESX or ESXi host. The other options is to run “esxcfg-module –l” (the list parameter) and see if the bnx2x instance is loaded among all of the active modules. Fig. 1 shows a line of the esxcfg-module command with the list parameter, with bnx2 (non-effected controller) and e1000e (Intel controller) appearing in the list.
 |
|
Figure 1. Listing the controllers using the esxcfg module. (Click image to view larger version.) |
This is potentially a big issue and I’m going to get into testing right away to see if I have an affected system.
Have you made this tweak to your environment? Share your observations here.
Posted by Rick Vanover on 09/14/2010 at 12:47 PM3 comments
Now that VMworld is over, I can start the very long process of digesting all of the information from the show. One of the most important things I have been investigating is the vStorage APIs for Array Integration or VAAI (see
my earlier post on VAAI). With vSphere 4.1, administrators can send a tremendous amount of work usually handled by the ESXi host to the storage processor.
At face value, it makes quite a lot of sense for this type of work to be done on the storage processor and may seem like an incremental software update. The hidden story here is that there is quite a lot of work that goes on behind the scenes to get this solution out the door.
The first release of VAAI includes three tasks that make use of an unused SCSI reserve command. Early adopters have been discussing what the first three commands would be, as well as what the next three commands will be to offload work from the ESX host. For example, NetApp's Rapid Cloning Utility (RCU) effectively did this for one task ahead of the VAAI movement. While first iteration has support for atomic test and set, clone blocks/full copy/xcopy and zero blocks/write same; there is quite the complicated affair to identify the next steps for VAAI. Each storage company will bring different ideas, capabilities and turnaround to the next line of features.
There is a very small list of storage companies in the initial wave of support: Dell's EqualLogic, 3PAR, NetApp, Hitachi Data Systems (HDS) and EMC. But even within that list, not every product is ready to go with a firmware update or shipping product at the release of vSphere 4.1. Some storage products do not support it currently, but will with upcoming firmware updates. A few products are available from day one, such as the HDS Adaptable Modular Storage 2000 (AMS 2000). In the case of the AMS 2000, existing installations had to implement a new firmware revision and new shipments after the release of vSphere 4.1 had support for VAAI.
VAAI brings amazing performance improvements for the virtualized environment. Dare I go out on a limb and make a recommendation that new purchases include arrays that support VAAI? The vSphere 4.1 upgrade is the (relatively) easy part; but getting a VAAI-supported array may be the harder part due to product lifecycles and maintenance windows on the storage processors.
We all can agree that VAAI is cool, but are there stumbling blocks to get there? Share your comments below.
Posted by Rick Vanover on 09/09/2010 at 12:48 PM2 comments
Few things are more frustrating than surprise software maintenance costs, much less trying to get a handle on what these costs will be. The VMware Support and Subscription (SnS) offering is no exception, and many would say it's a clumsy experience compared to other software management offerings.
Did you know that on the VMware Website for your account, there is a tool that can give you an estimate of the costs of renewing the SnS offering? The estimator tool will calculate the SnS extension cost for a particular serial number, start date, service level and even specify the currency. It's located in the VMware customer account portal.
The SnS estimator tool can be critical for administrators to provide a good estimate for budgeting process, and more importantly can be a more direct process. Too many times, administrators are bogged down with working with resellers and VARs who have to access VMware for some assistance. I'm sure each of us had some sort of issue with any serial numbers that were upgraded from VI3 as well, which can complicate SnS renewals.
The estimator is focused on base vSphere product licenses, and doesn't appear to have options for the newly announced pay-per-VM options for certain workloads.
Managing the SnS process is unfortunately one of the not-so-glorious aspects of virtualization administration, but it needs to be done. This will ensure the environment is correctly licensed, supported and ready for upgrades from VMware. I can't say if SnS management is easier through the reseller channel or directly with VMware, as I've heard complaints on both ends from big and small organizations.
What are some of the tricks you employ for managing your VMware SnS account? Share your comments here.
Posted by Rick Vanover on 09/07/2010 at 12:47 PM0 comments
One of the things that I try to do at VMworld is catch a piece of news or an announcement that really makes me stop and ponder. Today, Novell and VMware
announced that an installation of Novell's SUSE Linux Enterprise Server (SLES) is now included with each vSphere purchase at the Standard level or higher. Essentials and Essentials Plus are not part of this program. If you have made a vSphere purchase between June 9, 2010, and now, any
eligible products are included. The SLES for VMware installations are available now for
download from Novell, not from VMware. Registration is required and it is not actively tied to a VMware account.
I had a chance to discuss this with two directors from Novell: Richard Whitehead and Ben Grubin. I was a little skeptical of the announcement. Primarily, this seems to be the start of another peculiar technical relationship. The most peculiar is the Microsoft and Citrix relationship, one that I have always referred to as "co-opetition." This Novell and VMware announcement puts an enterprise-class Linux distribution easily in the hands of today's installation base. My questions for Novell then rolled into some of the more ongoing aspects of this news.
Any time something is free, I stop and think of receiving a free puppy -- free now, but it could lead to a lot of work later. I questioned Novell on the support of the SLES installations that are included with vSphere. The level one and level two support functions of the SLES for VMware installations are provided by VMware. Level three SLES for VMware support does go through Novell directly, but in both scenarios the support is executed for installations that have an active Support and Subscription (SnS).
What is not entirely clear is what customers who have their SnS delivered through a channel partner. Many customers opt to have Hewlett Packard, Dell, and others provide VMware support directly. These arrangements can escalate to VMware, but each channel partner may deliver or transfer the SLES for VMware support differently. The active SnS subscription also entitles the SLES for VMware installation for operating system updates.
While I see this is important news, I'm not entirely sure what impact it will have on the typical virtualization environment running vSphere. My virtualization practice keeps me in the Windows Server space, yet if I needed a Linux distribution; the SLES for VMware option is one that I would consider. It can awkwardly impact any cost allocation or chargeback, but nonetheless no cost translates well.
How does the SLES for VMware news stir any reaction for you and your virtualization practice? Share your comments here.
Posted by Rick Vanover on 09/02/2010 at 12:47 PM2 comments
I'm trying to focus on the core virtualization and supporting technologies here in San Francisco. Generally speaking, Mondays and Thursdays are days where you can try to squeeze in other things. Tuesdays and Wednesdays are very content-heavy days. There were a few sessions that I took in today outside from the base set of virtualization.
One of the events I attended was about the new Nimbula Director. As it exists today, Nimbula is based on the KVM hypervisor and is a hybrid cloud solution. This is ironic, at face value, as the founders worked on the team that developed the Amazon EC2 cloud. The hypervisor base will expand, but that isn't really too important. Nimbula Director is a hybrid cloud solution that presents a management dashboard that can manage an internal cloud and public clouds such as Amazon EC2 servers running as Amazon Machine Images (AMIs). Hybrid cloud architecture is an emerging science, of sorts, but what stood out to me is Nimbula's approach to permissions and policies. Frequently, many off-the-shelf solutions have products that don't allow the security policy to supersede the permissions model. In the VMware world, there are solutions like HyTrust that can allow this to happen. Nimbula is on the right course in taking the totally fresh perspective to the permission model and infrastructure policies.
Another session I attended was on extreme scale out with the HP Performance Optimized Datacenter (POD). The HP POD is effectively a small datacenter contained in either a 20- or 40-foot-long box. This box was initially built into industry standard shipping containers for the generation one (G1) pod, but the generation three (G3) pod is slightly modified from the traditional shipping container to allow for better airflow management, access and accommodate additional length. In this box, there can be up to 22 racks that are fully controlled, monitored and managed through HP technologies. There is a professional services component for this product, but the capacity on demand is mind-boggling. In a typical fully populated POD, there can be capacity for up to a half-million virtual machines. The underlying technologies of the POD include MDS storage, which doesn't put hard drives facing the front bus. The drives are installed along the depth dimension and are on slide-out trays to increase density. The server solution is the ProLiant SL series. Customers can get partially populated PODs or mix other vendor hardware. Overall, getting my head around extreme scale is exciting but can be tough to fit outside of the traditional datacenter.
As VMworld switches into high gear this week, be sure to follow my Tweets at @RickVanover for notes of what is going on, photos and video from my journey. If you are at the event, track me down or just start shouting "Hey Now," and say hello.
Posted by Rick Vanover on 08/31/2010 at 12:47 PM4 comments
Two days ago, I threw out my five favorite things about the VMworld conference. As promised, here is my snarky collection of five things I dislike. Anyone who has attended will likely agree with one of more of them. A big event like this can never make everyone entirely happy, but it sure is fun to complain every now and then:
- Buzz. There is so much buzz leading up to VMworld, and this is not just VMware buzz. The entire partner ecosystem feels the collective obligation to make some form of announcement during the event. Now, I am even seeing companies making announcements before the event. I am bombarded with information about upcoming product announcements and briefing requests that it is simply unmanageable. The unfortunate consequence is that I have to try to prioritize what events, briefings or announcements are going on this time of year.
- Location. I've critiqued this before, but I would really love to see a VMworld event somewhere other than in the western U.S. Previous events have been in San Diego, Los Angeles and Las Vegas. My suspicion is that San Francisco will reign as the host city for some time for the U.S. event due to logistical support from Palo Alto. I don't have a problem with San Francisco, I just would prefer variety. Heck, maybe I'll start going to the Europe event instead!
- Scheduling. My issue isn't so much scheduling with the sessions, but trying to squeeze it all in! There is so much to do beyond the sessions, and there are great opportunities to meet amazing people. It isn't uncommon to be double or triple booked and have to decide whether to go to an event to meet Steve Herrod or another one with Paul Maritz. This pressure is somewhat relieved this year, as Monday is now a full conference day.
- Connectivity. I suppose that anytime you put over 10,000 nerds in a confined space, it will be difficult to deliver Internet access via any mechanism. The wireless access has historically been less than reliable and mobile phone users report the same. In 2008, my Sprint wireless broadband device was rock solid. We'll see how my Droid X phone does at the show.
- Venue. I'll admit that I am effectively insatiable here. Partly because I generally prefer to avoid crowds in very tight spaces, but also because I feel that there can be more facilities with more natural transitions from one event type to another, such as the general session to breakouts. This based on events at other facilities (again with point #2) that seem to do this better. The 2008 event in Las Vegas at the Venetian was okay by my scrappy scorecard, even in spite of the smoke from the casinos. The 2009 event at the Moscone Center was a little less than okay, but I do prefer San Francisco over Las Vegas.
This gripe list is not meant to discredit the hard work that scores of VMware employees, partner companies, event planners and facility personnel put forth on the event. If I really had issues with VMworld, I wouldn't go. What rubs you wrong about VMworld? Share your comments below.
Posted by Rick Vanover on 08/24/2010 at 12:47 PM3 comments