I mentioned in an earlier post that current versions of VMware Tools now include Perfmon Integration. In a Twitter discussion, I found that this tools integration has disappeared from VMware Tools installations of patched hosts.
The VMware Tools installed with the base release of ESXi, 164009, has the Perfmon integration. In the case of ESXi, a few main categories of updates have been released since the main release. Fig. 1. shows the updates since the base release of the product, including the vSphere Update 1 release in Nov. 2009.
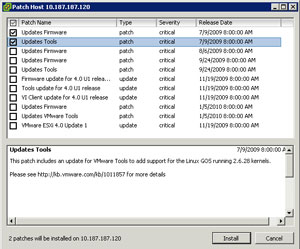 |
| Figure 1. The updates for vSphere ESXi are shown since the base release. (Click image to view larger version.) |
In my unscientific experiment, I determined that the VMware Tools update from 175625 release is where the Perfmon integration dropped off. These were the two updates that were selected in the Fig. 1 screen shot of the vSphere Host Update Utility. Subsequent updates that include new versions of VMware Tools will not reinstate the counters, however.
VMware is aware of this situation and they are on the topic, though only through a Twitter conversation. You can drop the Perfmon counters back into the guest operating system if you rerun the vmStatsProvider add-on for Tools. This can be downloaded from the Pivot Point blog post.
Posted by Rick Vanover on 01/25/2010 at 12:47 PM7 comments
For organizations that deal with a large amount of connectivity, managing I/O that reins in port and device costs is a complicated task. For virtualization implementations, there are a number of ways to tackle this challenge. Some organizations avert fibre channel by focusing on Ethernet-based storage protocols such as iSCSI and NFS. Another strategy is to use blade servers to consolidate servers to a chassis that can have in-chassis switching and storage I/O delivered via a limited number of ports.
In spite of this, we still see a large number of virtualization implementations using rack-mount servers in favor of blades and fibre channel storage in lieu of an Ethernet-based storage protocol. In these situations, organizations can consider consolidating I/O to cut costs in central switching (ports) and achieve better utilization for this connectivity.
Recently, I reviewed parts of the Virtensys virtualized I/O solution. I’ve mentioned virtualized I/O on this blog before after having seen the Xsigo solution as well. The Virtensys solution delivers virtualized I/O differently. For one, Infiniband is not used to deliver the virtualized I/O. Instead, standard host bus adapters, network interfaces and other PCI-Express local devices can be used as the server endpoint device to receive the virtualized I/O.
The other distinguishing feature is that local storage can be managed with virtual I/O. Specifically, the storage that is local or direct attached on a server can be presented back to the Virtensys I/O virtualization engine. Fibre channel storage as well can be delivered through the virtualized I/O. The new VIO 4008 controller concurrently virtualizes Ethernet, fibre channel and local storage.
The typical implementation is a top-of-rack solution, where each server in the rack connects to the I/O virtualization switch for the networking and storage connectivity. The Virtensys technology has a limited compatibility list, but that surely will increase over time.
Virtualized I/O can appeal to certain situations, typically driven by port cost. Virtualized I/O can raise a lot of questions in security circles, however. Frequently the debate of whether or not Layer-2 separation is "good enough" is amplified in this situation as the same physical media could potentially transport multiple security zones of network traffic while simultaneously transporting multiple integrity zones of data.
What is your take on virtualized I/O? Share your comments here.
Posted by Rick Vanover on 01/21/2010 at 12:47 PM4 comments
In "
Fat-Finger Hero," I mentioned how recovering from a bad configuration can be an admin's saving grace. I mentioned how one of the more common areas to get stuck is host networking, and I mentioned some tools that can help you protect against configuration issues.
A new feature of vSphere, the distributed virtual switch, is one that's a perfect solution until something goes awry. Anything can go wrong, from a VLAN not being mapped to a port you are expecting, or possibly that dreaded fat finger. In one of my lab environments, I was configuring the distributed virtual switch feature and hit a snag.
I had performed the migration functionality for the hosts to go to the distributed virtual switch. This moves the management network and vmkernel communication to the distributed virtual switch from standard vswitch configuration. If the distributed virtual switch is configured with all of your expected VLANs, it may look something like Fig. 1.
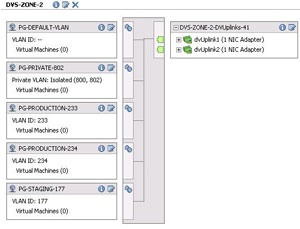 |
| Figure 1. The distributed virtual switch feature is configured in the vSphere Client and deployed to selected hosts. (Click image to view larger version.) |
Should you go 'all in' and migrate the host and its management network to the distributed virtual switch, normal migrations should have minimal interruption in communication. But if anything goes awry in the configuration, the host may become orphaned.
We've all heard of orphaned VMs, but an orphaned host? Yes, it can happen if the VLANs are not correct on the physical switch from which you are migrating. This is especially important if you are changing vmnic assignments in the process.
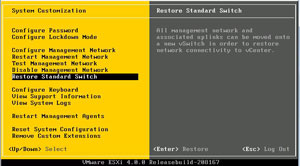 |
| Figure 2. The restore standard switch allows a distributed virtual switch configuration to be undone on a host. (Click image to view larger version.) |
ESXi provides a nice little back-out feature for a distributed virtual switch configuration. From the main ESXi menu, press F2 to enter the customization tool. If a distributed virtual switch is configured, the "Restore Standard Switch" option is enabled. This will let you configure a standard network configuration, select an interface for the vmkernel management interface, and specify a VLAN if necessary (see Fig. 2). Be ware that it will also cause an interruption to guest virtual machines, so it should be done only on an as-needed basis.
Posted by Rick Vanover on 01/19/2010 at 12:47 PM0 comments
There is risk when it comes to configuring the various items that make up a virtualized infrastructure. What do you do when things go wrong? Ideally, there are protections in place to prevent configuration errors from causing you extra work or, even worse, a new install of a host. Here are a few things you can do to protect ahead of the curve for VMware environments:
Scripted configuration: For port group and standard virtual switch configuration, the esxcfg-vswitch command will allow you repeat configuration on many hosts.
Host Profiles: For vSphere environments, host management can be managed through configuration on a number of hosts. This configuration can configure storage, networking, security settings and other aspects of ESX and ESXi hosts.
VI3 networking configuration: The ITQ VLAN and port group manager tool is used to configure networking in VI3 environments.
But what about other situations when the inevitable fat-finger entry occurs? One of the most common things that I have fat-fingered is a VLAN configuration. For things like virtual machine port groups and vmkernel interfaces, this is usually an easy correction when things are determined to be corrected improperly. It gets more complicated with the service console VLAN, IP address or other configuration that prevents you from accessing the system occurs.
Here is an example: I configured the service console of an ESX server with an incorrect VLAN, yet with the correct IP address. While it is a good idea to separate roles with VLANs, I need to use the right VLAN! A way around this without rebuilding the host (as in most cases you can't access it with this configuration) is to create a virtual machine port group on the incorrect VLAN. On that port group, then place a virtual machine and configure its network configuration to be on that IP network that the 'orphaned' host is located. Then, use that virtual machine to run the vSphere client to directly configure the service console correctly (change the VLAN to the correct entry). At that point, the host will resume its correct place on the intended VLAN. This can be especially helpful if you are not on site and have an orphaned host that needs to be reconfigured.
How have you recovered from misconfigured elements of your virtual environment? Share your comments here.
Posted by Rick Vanover on 01/14/2010 at 12:47 PM0 comments
This year, I again have the honor of presenting at TechMentor in Orlando. There are six main tracks in the event: Windows Client/Server, Exchange/SharePoint/Unified Communications, remote users, security, Windows PowerShell and virtualization. For the virtualization track, I will be hosting four sessions:
Along with the other presenters, we'll be delivering 13 sessions in the virtualization track. We will be covering primarily VMware and Microsoft virtualization offerings, and strive to focus on giving you what you need to do your job. The other tracks provide a great rounding out of a TechMentor event, as we all have to do a little bit of everything else as well, it seems.
In January, I will be putting together the material for these four sessions. If you are not familiar with TechMentor, take some time to look into the program. TechMentor is a great way to get into details about topics that are relevant to your roles to get results.
The event is more accessible than other events, as you can have lunch with the presenters as well as ask questions without the burden of a staunch vendor-based influence. Don't get me wrong, as I still like VMworld, but TechMentor is a much less hectic and more cozy experience for attendees.
Do you plan on attending TechMentor? If so drop a note below and I'll make sure to find you there and say hello.
Posted by Rick Vanover on 01/12/2010 at 12:47 PM4 comments
As a blogger, it is important to give relevant material for what readers need to do their jobs and learn a new technology. That's the objective of the Everyday Virtualization blog, as I provide the topics I deal with on a daily basis for readers.
Eric Siebert is one of my colleagues in the blogosphere. Eric runs the popular VMware vLaunchpad (VLP) site. The VLP is a great aggregate collection of blogs and virtualization links. In fact, the VLP and Twitter are the two resources I use most to keep up to date on virtualization topics.
Each year, the VLP accepts votes for the favorite blogs. The Everyday Virtualization blog is on the list with the best of them. Go to the VLP voting site and cast your vote for your favorite virtualization blogs!
Posted by Rick Vanover on 01/06/2010 at 12:47 PM3 comments
Well, not exactly. This holiday season, virtualization saved the day for me in one regard. While virtualization is usually the modus operandi in the workplace and for most of my lab activities, I had an opportunity to use it for my family computing needs. My three-year old daughter received a gift that was an electronic reading device that hovers over a special book to interact with learning games. While the maker of the software is fine enough in the childhood education space, I don't exactly want this software installed on our home computing systems.
This is where virtualization came to the rescue. I installed the software product on a virtual machine and used Sun VirtualBox USB device filters to connect the reading device to the virtual machine. I've mentioned here before the VirtualBox is the Type 2 hypervisor that I use most. The VirtualBox USB device filters allow devices to be connected to the host system, but presented to the guest virtual machine (see Fig. 1).
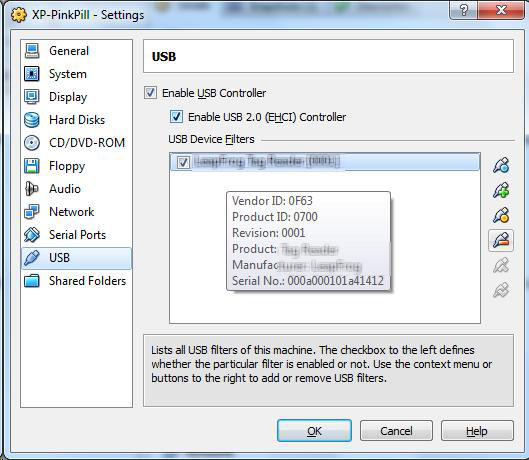 |
| Figure 1.The USB device filters allow a device to be assigned from the host to the guest virtual machine. (Click image to view larger version) |
The funny thing is how I explained to my daughter and wife how this works. While I was clearly more engaged with the details, things like this can help out a number of situations. This example was not wanting occasional software installed on a system, but other use cases include operating system support. Again for the home use case, my scanner only has drivers for Windows XP. The next time I need to scan a document, I'll likely set up a filter for that device and an XP system.
Have USB device filters on VirtualBox or other hypervisors helped you out? Share your story here.
Posted by Rick Vanover on 01/05/2010 at 12:47 PM3 comments
When VMware released ESXi, ESX, and vCenter 4 Update 1; all of the base components received an update to the popular virtualization suite. One of the driving factors of the update was support for both Windows Server 2008 R2 and Windows 7 which were released recently.
For organizations who use VMware Converter Standalone Edition, there may be an issue in certain situations on newer versions of ESX and ESXi. The current version of the standalone converter is 4.0.1 which was released on May 21, 2009. Update 1 for vSphere was released after that, and the new operating systems may not show up correctly when performing certain conversions. In particular, powered-off conversions may fail with the message shown in Fig. 1.
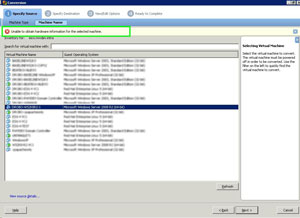 |
| Figure 1. The 4.0.1 version of vCenter Converter Standalone can't process a Windows Server 2008 R2 or other newer operating system. |
The workaround is simple, just change the operating system designation to a lower-family member. In this example, changing the operating system back to the non-R2 version of Windows Server 2008 allows the conversion to proceed.
For vCenter Server Installations, the 4.1.1 version of the plug-in that was issued with Update 1 seems to have similar behavior. Converting powered-off virtual machines on an ESX or ESXi host that are a newer operating system gives an "Unable to determine guest operating system" message. The resolution there is to downward configure the operating system family to Windows Server 2008 base release as well.
There various posts of messages like this in the VMware Communities, but this resolution is quick and easy for the newer operating systems.
Posted by Rick Vanover on 01/05/2010 at 12:47 PM3 comments
The
VirtualBox Type 2 hypervisor has been released with a new feature: teleportation. This is a virtual machine migration technology from one host to another. VirtualBox's implementation of this is quite interesting in a number of ways:
- This is the only Type 2 hypervisor with a live migration functionality.
- This allows live virtual machines to cross host types (Windows, Linux, Solaris, etc.).
- This is the third major virtualization product to offer a free live migration solution.
The 3.1.x series of VirtualBox includes other new features, including the branched snapshot feature. VirtualBox allows an unlimited number of snapshots -- at the expense of drive space -- to allow ultimate flexibility. A branched snapshot allows snapshots to be taken or restored from an existing snapshot (see Fig. 1).
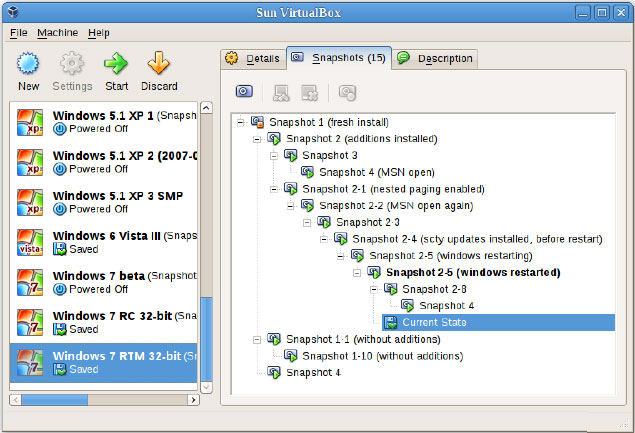 |
| Figure 1.VirtualBox snapshots allow a multitude of restore options. (Click image to view larger version) |
Other major updates for 3.1.x of VirtualBox include a number of enhancements for ease of use and performance. One of these is the ability to change the network type while the VM is running. This was my biggest complaint of VirtualBox, as changing from the default NAT configuration required shutting the VM down.
Additional performance improvements for 2D video and flexible CD/DVD attachment are also part of the new release. Full information on the new release can be found in the VirtualBox user manual online.
VirtualBox is the only Type 2 hypervisor that I use. While VMware products abound in the Type 2 hypervisors for server consolidation, VirtualBox is my preferred product to install on top of an operating system.
VirtualBox is a free product, and is available for download from the VirtualBox Web site.
Posted by Rick Vanover on 12/29/2009 at 12:47 PM4 comments
Since the inaugural Tech Field Day, I've been focused on getting a Drobo storage device for my personal virtualization lab. When I had my previous post on considering the Drobo devices that offer iSCSI connectivity, I was secretly drooling while mine was on its way to me.
Once it arrived, I quickly set it up and got started with the DroboPro device. I'll admit, I'm a pretty cheap guy; I would have purchased the DroboElite model. For my DroboPro device, the firmware that arrived on the unit was 1.1.3. Just days after my device had shipped, Data Robotics had released the 1.1.4 firmware for the DroboPro unit.
In the Release Notes for the 1.1.4 firmware, there are specific mentions of performance improvements for VMware installations. I did a quick test with PassMark's BurnInTest software before and after the new firmware, and the improvements were definitely noticed. The 1.1.4 firmware is installed via a manual firmware upgrade. This process is documented in the manual firmware upgrade instructions document.
The DroboPro firmware updates and Drobo Dashboard software are available as downloads from the Data Robotics support site. Fig. 1 shows the Drobo Dashboard software with the updated firmware.
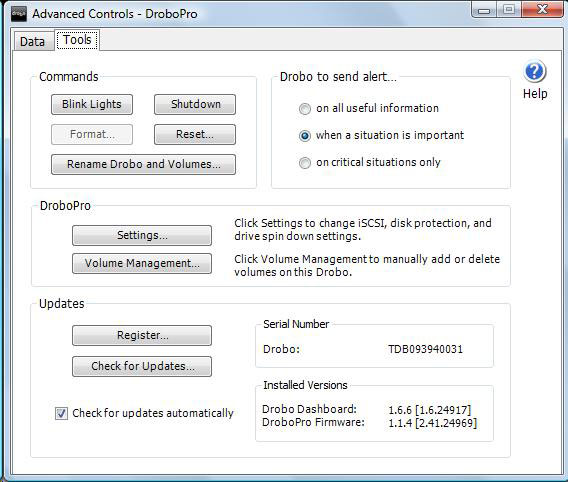 |
| Figure 1. The updated firmware and software versions are displayed in the Drobo Dashboard interface. (Click image to view larger version) |
If you are using a DroboPro or DroboElite unit for test or tier-appropriate virtualization storage, it is worth the time to keep the firmware up to date. While the DroboElite was just released, there will likely be an update for this unit at some point as well.
Posted by Rick Vanover on 12/23/2009 at 12:47 PM0 comments
Earlier this year, I wrote that virtualization has changed my life. I think it is also a good time to look back on how virtualization has come into my life over the years and how it has changed my life as the technologies and my exposures have developed.
2000
In 2000, I was working with a large company providing internal LAN, PC and server support. VMware Workstation came up as a really cool tool. I remember conversations like, "look at this, there is a separate BIOS contained in this file." I really didn't grasp exactly how powerful virtualization was at that point. Mostly, I used it to practice Windows NT-to-2000 migrations. In that era, it was difficult coming up with systems with enough RAM to double the workload.
2001-2007
For this block of years, I found myself becoming more and more creative with VMware virtualization products. I remember one particular requirement where VMware Workstation filled a big gap. At the time, I was working for a large supply chain automation company and our challenge was to create a demonstration system for sales. The issue was, that this mobile picking system unit only had room for one PC in the built-in chassis. The application had a client interface and a server engine that had a database. The application could not be installed on the same instance of Windows as the server due to conflicting ports. Creating a virtual machine with the server was the perfect solution. Further, with a snapshot the orders for the demonstration were always the same and repeatable.
While in this role, I also started to use VMware GSX and then VMware Server. These tools became critical to test client configurations without scores of hardware for the diverse customer base that I worked with. These configurations also extended to creating test environments before critical updates were applied to these custom software solutions.
2007 to Now
In 2007, my responsibilities shifted back to the realm of internal infrastructure. This prime time for infrastructure showed me how to solve the problem of a crowded datacenter and save thousands of dollars per server in the process. My virtualization practice has extended to many levels of datacenter server consolidation. I've learned quite a bit about shared storage and have been able to talk ROI with decision makers in organizations of many sizes.
2010 and Beyond
Virtualization isn't done yet. Not by a long shot. What will the next big step be in my virtualization ladder? Who knows. In the early part of this decade, I would have never have imagined what has transpired from the measly preview of VMware Workstation.
How has virtualization impacted your IT practice over this decade? Share your comments here.
Posted by Rick Vanover on 12/22/2009 at 12:47 PM0 comments
ESXi allows you to boot from a very small disk requirement. This is the perfect vehicle to use in test virtualization environments to learn more about virtualization or test configurations before you roll them into production. In my private lab, I've decided to boot ESXi from a USB flash device.
For ESXi 3.5, configuring boot from USB flash was a little more work that most people would like to do. There are a number of resources on how to create the USB flash-bootable image, among the most popular being Remon Lam's post at VMinfo.nl.
With ESXi 4, we're now able to do the install from the bootable CD-ROM disk to install upon the USB flash. A few prerequisites need to be configured first, however. The primary requirement is that the USB controller on the server in question is supported as a boot device. This may be configured in the BIOS of the server in question. One of my servers in my private lab is an HP ProLiant ML 350 G5 server. This option is configured in the boot devices section of the BIOS, shown in Figure 1 below:
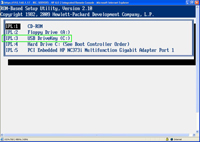
[Click on image for larger view.] |
| Figure 1. The server BIOS will permit boot from USB flash functionality. |
Different server models may have different boot behavior for USB devices, especially if multiple USB controllers are present. It may be necessary to move the USB flash drive to another interface capable of booting an image. If you want to install ESXi onto a bootable flash from the ESXi product CD, simply ensure that there are no other storage devices accessible during the installation. This includes fibre channel HBAs that may be connected to storage fabric, as well as any local drive arrays or disk on the server.
While this practice is adequate for test and lab use, it's not a production-class configuration. For diskless boot of ESXi, there are two primary options. The first is a dedicated LUN for each ESXi server. This LUN should be masked to only one host. The second is to use a built-in SD Flash to boot ESXi on the server. Newer servers have this option for virtualization-specific configurations. The HP offering (part # 580387-B21) offers a 4GB flash media for the server.
Diskless ESXi boot is nice, especially for lab configurations. Your VMFS volumes, if on local disk, will be preserved in case you need to reload the hypervisor. And thanks to VMFS-3's backward and forward version compatibility, there won't be any surprises down the way.
Are you booting ESXi from flash? What tips and tricks have you learned along the way? Share your comments below.
Posted by Rick Vanover on 12/16/2009 at 12:47 PM2 comments