Anyone who has tried to go down the VDI path for a small client virtualization installation and came to a hard stop will welcome any arrangement that makes it easy. VDI is a tough technology to reign in compared to the great success we've had in virtualizing servers. Many situations can bring a VDI effort to a stop, including a cost model that still puts physical PCs as the ROI winner.
At VMworld, one product that caught my eye is Kaviza's VDI-in-a-box. Simply put, Kaviza makes a broker that works pretty much anywhere to anywhere. The current offering includes support for XenServer and VMware hypervisors, with Hyper-V support coming. The endpoint can be anything from a PC client install (bring your own computer to work anyone?) to native RDP and Citrix HDX support for use on a number of thin-client devices such as Wyse and 10ZiG devices.
I noticed a few things from running the demo. For one thing, VDI-in-a-box can utilize direct attached storage. I've long thought that DAS has a use case in virtualization to some extent, as the cost savings can be so great that a shared storage infrastructure may not be required. Of course, many factors go into any decision; but DAS can be high-performance and eight drives or more can be on a local array.
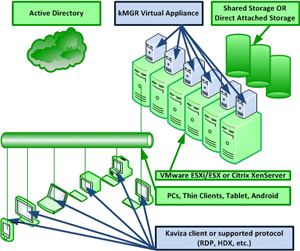
The Kaviza solution utilizes a virtual appliance on each hypervisor to broker the connections to a wide array of supported endpoints (see Fig. 1).
 |
|
Figure 1. Kaviza's VDI-in-a-box builds on commodity components (in green) and provides the broker as a virtual appliance and uses a supported protocol to bring a VDI session to a number of devices. (Click image to view larger version.) |
The best part of the Kaviza solution is that it can run under $500. This includes the server, hypervisor, Kaviza ($125 per concurrent user) and Microsoft costs. This cost does not include the device if a non-PC is used; on the high-end the street price would be $425 per client with Kaviza's online ROI guide.
Does a sub-$500 VDI solution not offered by VMware, Citrix or Microsoft appeal to you? Share your comments here.
Posted by Rick Vanover on 10/26/2010 at 12:48 PM2 comments
When vSphere was first released, the new features and their alignment to existing investments created lots of confusion. Customers that have an active Support and Subscription (SnS) agreement were entitled to a certain level of vSphere features. There were no direct mappings to the Enterprise Plus level of vSphere that did not involve the promotional pricing to upgrade all processors to Enterprise Plus, however.
At the time, the Enterprise level of vSphere licensing was slated to be available for sale for a limited time. To this day, Enterprise is still available for sale. For anyone considering between the two versions, I will definitely nudge you towards Enterprise Plus. Here are a few reasons why:
- vSMP support: Enterprise currently limits a virtual machine to 4 vCPU, effectively still functioning at the same level as ESXi 3.x. vSphere is capable of 8 vSMP to a single virtual machine, but it isn't licensed to that level unless Enterprise Plus is utilized.
- Cores per processor: Enterprise limits this to six cores per socket. While the current mainstream processors are available with six cores and will easily fit most installations, consider the future and any licensing that will be reapplied to new servers.
- Distributed switch functionality: This is somewhat forward-looking, but if at any point vCloud Director would be a consideration in the future; this is made much easier with the heavy networking investment.
- Host profiles: This vSphere feature allows customized host configurations for almost any manageable value to be applied centrally to vCenter after a host ESXi system is installed.
The full breakdown of Standard, Advanced, Enterprise and Enterprise Plus licensing levels is here.
The other side of the coin is, if all of these levels bring too much cost into the picture and the features are not required, VMware has made a serious leap forward with the revised Essentials Plus offering. Basically, small and remote sites that need a virtualized infrastructure will see it as a winning solution; but not all of the features of the big datacenters. Check out the Essentials Plus offering here.
Enterprise Plus may not be needed for all installations, but if the decision rests between Enterprise and Enterprise Plus; it should be pretty clear which way to go.
Have you made the case to stay on Enterprise? If so, share your comments here.
Posted by Rick Vanover on 10/21/2010 at 12:48 PM5 comments
During VMworld in San Francisco, an important update crept out for the VMware
vCenter Converter Standalone edition. It was great news for me, as I had started to wonder if the product was going the way of a deprecated product. The virtual machine conversion mechanism is still an important part of the arsenal for today's virtualization administrator. I frequently use it for additional physical-to-virtual conversions, specialized virtual-to-virtual operations such as a data center migration and to shrink existing virtual machines.
Version 4.3 was released on August 30 with two key features. The first is support for Windows 7 x86 and x64 editions; the other is support for Windows Server 2008 x86, x64 and R2 editions. This support is both for a machine to be converted as well as the platform to run VMware Converter. After installing VMware Converter 4.3, the supported operating system table only goes as old as Windows XP for Windows systems. This means that Windows 2000 has fallen off of the supported platform list for Converter 4.3. It may be a good idea to grab one of the older copies of VMware Converter while you can, in case you still support Windows 2000.
VMware Converter 4.3 adds a number of other natural platform support configurations, including support for vSphere 4.1. But perhaps the most intriguing support with this release is a broad offering of Hyper-V support. Windows virtual machines that are powered on while running on Hyper-V may be converted as well as powered-off virtual machines that run Windows Server 2008 including x86, x64 and R2 editions, Windows 7, Windows Vista, XP, SUSE Linux 10 and 11, and Red Hat Enterprise Linux 5. Microsoft .VHD and .VMC virtual disk formats can also be imported.
I've used it a few times since it was released and have not had any issues with it performing virtual-to-virtual conversion tasks. VMware Converter is still a critical part of the daily administrator's toolkit and finally made complete with Windows 7 and Server 2008 support.
Have you had any issues with the new version thus far? Share your comments here.
Posted by Rick Vanover on 10/19/2010 at 12:48 PM5 comments
One of the things I love about virtualization is that the virtualization community aspect is so well defined. I particularly enjoy also that the VMworld events are a manifestation of the community, and that was repeated this week in Copenhagen for the VMworld Europe show. In years past, VMworld Europe has been at a polar opposite on the calendar from the VMworld event in the U.S.; which finished up in early September in San Francisco.
By having the events so close together, VMware and the partners can control timing of news as well as releases. It is an incredible feat to pull off an event the size of VMworld, much less having to repeat the ordeal a mere six weeks later in Europe. By having the same message, announcements, labs and other components that make up VMworld; there is an incredible logistic efficiency obtained.
After VMworld in San Francisco, I had a discussion about the logistics of one, two or even three events recently on the Virtumania podcast. A suggestion was raised to have more events, and I quickly chirped in saying that it is way too much work to put on an additional event of this level. This leads to my biggest complaint about VMworld, the fact that the US events are always in the Western part of the country. There are plenty of destinations in the central part of the US, but the most compelling reason is for the attendees. Given that there is not a VMworld for the Asia/Pacific region, a VMworld event needs to be accessible for those attendees. The Western cities of San Francisco, Las Vegas, Los Angeles and others do that nicely.
For my own VMworld attendance strategy, next year I am going to try to attend both events. This will allow me to fully take in everything that you miss between the two events. Believe me, there is plenty to take in. If you are borderline on attending VMworld and have never done so before, I recommend you do it. There is something for everyone at the event, and as a blogger I find this as an important way to meet up with other bloggers, tech companies and the readers.
Until next year, the craze that is VMworld will get quiet. As for the whole cloud thing, well, we'll work on that.
Posted by Rick Vanover on 10/14/2010 at 12:48 PM2 comments
What's great about virtualization is the fact that we can change just about anything we want with minimal impact to production workloads. It's partly due to functionality from hypervisors and management software, but the human factor plays a big part. Here is a quick housecleaning checklist to review through a vSphere environment (and applies to versions of vSphere and VI3), to catch the small things that may have accumulated over the years:
Datastore contents: How many times have you put a powered-off virtual machine in a special folder, on a special datastore or held onto just a .VMDK in case you ever needed it? There are a number of crafty ways to find these, including using a product like the VKernel Optimization Pack to find unused virtual machines. Also keep your eyes open for the “Non-VI workload” error message from last week's blog post.
Reformat VMFS: I know there is no hard reason to upgrade, but it is annoying to see a smattering of volumes that are created as storage is added and ESXi (or ESX) versions are incremented. Evacuating each volume with Storage vMotion and reformatting will bring every volume up to VMFS 3.46 (assuming version vSphere 4.1 is in use). This would also be a good time to reformat each volume at the 8 MB page size, as there is no real compelling reason to be on 4, 2 or 1 MB sizes.
Check for antiquated DRS configuration items: Rules that are not needed any more, resource reservations that were a temporary fix, or limits that may not need to be in place can put extra strain on the DRS algorithm.
Reconfigure drive arrays: If you have been wishing to reformat a drive array at a different RAID level (such as RAID 6 instead of RAID 5), the previous datastore step may create a good time to correct this.
Reconcile all virtual machines with lifecycle and approval: We've never stood up a test virtual machine as an experiment, have we? Make sure all experimental machines are removed or that they still need to exist.
Permission and role reconciliation: Check that the current roles, active administrators, permissions and group setup are as expected.
Template and .ISO file cleanup: Do we really still need all of the Windows 2000 and XP virtual machine templates? Chances are at least one template can be removed.
Update templates: For Windows updates, VMware Tools, virtual machine version, etc.; these configuration elements can quickly get obsolete.
Change root password: Probably a good idea if you've had staff turnover at some point.
Do you have any additional housekeeping items? Share your periodic tasks here.
Posted by Rick Vanover on 10/12/2010 at 12:48 PM5 comments
One of the pillars of virtualization is the ability to abstract servers from hardware to provide additional availability. Of course, infrastructure demands continue to increase and we seek to deliver high availability or even fault tolerance beyond the basic virtual machine. A number of solutions are available for virtual workloads.
The fault-tolerant space has three mainstream players: the VMware Fault Tolerance virtual machine feature with vSphere, Neverfail (which has an OEM relationship for VMware's vCenter Server Heartbeat feature) and Marathon Technologies. Neverfail aligns with VMware, and Marathon aligns with Citrix.
Since the middle of the last decade, Marathon Technologies has offered solutions from HA to FT for Windows workloads before virtualized servers were mainstream in the datacenter. Back when I worked in the supply chain software industry, I used the everRun HA solution to replace fault-tolerant hardware solutions such as the NEC Express5800/ft or Stratus ftServer. Even back then, Marathon allowed customers to utilize commodity hardware for these HA and FT solutions.
Marathon recently released everRun MX, which provides a flexible offering to deliver FT workloads on commodity hardware. everRun MX can work for those who want to deploy a robust solution for a few workloads without a huge investment. everRun MX can use direct-attached storage or shared storage, making it price competitive if a traditional SAN is not involved. I've always thought it is very tough to provide a robust, highly available virtualized environment from small footprints such as a remote office.
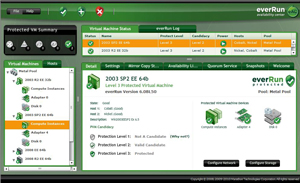
With everRun MX, a base configuration starts at $10,000 and allows administrators to run a pair of servers of any configuration (core/sockets/memory) and includes one year of support and maintenance. The servers must have Intel processors. You can run everRun MX on dissimilar hardware, but they should be comparable. everRun MX uses the term Metal Pool, which would loosely equate to a cluster of virtual machines running with FT capabilities.
 |
|
Figure 1. everRun MX allows a collection of virtual machines to function in a fault tolerant mode on commodity hardware. (Click image to view larger version.) |
You might be asking: How well would this type of configuration be received within the greater software landscape? As virtualization customers, we go through this battle with new software titles to see if the software vendor supports their product being run on a virtual machine. For an architecture like this, it's not as widely embraced as is a VMware virtual machine as a supported platform. But Marathon does offer 24x7 worldwide support in addition to an extensive partner ecosystem. I haven't used Marathon products in a while, but everRun MX seems to bring more to the table for the customer seeking value and features.
Let me know if you want to see more of everRun MX and I'll follow up with an evaluation!
Posted by Rick Vanover on 10/07/2010 at 12:48 PM7 comments
In VMware Infrastructure 3, the one area that the vCenter Server needed to do a better job was its built-in alarms and alerting. So, one vSphere 4 objective was to increase the breadth of built-in alarms. This saves administrators time with PowerShell, as the only way to achieve full safety is to script alerts and send e-mails.
The good side is that you can put in a lot of handling and specific criteria for the thresholds -- well, at least as good as you can script them. The bad side is that the vCenter Server database doesn't track these events to the affected object (datastore, host, VM, etc.).
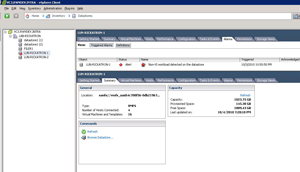
vSphere 4 has a new alert, "Non-VI workload detected on the datastore" that is somewhat misleading. This message shows up on an otherwise healthy datastore (see Fig. 1).
The basic premise for this alert on the datastore is to avoid a virtual machine that is removed from inventory consuming too much space on the datastore. This is somewhat of a misnomer, as many administrators put non-workload data on datastores. This data can include CD-ROM .ISO files as well as a special backup of a system before it is deleted.
Further, the VMFS file system has built-in functionality to allow multiple ESXi hosts connect. This means that you can have a number of ESXi hosts that may be licensed with vCenter connect to a datastore, and that same datastore is zoned on the storage system to another ESXi system, such as the free edition without vCenter (I cover this in my "Forward Motion" post from last year).
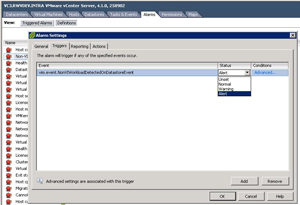
The new alert is also somewhat useless as it doesn't tell you what the offending workload is on the datastore. Administrators are left to use the Storage View functionality and maps to determine what files or virtual machines are the culprits. I'm all for saving datastore space, but I don't like that this defaults to an "Alert" level and issues a red indicator. This can be changed to a "Warning" level and issue a yellow indicator in the definition of the alarm (see Fig. 2).
 |
|
Figure 1. While the datastore has ample space and adequate connectivity, an alarm is generated by the presence of foreign content. (Click image to view larger version.) |
 |
|
Figure 2. You can make this condition issue a warning instead of an alert in the definition of the alarm. (Click image to view larger version.) |
Do you find this alert a little confusing or over-cautious? Share your comments here.
Posted by Rick Vanover on 10/05/2010 at 12:48 PM1 comments
I'm still digesting the material I got at VMworld 2010 . The show had two over-arching themes: cloud and VDI. It's not entirely surprising, as these are new segments for VMware and the larger virtualization market. While those are good things to focus on, I and others still need to focus on the virtual machines we have in use.
Virtual machine memory management is still one of the most tactical areas of virtualization administration. Something I'm watching closely is how new operating systems will impact my daily practice. My practice mainly revolves around Windows-based virtual machines, and Windows Server 2008 R2 is the server operating system of choice. Too many times applications give a generic list of requirements, and infrastructure administrators are left making decisions that may impact the overall success of the installation. One strategy is to identify what the memory would look like on a new virtual machine in terms of slices that represent each requirement. Fig. 1 shows a sample virtual machine with two core applications.
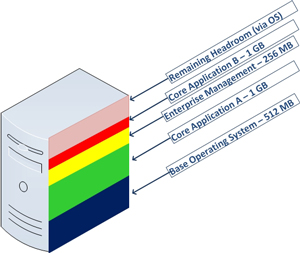 |
|
Figure 1. Having a visual representation of the memory requirements is a good way to plan what the virtual machine memory may look like. (Click image to view larger version.) |
It's an incredible challenge for a virtualization administrator to provision exactly what memory is required, yet balance headroom within the guest for unique workloads. We also have to be aware of the host environment. It very well may be that in a year the application's requirements may double, thus the performance and resource requirements may double as well. Fortunately, server virtualization allows ease of scale in most areas (CPU, disk, network) but memory can be more tricky to implement. Memory is relatively inexpensive now, but that may not be the case forever and we may end up flirting with host maximums for older Hyper-V or VMware vSphere hosts.
The takeaway is to give consideration to each operating system's limits. This will impact what headroom would be available for a guest virtual machine as well as the aggregated impact on the host. A few years ago, administrators dodged a bullet with Windows Server 2003 Standard (x86) having a 4 GB limit for a virtual machine. For Windows Server 2008 R2 Standard edition, the limit is now 32 GB. It is possible that applications that are replacing older servers running Windows Server 2003 to now require double, triple or more RAM than the previous systems. Luckily, a number of virtualization tools (many of them free) can aid the virtualization administrator in this planning process. This MSDN resource has memory configuration maximums for all versions of Windows.
Virtualization administrators should pay special attention to the limits, requirements and aggregate memory capacity with insight to future needs. For this aspect of workload planning, what tools (free or not) do you utilize to assist in this process? Share your comments here.
Posted by Rick Vanover on 09/28/2010 at 12:48 PM7 comments
One of the things that I try to do at VMworld is catch a piece of news or an announcement that really makes me stop and ponder. Today, Novell and VMware
announced that an installation of Novell's SUSE Linux Enterprise Server (SLES) is now included with each vSphere purchase at the Standard level or higher. Essentials and Essentials Plus are not part of this program. If you have made a vSphere purchase between June 9, 2010, and now, any
eligible products are included. The SLES for VMware installations are available now for
download from Novell, not from VMware. Registration is required and it is not actively tied to a VMware account.
I had a chance to discuss this with two directors from Novell: Richard Whitehead and Ben Grubin. I was a little skeptical of the announcement. Primarily, this seems to be the start of another peculiar technical relationship. The most peculiar is the Microsoft and Citrix relationship, one that I have always referred to as "co-opetition." This Novell and VMware announcement puts an enterprise-class Linux distribution easily in the hands of today's installation base. My questions for Novell then rolled into some of the more ongoing aspects of this news.
Any time something is free, I stop and think of receiving a free puppy -- free now, but it could lead to a lot of work later. I questioned Novell on the support of the SLES installations that are included with vSphere. The level one and level two support functions of the SLES for VMware installations are provided by VMware. Level three SLES for VMware support does go through Novell directly, but in both scenarios the support is executed for installations that have an active Support and Subscription (SnS).
What is not entirely clear is what customers who have their SnS delivered through a channel partner. Many customers opt to have Hewlett Packard, Dell, and others provide VMware support directly. These arrangements can escalate to VMware, but each channel partner may deliver or transfer the SLES for VMware support differently. The active SnS subscription also entitles the SLES for VMware installation for operating system updates.
While I see this is important news, I'm not entirely sure what impact it will have on the typical virtualization environment running vSphere. My virtualization practice keeps me in the Windows Server space, yet if I needed a Linux distribution; the SLES for VMware option is one that I would consider. It can awkwardly impact any cost allocation or chargeback, but nonetheless no cost translates well.
How does the SLES for VMware news stir any reaction for you and your virtualization practice? Share your comments here.
Posted by Rick Vanover on 09/02/2010 at 12:47 PM2 comments
I'm trying to focus on the core virtualization and supporting technologies here in San Francisco. Generally speaking, Mondays and Thursdays are days where you can try to squeeze in other things. Tuesdays and Wednesdays are very content-heavy days. There were a few sessions that I took in today outside from the base set of virtualization.
One of the events I attended was about the new Nimbula Director. As it exists today, Nimbula is based on the KVM hypervisor and is a hybrid cloud solution. This is ironic, at face value, as the founders worked on the team that developed the Amazon EC2 cloud. The hypervisor base will expand, but that isn't really too important. Nimbula Director is a hybrid cloud solution that presents a management dashboard that can manage an internal cloud and public clouds such as Amazon EC2 servers running as Amazon Machine Images (AMIs). Hybrid cloud architecture is an emerging science, of sorts, but what stood out to me is Nimbula's approach to permissions and policies. Frequently, many off-the-shelf solutions have products that don't allow the security policy to supersede the permissions model. In the VMware world, there are solutions like HyTrust that can allow this to happen. Nimbula is on the right course in taking the totally fresh perspective to the permission model and infrastructure policies.
Another session I attended was on extreme scale out with the HP Performance Optimized Datacenter (POD). The HP POD is effectively a small datacenter contained in either a 20- or 40-foot-long box. This box was initially built into industry standard shipping containers for the generation one (G1) pod, but the generation three (G3) pod is slightly modified from the traditional shipping container to allow for better airflow management, access and accommodate additional length. In this box, there can be up to 22 racks that are fully controlled, monitored and managed through HP technologies. There is a professional services component for this product, but the capacity on demand is mind-boggling. In a typical fully populated POD, there can be capacity for up to a half-million virtual machines. The underlying technologies of the POD include MDS storage, which doesn't put hard drives facing the front bus. The drives are installed along the depth dimension and are on slide-out trays to increase density. The server solution is the ProLiant SL series. Customers can get partially populated PODs or mix other vendor hardware. Overall, getting my head around extreme scale is exciting but can be tough to fit outside of the traditional datacenter.
As VMworld switches into high gear this week, be sure to follow my Tweets at @RickVanover for notes of what is going on, photos and video from my journey. If you are at the event, track me down or just start shouting "Hey Now," and say hello.
Posted by Rick Vanover on 08/31/2010 at 12:47 PM4 comments
Two days ago, I threw out my five favorite things about the VMworld conference. As promised, here is my snarky collection of five things I dislike. Anyone who has attended will likely agree with one of more of them. A big event like this can never make everyone entirely happy, but it sure is fun to complain every now and then:
- Buzz. There is so much buzz leading up to VMworld, and this is not just VMware buzz. The entire partner ecosystem feels the collective obligation to make some form of announcement during the event. Now, I am even seeing companies making announcements before the event. I am bombarded with information about upcoming product announcements and briefing requests that it is simply unmanageable. The unfortunate consequence is that I have to try to prioritize what events, briefings or announcements are going on this time of year.
- Location. I've critiqued this before, but I would really love to see a VMworld event somewhere other than in the western U.S. Previous events have been in San Diego, Los Angeles and Las Vegas. My suspicion is that San Francisco will reign as the host city for some time for the U.S. event due to logistical support from Palo Alto. I don't have a problem with San Francisco, I just would prefer variety. Heck, maybe I'll start going to the Europe event instead!
- Scheduling. My issue isn't so much scheduling with the sessions, but trying to squeeze it all in! There is so much to do beyond the sessions, and there are great opportunities to meet amazing people. It isn't uncommon to be double or triple booked and have to decide whether to go to an event to meet Steve Herrod or another one with Paul Maritz. This pressure is somewhat relieved this year, as Monday is now a full conference day.
- Connectivity. I suppose that anytime you put over 10,000 nerds in a confined space, it will be difficult to deliver Internet access via any mechanism. The wireless access has historically been less than reliable and mobile phone users report the same. In 2008, my Sprint wireless broadband device was rock solid. We'll see how my Droid X phone does at the show.
- Venue. I'll admit that I am effectively insatiable here. Partly because I generally prefer to avoid crowds in very tight spaces, but also because I feel that there can be more facilities with more natural transitions from one event type to another, such as the general session to breakouts. This based on events at other facilities (again with point #2) that seem to do this better. The 2008 event in Las Vegas at the Venetian was okay by my scrappy scorecard, even in spite of the smoke from the casinos. The 2009 event at the Moscone Center was a little less than okay, but I do prefer San Francisco over Las Vegas.
This gripe list is not meant to discredit the hard work that scores of VMware employees, partner companies, event planners and facility personnel put forth on the event. If I really had issues with VMworld, I wouldn't go. What rubs you wrong about VMworld? Share your comments below.
Posted by Rick Vanover on 08/24/2010 at 12:47 PM3 comments
Next week is the big event. VMworld will return once again to San Francisco and connect the entire virtualization community together. This will be my third trip to VMworld, and I'm quite excited. While I am saving my snarky post about the five things I dislike most about VMworld for later this week, here are five things that I like best about VMworld:
- Community. I don't exactly know why or how, but virtualization "just gets" the whole technology community thing. Virtualization is unique among the greater IT landscape in that we have a passionate blog network, podcasts, events such as VMworld, colorful Twitter personalities and a common desire to tie all of these social media strategies together. Having these entities manifest themselves at a big event, such as VMworld, is a real treat.
- Partners. VMworld does a good job of effectively bringing every partner into one room in the Solutions Exchange pavilion. This is a good way to get a feel for what's out there when the Internet isn't enough.
- Sessions. Most sessions are presented by leaders in their field, and I've enjoyed almost every one I've ever attended. Here's a little secret on the sessions: VMware is very stringent on the quality assurance aspect of the presentation format. Sure, there is a what you can and cannot say aspect to it, but also a very professional and effective communication strategy.
- Variety. As I have stated before, and anyone whom has attended will say, VMware is not like a training class for a specific product. There is no "deliverable" that you walk away with, but what you do experience is a sampling of every aspect of your infrastructure (beyond virtualization). This can come in the form of conversations with people in similar situations. Everyone walks away with something positive from VMworld.
- Fun. VMworld has fun as part of the agenda. This can be the VMworld party, which will have INXS performing this year, vendor parties or even exhibit floor swag. I'm not one to take much notice of swag, but every year someone will provide some form of promotional material that is pretty cool. I've amassed a boomerang, ocarina, water bottles, T-shirt apparel for any occasion and an endless score of USB flash drives.
VMworld is what you make of it, and you can benefit from all of the above as an attendee. If you will be there, I encourage you to go out and take it all in! I'll be there, and if you want to meet me be sure to stop by a Tweetup (or SmackUp) for the Virtumania podcast crew. It's Sept. 1 at 1 p.m. at the Veeam Booth (#413). Register for the event at Twtvite.com.
What do you like most about VMworld? Share your comments below.
Posted by Rick Vanover on 08/24/2010 at 12:47 PM3 comments