What exactly would you do with a cloud-based virtual desktop infrastructure (VDI)? I can roll through a lot of scenarios in my head where it may make sense. Recently, I've been given a time-limited evaluation account for the iland workforce cloud and can see where this could be beneficial.
The workforce cloud is in most cases a VMware View-based VDI solution that is hosted in the cloud. The connection broker is done with a VMware View client, including support for devices without a full operating system. This includes terminal devices that support VMware View for their connection broker.
The workforce cloud does a few things that reverse perspective from traditional cloud solutions if there is such a thing. Primarily, along with the virtual desktop -- you can put virtual servers in the iland cloud. Both are VMware-based technologies that are on the same subnet, so application latency to back-end servers is not a factor. Secondly, iland is historically in the colocation business. This means that if you require a hardware appliance for mail filtering, it can be accommodated.
Now that you have a fair idea of the technologies involved, how does it work and what does it look like? Over the next few weeks here on the Everyday Virtualization blog, I'm going to give you a tour of the technology in play and my opinion. (I'm writing this blog in the cloud with this service.)
For starters, it all starts with the familiar View client. The workforce cloud negotiates an SSL connection over the Internet to the VMware View broker. From the client perspective, Fig. 1 is what you get.
 |
| Figure 1. Here's what the VMware View broker sees as a virtual desktop makes a secure connection in the cloud. (Click image to view larger version) |
Once connected, the evaluation has provided me two systems, VMware View-based Windows XP virtual desktop and a Windows Server 2003 Server virtual machine. In this small cloud setup, I will be hashing out a number of configurations and 'how does it feel' points for this type of technology over the coming days. So, be sure to check back for the first steps into the cloud.
Have anything you want me to test during my trip into the clouds? Share your comments here.
Posted by Rick Vanover on 11/02/2009 at 12:47 PM13 comments
Earlier in the week I mentioned that I would be evaluating a hosted VDI solution from the iland workforce cloud. So far in to the experience I can say that while it works well, there are many considerations that we need to factor into a decision like this.
In this blog post, I want to focus on two critical points that go into any VDI solution. The first is the display technology used. Above all, the workforce cloud is brokered by VMware View over SSL over the Internet. So, that means that the View client is the endpoint display delivery and intermediary display from the actual virtual machine.
There can be a few configurations in use, but what matters is the experience. I have been using the hosted virtual desktop at a residential broadband offering that is a cable-based transport. From an experience standpoint, it is okay. Standard applications like Word, Windows Explorer and navigating the operating system are fine. In fact, I can hardly determine the experience is not native in these applications.
Web browsing is a different story. If I end up on any Web page that has Flash embedded in the display, performance is painful. Flash can be sent through a display technology, and it is only as good as your pipes. I ran a number of Internet connection tests from Speedtest.net on the virtual desktop, and they performed well. Some results were higher; some were lower with the Internet results (see Fig. 1).
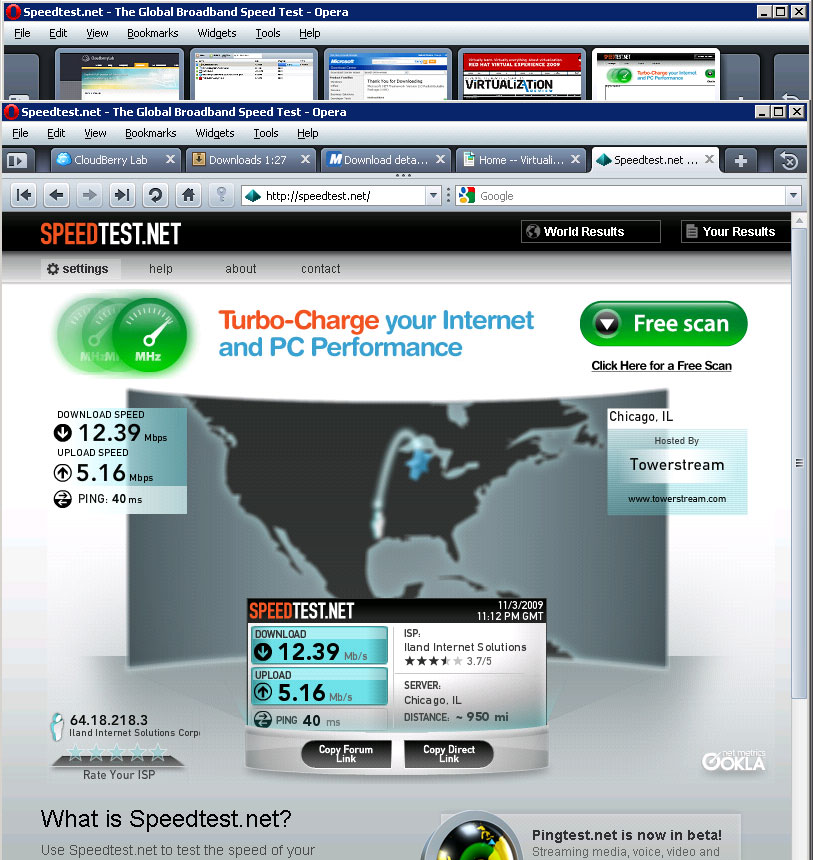 |
| Figure 1. Bandwidth matters in the cloud on both ends. (Click image to view larger version) |
The iland workforce cloud is different in one respect: Your servers could be in the same cloud allowing for local access.
Back to the display experience; I will soon test the performance on a connection that is better than a residential broadband service. I’ll follow up with the results and share them with you on this blog.
The other key point I want to discuss is device support. The iland workforce cloud worked seamlessly in providing full device redirection. This included options for dual monitor support, printing, local removable media and mapped network drives on the endpoint client. There can be policies in place to address how and if these are redirected. This was refreshing that there was no configuration required to use the devices on the local client. Fig. 2 shows my printer on the local workstation accessible from the hosted virtual desktop.
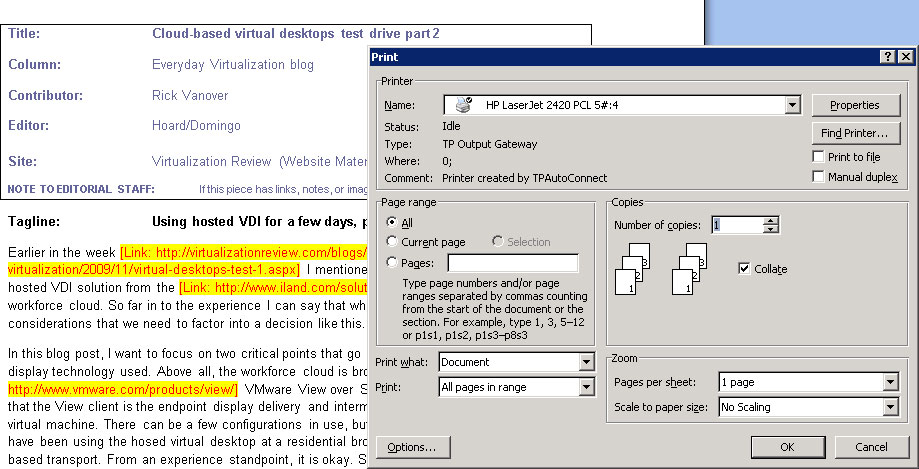 |
| Figure 2. Printing on the hosted virtual desktop could not have been easier. (Click image to view larger version) |
Notice the “TPAutoconnect” in the printer comments. That is a ThinPrint integration for easy printing on the hosted virtual desktop.
Thus far in my use of the hosted virtual desktop I’d say, "so far, so good." I’m going to make the connection on a higher bandwidth network and see how that goes, but even if the performance is better, I’m not happy just yet. I believe that the hosted virtual desktop needs to perform at the residential level, which will include less than optimal bandwidth speeds.
In future blog posts, I'll cover virtual private networking with hosted desktops as well as device connections in lieu of full-blown desktop connections. Also in the crystal ball is the important other half: the hosted virtualized server with the hosted virtual desktop.
Have something you want me to cover? Share your comments here or e-mail me.
Posted by Rick Vanover on 11/02/2009 at 12:47 PM0 comments
Generally speaking, I don't like any licensing mechanisms that require a lot of interaction. VMware's licensing is unfortunately one of these mechanisms. If you are like me with at least one environment that is still running VMware Infrastructure 3, you may find it difficult to increase the licensing if you need to add a host or piece of functionality. At this point in time, only vSphere license are sold. I recently went through a licensing downgrade, and it wasn't seamless yet it wasn't that bad.
What you have to do first of all is add the vSphere licenses into your licensing account as a first step. The next step is to request them be issued as a downgrade. This a link at the bottom of your licensing portal shown in Fig. 1.
 |
| Figure 1. VMware's licensing portal page, where you specify licensing downgrades. (Click image to view larger version) |
At that screen, you can carve up the order to be re-issued as a VI3 license. In my first pass at this, it didn't work correctly. The licensing portal states that it can take up to 30 minutes to reflect in the VI3 licensing inventory. A quick chat-based support option got it corrected for me in no time.
Once the licensing is visible in the VI3 portal, you can proceed and add the license file to your VI3 installation as you have done with direct purchases in the past.
Have a downgrade note? Share your comments here or by e-mail.
Posted by Rick Vanover on 10/28/2009 at 12:47 PM2 comments
Converting systems with large amounts of storage has always been a tricky task. Frequently, there are limited amounts of quiet time to convert these systems. This can be made even more difficult when a raw device mapping (RDM) cannot be used. Here is a trick that will open up your playbook a little.
When converting a physical machine in VMware environments, it is generally good practice to resize the volumes to an appropriate geometry. This usually means making application or data volumes smaller to avoid disk space consumed for free guest operating system space on the virtualization storage system. When using VMware vCenter Converter, you have the option to size down the disks, but that makes the conversion process use a file-level copy -- much slower. If the disks retain their size or are made larger, a block-level clone of the source disk will be used. The latter configuration is noticeably faster; my experience puts it at around a factor of twice as fast.
The issue with the faster process is that there is potentially large amounts of wasted space on the SAN. This can be solved by vSphere's Enhanced Storage VMotion. The enhancements in vSphere allow you to perform a storage migration task from a fully allocated virtual disk to a thin-provisioned disk. This means that once the workload is converted, you can perform this task to reclaim that wasted space. This is a timesaver, as the Storage VMotion task is done online with the virtual machine. The only caveat is that there needs to be enough space on the storage platform to support all of the pieces in motion, which may add up if there is a lot of free space involved.
Have you come across that trick or do you have any others for large systems? If so, please share your comments here or send me an e-mail.
Posted by Rick Vanover on 10/27/2009 at 12:47 PM4 comments
For organizations considering
ESXi for mainstream hypervisor usage, one important consideration is disk partitioning. One of my peers in the industry, Jason Boche (rhymes with hockey) states it best
on his blog as saying that partitioning is a lost art on ESXi.
Recently, I was rebuilding my primary ESXi test environment and I landed on Jason's material and can't agree more with what he has said. Partitioning is one of the virtualization debates that can quickly become a religious issue, like deciding on a storage protocol or whether or not to virtualize vCenter. Jason goes into the details of what partitioning is done based on various disk geometry configurations, and to Jason's point -- we don't yet know if they are adequate. Changes to ESX partitioning are the norm, but without a service console in ESXi the biggest offender is removed from the partitioning criteria.
An important additional configuration point is the default VMFS volume created on the local partition. For organizations that want to utilize the free ESXi hypervisor and want to use local storage, a little forward thought on logical drive configuration can protect the VMFS volumes entirely from any partitioning with ESXi. Ideally, shared storage would be used in conjunction with the free hypervisor to remove this potential partitioning issue that can cause burdensome copy operations or backup operations. Be sure to check out this How-To document explaining how ESXi works with shared storage configurations. For (unmanaged) free ESXi installations, try to put VMFS volumes on different disk arrays than the ones that contain the ESXi partitioning. This can allow you to protect the VMFS volume from a reinstallation if necessary. VMFS volumes are forward and backward compatible within ESX and ESXi versions 3 and newer.
A lot of the local partitioning issues as well as potentially wasted space can be removed if a USB flash media boot configuration is appropriate for your ESXi installation. Here is a VMware Communities post on how to create a USB bootable flash drive for ESXi. This configuration of course is unsupported but may be adequate for a lesser tier of virtualization or a development environment.
Storage management is always one of the biggest planning points for virtual environments. Do you have any pointers for managing storage with the free ESXi hypervisor? If so, please share your comments below or send me an e-mail .
Posted by Rick Vanover on 10/22/2009 at 12:47 PM1 comments
Virtualization is one of those areas that you need to stay sharp, as things will change on you very quickly: getting information on how to do certain tasks, what new features are now supported and a myriad of other points that compose the larger virtualization landscape. Even with all of the quick moving news from blogs and Twitter feeds, there still is value for in-person events that can provide a transfer of knowledge.
There are potentially two events in my future that I am getting excited about. The first is Gestalt IT Field Day. This is a new-concept event inspired by an HP-sponsored event, StorageWorks Tech Day. This is basically a blogger roundtable where we kick the tires on various technologies and tell you what we think. The Gestalt IT Field Day will be different in that it is not directly organized by the companies whose products are represented. I hope to attend this and provide a good virtualization slant, which I will share here of course. The current makeup of the event will provide a good perspective for end-to-end virtualization administration and management, as well as hitting on other top IT topics.
The next event that I'm excited about is something you can attend: TechMentor Orlando 2010. I had the honor last year to present three virtualization sessions at that event. The content is still being mapped out, yet I am getting excited. Should I get to present again, it will be a great time meeting and exchanging with attendees.
There is a place for events like VMworld, which is an event I enjoy. But there are plenty of events that are more cozy and accessible, an area where TechMentor excels.
Other resources exist, such as Cloudcamp, the VMware Forum series and local community activities. I hope to see you around at events like this to round out your virtualization and IT inventory.
Posted by Rick Vanover on 10/20/2009 at 12:47 PM6 comments
Like many others, I have benefited from virtualization in my professional experiences. I have advanced my career to new levels as well as tackled challenges that I would not have thought possible without virtualization. There have been many technologies that have fundamentally impacted my technology practice, but none more than virtualization.
The Windows Server platform is a strong contender for the biggest impact technology in my career thus far. I've worked with Windows Server products since I started my career, and it has shaped parts of my career throughout. Virtualization, however, fundamentally changes everything. Just like the technology infrastructure is fundamentally impacted with virtualization, a career can be impacted in the same way.
Virtualization allows us to on focus things such as cost savings for your technology infrastructure, which will give you the ear of management and those above in almost any organization. To be well-rounded and effective with virtualization, you will also have to be aware of the costs and associated savings of virtualization. This is a natural step in career development, and virtualization makes it an easy transition.
Another point that virtualization has developed my career is that I've had to become more of a storage and network expert than I was before. Virtualization's broad reach in the datacenter pulls these key areas together as part of a comprehensive infrastructure strategy. From a career development perspective, managing storage and networking are critical skills to add to one's repertoire.
Virtualization also develops one's ability to manage topics such as licensing, critical hardware decisions, and disaster recovery. These topics are directly relevant to executive-level decisions, and developing virtualization skills allows us to succeed in these areas.
How has virtualization impacted your career? Share your comments below.
Posted by Rick Vanover on 10/15/2009 at 12:47 PM1 comments
Avaya has announced that the
Aura System Platform will be available as a virtualized solution. In a way, this is a big deal for those of us who have had issues with across-the-board virtualization. If you have provided infrastructure services to an organization with a call center or a large telecommunications footprint, you know that virtualization adoption has been rather painful in this space.
In my virtualization practice, if a vendor doesn't support virtualization you don't even try to go there. It is very painful to pass on virtualizing a system that you know will do fine simply because a blanket vendor support statement requires a physical server.
I am mixed on the news related to the Avaya Aura System Platform. I don't use the product, but like the direction this space is going. My issue is that I see this as black box virtualization. Barring no issues, telecom vendors would provide servers and other components as simply black boxes. However, customers need access to provide various levels of support to critical systems that support call centers or line of business revenue streams. Further, these solutions are computers and are subject to compliance requirements among other things. The end result is that even though these systems are purpose-built and may be provided by a vendor, infrastructure and application teams have to deal with these like they would many other systems.
The Aura solution is based on Xen virtualization and uses a specific configuration of standard server equipment that has been certified by Avaya. This means you cannot role it into your larger virtualized environment of Citrix or any other virtualization platform. This is part of my dislike of black box virtualization, as this appeals to me less than dedicated hardware for the applications. This is another layer of abstraction that may complicate the customer’s troubleshooting responsibilities, especially with Xen-based hypervisors.
To be fair, it is difficult to make broad support statements for systems like this. Prior experience as a software solutions provider has told me that it is nearly impossible to make blanket supportability statements when the customer gets involved in architecting solutions for critical applications.
While this is a step in the good direction for one of the more difficult areas to virtualize, I'm not too excited about this news. Share your comments below or drop me an e-mail.
Posted by Rick Vanover on 10/13/2009 at 12:47 PM5 comments
It may seem that performing a physical to virtual (P2V) conversion is a boring task in the current virtualization landscape. In some recent tasks, I have had some conversions give me some bizarre behavior that remind me that you can never stop learning in this space. Here are a couple points I learned recently that may help you in any conversions that you may undertake.
Network issues: When it comes to conversions, you do not always have the time to investigate the source system outside of the operating system. Older physical systems may be on older network segments that are configured differently or, more frequently, on slower (100 MB) segments. Take some time to get the system on a quicker network if possible, and clean up anything that may inhibit access to your virtualization platform to perform the conversion. I had a recent situation where certain drive letters on the physical system were not enumerated in the conversion until the network was configured correctly.
Best tools: Using the right tool will aid the conversion process. I am fan of the vCenter Converter Standalone for VMware conversions. I prefer it because it has some additional service management and synchronization options, as well as the ability to go to the unmanaged ESXi platform as a destination. As a side note, Microsoft released a new version of the Microsoft Disk2Vhd tool. With all conversion tools, it is a good idea to always use the most current version.
Cross-zone conversion trick: You can get stuck when trying to convert a physical system on a network that has virtual machines but is on a network that is not accessible to ESX hosts or vCenter. In this situation and where security policies permit, you can enable a service console IP address on the network that has the virtual machines. You can then run the conversion task directly to this temporary service console to allow the conversion to communicate with the physical system and the hypervisor directly. This would not generally work with the plug-in conversion tool -- again, the standalone tool may work better.
You can never stop learning about conversions, and surely there will be more lessons to come. If you have had any tricks on P2V conversions that have come around recently, please share them with your fellow readers here.
Posted by Rick Vanover on 10/08/2009 at 12:47 PM1 comments
Monday was a busy day for virtualization. I was happy to see a lot of products receive updates, and
vCenter Site Recovery Manager 4 delivers the big news from VMware. Site Recovery Manager (SRM) is a managed failover from one vCenter cloud to another site's inventory of hosts and storage.
SRM is a boon for many situations, as it allows this failover to occur much quicker under the right circumstances. I've mentioned both the PlateSpin Forge device and Vizioncore's continuous protection options for vConverter as solutions for remote data center protection of workloads, but these don't offer as broad of a reach as SRM. The differences revolve primarily around the fact that SRM will literally fail the whole data center over versus failing over individual workloads.
SRM version 4 introduces the following new features:
-
Support for vSphere: This is a natural progression that allows the current version of vCenter (version 4) to be supported with SRM. This can allow many organizations to proceed with the upgrade to vSphere with this support.
- Support for NFS-based storage: Fibre channel or iSCSI systems were previously the only supported storage options. The NetApp community will rejoice in this news.
- N:1 failover: This is a big point, as SRM can now provide managed failover for a number of hot sites to a single cold site or single shared recovery site. Previously, each managed site needed a cold site.
SRM still misses the distinction of being the one-size-fits-all solution for site failover in my opinion. The first shortcoming is the magical arrow on the whiteboard that goes from one datacenter to another for the storage replication. SRM doesn't manage the storage replication for the virtual environment.
The other shortcoming (likely related to my first point) is that SRM does not have a managed fail-back option. This means that if your disaster recovery site becomes fully production-class, you may have to stay there for a while.
SRM still is a pretty good offering for the scope of its protection, and the new features will be a welcome addition to the installations that use the feature.
Are you using SRM or going about it another way? Drop me a note or write a comment below.
Posted by Rick Vanover on 10/06/2009 at 12:47 PM1 comments
Current versions of VMware Tools as well as VI3 installations are now able to use Windows Perfmon to gain access to selected CPU and RAM counters provided by VMware Tools. I came across this information reading this
VPivot blog post.
With the new versions of VMware Tools (or the standalone update for older versions of Tools), two new performance objects appear: VM Processor and VM Memory. These have access to host stats for the VM, and make it incredibly easy to centrally collect information. Some of the new counters include:
VM Processor
- %Processor time
- Effective VM speed in MHz
- Host processor speed in MHz
- Limit in MHz
- Reservation in MHz
- Shares
VM Memory
- Memory active in MB
- Memory ballooned in MB
- Memory limit in MB
- Memory mapped in MB
- Memory overhead in MB
- Memory reservation in MB
- Memory shared in MB
- Memory shared Saved in MB
- Memory shares
- Memory swapped in MB
- Memory used in MB
A sample of the new counters are shown in Fig. 1.
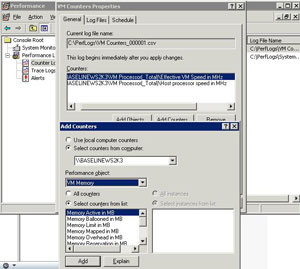 |
| Figure 1. VMware Tools can now provide data to Windows performance counters, making an easy connection between the virtual platform performance and the OS. (Click image to view larger
version.) |
I think this is great, but don't make it too public. I don't want to have to explain shares and swapping to application owners who may still have the perception that virtualization has a cost to running their applications.
Have you used this yet? Send me an e-mail with any points you have learned to [email protected] or drop a comment below.
Posted by Rick Vanover on 10/01/2009 at 12:47 PM8 comments
In July, Veeam introduced a new free tool called
Veeam Business View. Business View does, well, just that. It represents the infrastructure in organizational ways that you decide that makes sense for your business. In our tech-heavy world of aggregated infrastructure and platform architecture, it makes sense to see it in a way that the rest of the organization can find useful.
Business View natively plugs in to vCenter Server (vSphere and VMware Infrastructure 3) to inventory your virtualized environment. Key features of Veeam Business View include the ability to work with three categorization elements: Business Unit, Department and Purpose. Within these categories, there can be many different items for each level. These are then used among other things to apply rules that match the infrastructure to friendly organization elements. Additional custom attributes can be applied to this "meta-information" that may make sense for certain installations. Additionally, there are approval mechanisms and export functionality as part of the product.
I am the cheapest virtualization person I know, so that means that I am a sucker for the free tools. I just started tinkering with it, and you may want to do the same. The main point that I want to explore here is building an organization of your virtualized environment without being required to follow the host, cluster and resource pool infrastructure that defines the technology. Business View is currently free and integrates with other Veeam and nworks products with more planned as it matures.
Have you been using Business View? Share a comment below on your experiences.
Posted by Rick Vanover on 09/28/2009 at 12:47 PM7 comments