In-Depth
Front-Line Expert Boils Cloud Incident Response Down to Three Core Practices
Veteran cloud architect Joey D'Antoni believes that rapid cloud incident response depends less on any single tool than on groundwork done before an outage hits.
He also believes teams should treat incidents as chances to strengthen their systems and processes, not just as crises to survive. In discussing post-incident reviews, Joey emphasized blameless retrospectives, actionable follow-up items and measuring whether the same problems keep happening, all with the goal of making the environment more resilient after each failure.
 "Every incident is a gift disguised as a bad day."
"Every incident is a gift disguised as a bad day."
Joey D'Antoni, Principal Cloud Architect at 3Cloud
Joey shared his expertise in his session today at Virtualization & Cloud Review's Cloud Resilience Summit: The Essentials of Detection, Response & Recovery, being made available for replay thanks to the sponsor, Rubrik.
A regular presenter at our series of tech-education webcasts, Joey, a principal cloud architect at 3Cloud, focused his session on three key takeaways: invest in observability and automation before you need them; make sure clarity of roles and communication is in place before an incident begins; and treat every incident as a learning opportunity. Those points provide a clear through-line for the session and tied together much of his earlier discussion about detection, containment, communications and post-incident review.
Invest in Observability and Automation Before You Need Them
 [Click on image for larger view.] Detection & Observability (source: Joey D'Antoni.
[Click on image for larger view.] Detection & Observability (source: Joey D'Antoni.
Joey said cloud teams need visibility across logs, metrics and traces, and they need those signals correlated well enough to surface real problems without overwhelming responders with noise. He pointed to centralized logging, distributed tracing and synthetic monitoring as part of that visibility layer, saying teams should not be learning about service degradation from customers first.
He paired that message with a practical case for automation. In his telling, automation is not about removing people from the process, but about handling the earliest, most repetitive response steps fast enough to buy humans time for judgment calls. He described using event-driven automation to trigger first-response actions, isolate compromised resources and use feature flags or traffic controls to limit immediate user impact. "Automation should really kind of handle the first 90 seconds of compromises so that humans can spend their energy on on judgment calls," he said.
Clarity of Roles and Communication Saves More Time than Any Tool
 [Click on image for larger view.] Communication Under Pressure (source: Joey D'Antoni.
[Click on image for larger view.] Communication Under Pressure (source: Joey D'Antoni.
Joey also emphasized the human side of incident response, arguing that severity levels should align to business impact, not just technical thresholds. He recommended an incident commander model in which one person owns the overall process while other roles handle communications and technical response. The key point was that those responsibilities should be defined before an incident starts, not improvised during one.
Communication was a major part of that argument. Joey said teams should clearly separate the people fixing the problem from the people updating stakeholders, and he warned against long stretches of silence that erode trust internally and externally. "You need clear separation between people who are working on the problem and people who are communicating about it," he said. Later, in summarizing the broader lesson, he said clearly defined roles and communications "is going to save you more time than any single tool purchase."
Every Incident Is a Learning Opportunity -- Treat It that Way
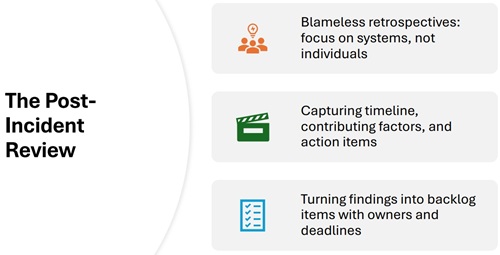 [Click on image for larger view.] Post-Incident Review (source: Joey D'Antoni.
[Click on image for larger view.] Post-Incident Review (source: Joey D'Antoni.
The third major point focused on what happens after the immediate crisis has passed. Joey described post-incident review as a blameless process centered on systems and process failures rather than individual fault. He said teams should document the timeline, contributing factors and follow-up actions, then turn those findings into backlog items with owners and deadlines.
He connected that learning process to measurement, arguing that teams should track more than recovery time alone. Along with Mean Time to Recover, he called out Mean Time to Detect and Mean Time to Communicate, along with recurrence rate and action-item completion rate, as metrics that can show whether the organization is actually improving. If the same kind of incident keeps happening, he said, that is a sign the postmortem process is not doing enough. His closing formulation captured the broader message: "every incident is a gift disguised as a bad day."
Across the session, Joey returned to the same idea from several angles: cloud resilience is built before the emergency. Better observability can shorten detection time, automation can speed early containment, defined roles can reduce confusion, and disciplined post-incident review can keep teams from repeating the same mistakes. Framed that way, the session was less about one-off tactics than about building a repeatable operating model for cloud incident response.
And More
And, although replays are fine -- this was just today, after all, so timeliness isn't an issue -- there are benefits of attending such summits and webcasts from Virtualization & Cloud Review and sister sites in person. Paramount among these is the ability to ask questions of the presenters, a rare chance to get one-on-one advice from bona fide subject matter experts (not to mention the chance to win free prizes -- in this case $10 Starbucks gift cards, which were awarded to the first 150 attendees during a session by sponsor Rubrik, a leader in cloud data management and enterprise data protection which also presented at the summit). Joey also share much more expert knowledge in the event and answered specific questions as only a front-line practitioner can.
With all that in mind, here are some upcoming summits and webcasts coming up from our parent company in the next month or so:
About the Author
David Ramel is an editor and writer at Converge 360.