News
Google Cloud Next '26: Gemini Enterprise Agent Platform Leads AI-Centric News
Google Cloud Next '26, ending today, was largely framed around what Google calls the agentic enterprise, but for virtualization, cloud infrastructure and operations teams, the most relevant announcements centered on the systems needed to run, connect, secure and govern those agents at scale.
The event's infrastructure news included a new enterprise agent platform, two eighth-generation Tensor Processing Unit chips, new AI networking fabric, cross-cloud compute and connectivity updates, and an Agentic Data Cloud architecture. Google said the announcements are aimed at production agent deployments that require compute, networking, storage, data access, security controls and operational visibility across Google Cloud, other clouds, on-premises systems and distributed environments.
Gemini Enterprise Agent Platform Replaces Standalone Vertex AI Roadmap
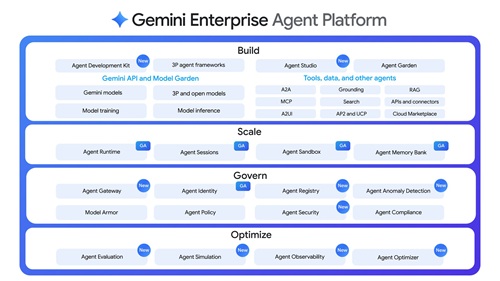
One of the central announcements was Gemini Enterprise Agent Platform, which Google described as a comprehensive platform to build, scale, govern and optimize agents. Google said the platform is the evolution of Vertex AI and that future Vertex AI services and roadmap evolutions will be delivered through Agent Platform rather than as a standalone service.
 [Click on image for larger view.] Gemini Enterprise Agent Platform Overview (source: Google).
[Click on image for larger view.] Gemini Enterprise Agent Platform Overview (source: Google).
For cloud teams, the importance is less about chatbot functionality and more about lifecycle control. Google said the platform combines model selection, model building and agent building with new capabilities for agent integration, DevOps, orchestration and security. It provides first-class access to more than 200 models through Model Garden, including Google's Gemini 3.1 Pro, Gemini 3.1 Flash Image, Lyria 3 and Gemma 4, along with third-party models such as Anthropic Claude Opus, Sonnet and Haiku.
Google organized the platform around four areas: build, scale, govern and optimize. New features include Agent Studio, an upgraded Agent Development Kit, Agent Runtime, Agent-to-Agent Orchestration, Agent Gateway, Agent Identity, Agent Registry, Agent Observability, Agent Simulation and Agent Evaluation. The operational relevance is that Google is treating agents as managed enterprise workloads, with identity, policy enforcement, observability, evaluation and runtime controls rather than one-off AI applications.
TPU 8t and TPU 8i Split Training and Inference
Google also announced eighth-generation TPUs with two specialized chips: TPU 8t for training and TPU 8i for inference. Google said both chips are coming soon and are designed for workloads ranging from model training and agent development to large-scale inference.
TPU 8t is aimed at compute-intensive training. Google said one TPU 8t superpod scales to 9,600 chips and 2 petabytes of shared high-bandwidth memory, delivers 121 ExaFlops of compute, and provides nearly three times the compute performance per pod compared with the previous generation. Google also said TPU 8t integrates 10 times faster storage access and, when combined with Virgo Network, JAX and Pathways software, can provide near-linear scaling for up to 1 million chips in a single logical cluster.
TPU 8i is aimed at low-latency inference. Google said it pairs 288 GB of high-bandwidth memory with 384 MB of on-chip SRAM, triples on-chip SRAM compared with the previous generation, doubles Interconnect bandwidth to 19.2 Tb/s for Mixture of Expert models, and uses a new on-chip Collectives Acceleration Engine to reduce on-chip latency by up to five times. Google said TPU 8i delivers 80 percent better performance-per-dollar compared with the previous generation. Both TPU 8t and TPU 8i run on Google's Axion Arm-based CPU host, support native JAX, MaxText, PyTorch, SGLang and vLLM, and offer bare-metal access.
Virgo Network Targets AI Cluster Scale
Google introduced Virgo Network, a scale-out AI data center fabric that underpins AI Hypercomputer. Google said Virgo Network is based on a campus-as-a-computer approach and is designed to address scale, bandwidth, synchronized bursts and latency requirements in AI training and serving workloads.
The architecture separates network functions into three layers: a scale-up domain for accelerator communication within a pod, a scale-out accelerator fabric for east-west RDMA communication across pods, and the Jupiter front-end network for north-south access to storage and general-purpose compute. Google said Virgo Network uses high-radix switches, a flat two-layer non-blocking topology and a multi-planar design with independent control domains.
Google said Virgo Network can link 134,000 TPU 8t chips with up to 47 petabits per second of non-blocking bi-sectional bandwidth in a single fabric. It also said the network provides up to four times the bandwidth per TPU 8t accelerator compared with the previous generation and 40 percent lower unloaded fabric latency for TPUs compared with the previous generation. For infrastructure teams, the announcement is notable because Google is positioning network fabric as a first-order AI infrastructure component, not a background data center layer.
Cross-Cloud Infrastructure Adds Compute, GKE and Sovereignty Features
In its cross-cloud infrastructure announcement, Google grouped updates into fluid compute, secure cross-cloud connectivity, a unified data layer and digital sovereignty. The fluid compute updates include new C4N and M4N VM families and GKE Agent Sandbox.
Google said C4N VMs process up to 95 million packets per second and are intended for demanding workloads such as security appliances, streaming media and open source databases. Google said M4N with Hyperdisk Extreme targets large data I/O from agents, analytics and mission-critical databases, provides 26.57 GB of RAM per vCPU and reduces Oracle workload total cost of ownership by more than 20 percent compared with leading hyperscale clouds.
For Kubernetes users, GKE Agent Sandbox may be the most directly relevant item. Google said it uses trusted gVisor isolation, launches up to 300 sandboxes per second per cluster, and delivers up to 30 percent better price-performance than competitors when running AI agents on GKE Agent Sandbox with Google Axion N4A. The same cross-cloud infrastructure announcement also included Agent Gateway for agent traffic governance, Cloud Network Insights for hybrid and multicloud observability, enhanced Cloud Next Generation Firewall and Cloud Armor, Smart Storage, Knowledge Catalog, Confidential External Key Management, and Gemini on Google Distributed Cloud.
Agentic Data Cloud Focuses on Data Access Across Clouds
Google's Agentic Data Cloud announcement focused on giving agents governed access to data and business context. Google said the architecture is built around three innovation areas: a universal context engine, agentic-first practitioner experiences and an AI-native cross-cloud lakehouse.
The universal context component includes Knowledge Catalog, which Google said evolved from Dataplex Universal Catalog and maps business meaning across an enterprise data estate. Google said Knowledge Catalog aggregates context across Google Cloud and partner data platforms, continuously enriches data using usage logs and profiling, and supports access-control-aware search so agents retrieve only authorized assets. Google said Knowledge Catalog also powers Deep Research Agent in preview.
For developers and data practitioners, Google announced Data Agent Kit in preview. Google said it is a portable suite of skills, tools, extensions and plugins that works in environments including VS Code, Gemini CLI, Codex and Claude Code. It includes Data Engineering Agent, which is generally available; Data Science Agent, which is generally available; and Database Observability Agent, which is in preview.
The cross-cloud lakehouse portion includes Cross-Cloud Interconnect integration into the data plane, Apache Iceberg REST Catalog, bi-directional federation in preview, Spanner Omni in preview, and Lakehouse federation for AlloyDB in preview. Google also announced Lightning Engine for Apache Spark with up to two times the price-performance over what it called the proprietary market alternative, Managed Lustre with up to 10 terabytes per second of throughput, an in-memory tier for Bigtable with sub-millisecond read latency, and BigQuery fluid scaling that Google said lowers costs by up to 34 percent on average for autoscaling workloads.
About the Author
David Ramel is an editor and writer at Converge 360.