In-Depth
AI on a Raspberry Pi: Part 3 -- Testing Different LLMs
In a previous article, I downloaded, installed, and ran queries on an LLM running on a Raspberry Pi 500+. The results were somewhat disappointing; it took 17 minutes to get a response to a relatively simple task.
I was hoping the problem was specific to the LLM I chose (Qwen2.5:3B) rather than to running LLMs on the Pi computer.
In this article, I will walk you through my testing of running three queries across four LLMs designed specifically for lower-powered systems.
The LLMs
After doing a bit of research, I settled on these small LLMs: gemma2:2b, tinyllama, deepseek-r1:1.5b. I will also be running my test on the qwen2.5:3B LLM.
Below is an AI-generated (it only seemed fitting) explanation of each of these models.
Qwen2.5:3B is a 3-billion-parameter open-weight large language model from Alibaba Cloud's Qwen family, designed to deliver strong performance while remaining efficient enough for local and edge deployments. It offers solid reasoning, coding, and multilingual capabilities, supports long context windows, and performs well across general NLP tasks. Its balance of performance and hardware efficiency makes it popular for lightweight AI assistants, RAG pipelines, and developer experimentation.
Gemma2:2B is Google's compact, open-source model built using the same research foundations as Gemini, optimized for speed, safety, and efficiency. Trained on trillions of tokens, it delivers strong conversational ability, reasoning, and summarization performance despite its small size, making it well-suited for local inference, edge AI, and mobile deployments. Gemma2:2B is widely used for chatbots, personal assistants, and embedded AI applications.
TinyLlama is a highly efficient 1.1-billion-parameter open-source model based on the LLaMA architecture, trained on roughly one trillion tokens. Despite its small footprint, it delivers surprisingly strong performance across everyday NLP tasks and is designed explicitly for memory-constrained environments such as laptops, embedded systems, and edge devices. TinyLlama is widely adopted for experimentation, fine-tuning, and ultra-lightweight AI applications.
DeepSeek-R1:1.5B is a compact reasoning-focused model distilled from DeepSeek's much larger R1 architecture, optimized for math, coding, and logical problem-solving. Using reinforcement learning and chain-of-thought training, it delivers strong reasoning accuracy despite its small size, often rivaling much larger models in structured tasks. This makes it well-suited for efficient on-device inference, developer tools, and edge-based AI systems that require strong reasoning with minimal hardware overhead.
The Test Framework
I wanted to run the same three tests on all the LLMs above, so I asked ChatGPT to generate the following.
Create a bash shell script that uses ollama to use these three separate prompts.
What is the capital of Oregon in the US
Create the HTML code to display "Hello World" in blue
Create a table showing the population of the western United States in each decade for the past century
Use the following LLMs: qwen2.5:3b, gemma2:2b, tinyllama, deepseek-r1:1.5b
The output from the prompt should be combined into a single file, separated by a timestamp, the prompt name, and the LLM. Include the metrics gathered by the --verbose switch.
Write the test name, the LLM, and when it starts on the screen before each test.
Add a summary of all the tests run at the end of the output file and terminal.
The script it came up with was spot-on on the first try.
Testing the LLMs
While the tests were running, htop showed that all four cores were running at close to 100% and that the models were fully loaded in RAM.
 [Click on image for larger view.]
[Click on image for larger view.]
It took over four hours for the test to complete.
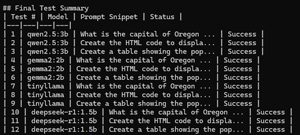
Below is an example of the summary that my script produced at the end of its run.
 [Click on image for larger view.]
[Click on image for larger view.]
Tom's Tip: When I redirected the Ollama test output to a file, it also captured the progress bar, making the file unusually long and requiring me to do additional processing to clean it up.
Test Results
To get more accurate results, I ran my testing script 4 times. The test results were remarkable and surprisingly similar across runs.
I parsed the results for the Model, Prompt, total duration, prompt eval count, and eval count in the output
The CSV includes the following columns for each test run:
Total Duration: Total time from request to final response.
Model: The specific LLM model used (e.g., qwen2.5:3b, gemma2:2b, tinyllama).
Prompt: The request sent to the model.
Prompt Eval Rate (tokens/s): Speed at which the model processed the initial prompt.
Eval Rate (tokens/s): Speed at which the model generated the response.
Token Counts: Both for prompt evaluation and generation.
| Eval Duration |
Timestamp |
Model |
Prompt |
Total Duration |
Prompt Eval Count |
Prompt Eval Duration |
Prompt Eval Rate (tokens/s) |
Eval Count |
Eval Rate (tokens/s) |
| 44.486132836s |
9:57 |
qwen2.5:3b |
What is the capital of Oregon |
3m0.65372041s |
38 |
2m10.629976988s |
0.29 |
12 |
0.27 |
| 12m47.100908125s |
10:00 |
qwen2.5:3b |
Create the HTML code |
15m10.182060799s |
41 |
2m20.854158394s |
0.29 |
190 |
0.25 |
| 36m16.893849544s |
10:16 |
qwen2.5:3b |
Create a table showing the population |
39m0.765595505s |
47 |
2m41.462823835s |
0.29 |
536 |
0.25 |
|
| 50.334451423s |
10:55 |
gemma2:2b |
What is the capital of Oregon |
1m46.382549638s |
18 |
50.82797777s |
0.35 |
14 |
0.28 |
| 25m55.467348278s |
10:57 |
gemma2:2b |
Create the HTML code |
26m57.625723761s |
21 |
59.10743502s |
0.36 |
404 |
0.26 |
| 27m3.066937641s |
11:24 |
gemma2:2b |
Create a table showing the population |
28m21.858087846s |
27 |
1m15.642572856s |
0.36 |
421 |
0.26 |
|
| 1m3.566012499s |
11:53 |
tinyllama |
What is the capital of Oregon |
2m4.727333424s |
45 |
59.446481156s |
0.76 |
43 |
0.68 |
| 2m15.37832839s |
11:55 |
tinyllama |
Create the HTML code |
3m16.842345627s |
46 |
1m0.742617115s |
0.76 |
92 |
0.68 |
| 5m25.11354992s |
11:58 |
tinyllama |
Create a table showing the population |
6m37.166146541s |
54 |
1m11.289387849s |
0.76 |
219 |
0.67 |
|
| 21m49.101635602s |
12:05 |
deepseek-r1:1.5b |
What is the capital of Oregon |
22m13.329812792s |
12 |
19.74381966s |
0.61 |
631 |
0.48 |
| 51m5.806863697s |
12:27 |
deepseek-r1:1.5b |
Create the HTML code |
51m33.92355425s |
15 |
24.57675424s |
0.61 |
1472 |
0.48 |
| 1h57m52.560761505s |
13:19 |
deepseek-r1:1.5b |
Create a table showing the population |
1h58m32.258181613s |
21 |
34.219045517s |
0.61 |
3370 |
0.48 |
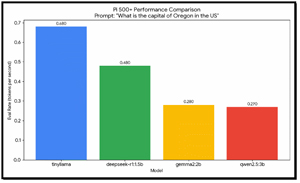
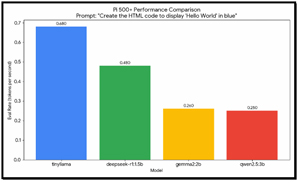
I graphed the output to show the differences between the LLMs clearly.
 [Click on image for larger view.]
[Click on image for larger view.]
 [Click on image for larger view.]
[Click on image for larger view.]
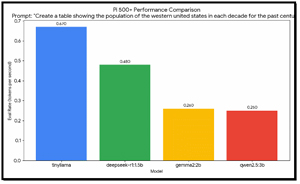 [Click on image for larger view.]
[Click on image for larger view.]
After examining the output, I came up with these takeaways.
TinyLlama consistently led across all three prompts; it was the fastest, achieving speeds of 0.67-0.68 tok/s. Its smaller size makes it the most "efficient" for the Pi's ARM architecture.
Despite being a reasoning model, deepseek-r1 maintained a steady 0.48 tok/s. While faster than the 2b and 3b models, its total completion time was often higher due to the high volume of "thinking" tokens it generates.
There is a clear performance drop-off as model size increases. Gemma2 (2b) and Qwen2.5 (3b) both hovered around 0.25--0.28 tok/s. On this hardware, a 3b model is roughly 2.5x slower than a 1b model.
Analysis
These results highlight clear trade-offs between model size, reasoning depth, and execution efficiency across the four LLMs. The smallest models, Qwen2.5:3B, Gemma2:2B, and TinyLlama, consistently delivered much faster response times and lower token generation counts, making them well-suited for lightweight tasks such as fact retrieval and simple code generation. Among them, TinyLlama showed high efficiency, often completing tasks in just a few minutes with moderate token usage, while Qwen2.5:3B provided a strong balance between speed and output quality.
In contrast, DeepSeek-R1:1.5B, although technically smaller in parameter count, exhibited dramatically longer runtimes and much higher token generation, reflecting its reasoning-focused architecture and chain-of-thought processing, which significantly increases inference time. This behavior makes DeepSeek-R1 better suited for tasks that require deep logical reasoning and step-by-step analysis, but less efficient for routine queries.
Overall, these results illustrate that model selection should be driven by workload type: compact general-purpose models excel in responsiveness and efficiency, while reasoning-optimized models trade speed for deeper analytical capability, highlighting the importance of matching model architecture to application requirements.
Diving deeper, I aggregated the data to get a clear picture of the results
This chart shows the average time each model takes across all three prompts.
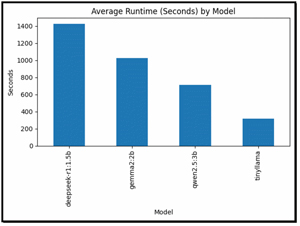 [Click on image for larger view.]
[Click on image for larger view.]
Average Token Output by Model
This chart compares the average number of tokens generated by each model.
DeepSeek-R1 produced far more tokens, confirming its heavy reliance on chain-of-thought reasoning. The smaller models were far more concise, improving speed and efficiency.
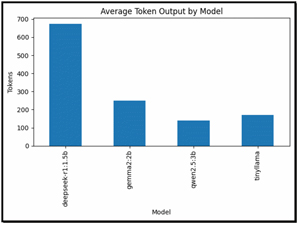 [Click on image for larger view.]
[Click on image for larger view.]
Compute Efficiency (Seconds per Token)
This is arguably the most revealing chart as it shows how much time each model spends per generated token. TinyLlama was the most efficient model. Qwen2.5:3B provided a strong balance of speed and output quality. DeepSeek-R1 was extremely inefficient in terms of throughput, which is expected given its focus on reasoning.
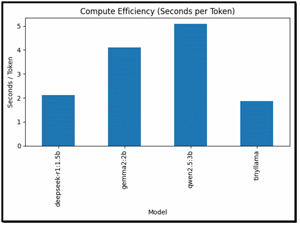 [Click on image for larger view.]
[Click on image for larger view.]
These charts show that architecture and inference strategy dominate real-world performance more than raw parameter count. TinyLlama and Qwen2.5:3B are excellent for local inference, edge AI, RAG pipelines, and fast interactive workloads, while DeepSeek-R1 is best reserved for deep analytical tasks where reasoning quality outweighs latency concerns.
Tom's Tip: For reference, I asked ChatGPT and Gemini these same three questions, and the results came back correct and within seconds.
Final Analysis
On the Pi ARM-based system, I saw sub-1 token-per-second (tok/s) speeds for almost all models, making them essentially unusable for real-time AI work.
The Raspberry Pi 500+ is impressive for a desktop, but LLM inference depends on memory bandwidth and AVX/vector instructions; the Cortex-A76 lacks the specialized instructions (such as AVX-512) found in modern Intel/AMD chips that Ollama uses to accelerate math-intensive inference.
While 16GB is plenty of capacity to load these models, the CPU's speed in pulling model weights from RAM is a bottleneck.
The "Eval Rate" is where the hardware's struggles are most visible. A "natural reading speed" is typically considered 5--8 tok/s, which none of these models could deliver while running on the Pi.
Model
|
Avg. Eval Rate (Pi 500+)
|
Total Duration (HTML Task)
|
TinyLlama
|
0.67 -- 0.68 tok/s
|
3m 16s
|
DeepSeek-R1 (1.5b)
|
0.48 tok/s
|
51m 33s
|
Gemma2 (2b)
|
0.26 -- 0.28 tok/s
|
26m 57s
|
Qwen2.5 (3b)
|
0.25 -- 0.27 tok/s
|
15m 10s
|
TinyLlama was the only model that stayed above 0.6 tok/s. This is because its architecture is significantly smaller and more "efficient" for low-power ARM cores.
DeepSeek-R1's total duration for the population table that it generated was 1 hour and 58 minutes. This highlights a major issue: reasoning models generate "thought" tokens before the final answer. At 0.48 tok/s, generating 3,370 tokens takes an eternity. On this hardware, a non-reasoning model of the same size would finish much faster simply by generating fewer tokens.
Gemma2 vs. Qwen2.5
Both models are virtually tied in speed (~0.26 tok/s). This suggests I hit a "hard floor" of performance, where the memory throughput completely saturates the CPU's ability to process the transformer blocks.
On the Pi 500+, these models are better suited to asynchronous tasks (e.g., a background script that processes one request every 30 minutes) than to a chatbot.
Final Analysis
I am not giving up on my hopes of running LLMs locally, so in my next article, I will run the same tests on an x64-based system to see how it performs and whether it can be used to run LLMs locally.